AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTMemory Subsystem: TinyMemBench
We doublechecked our LMBench numbers with Andrei's custom memory latency test.
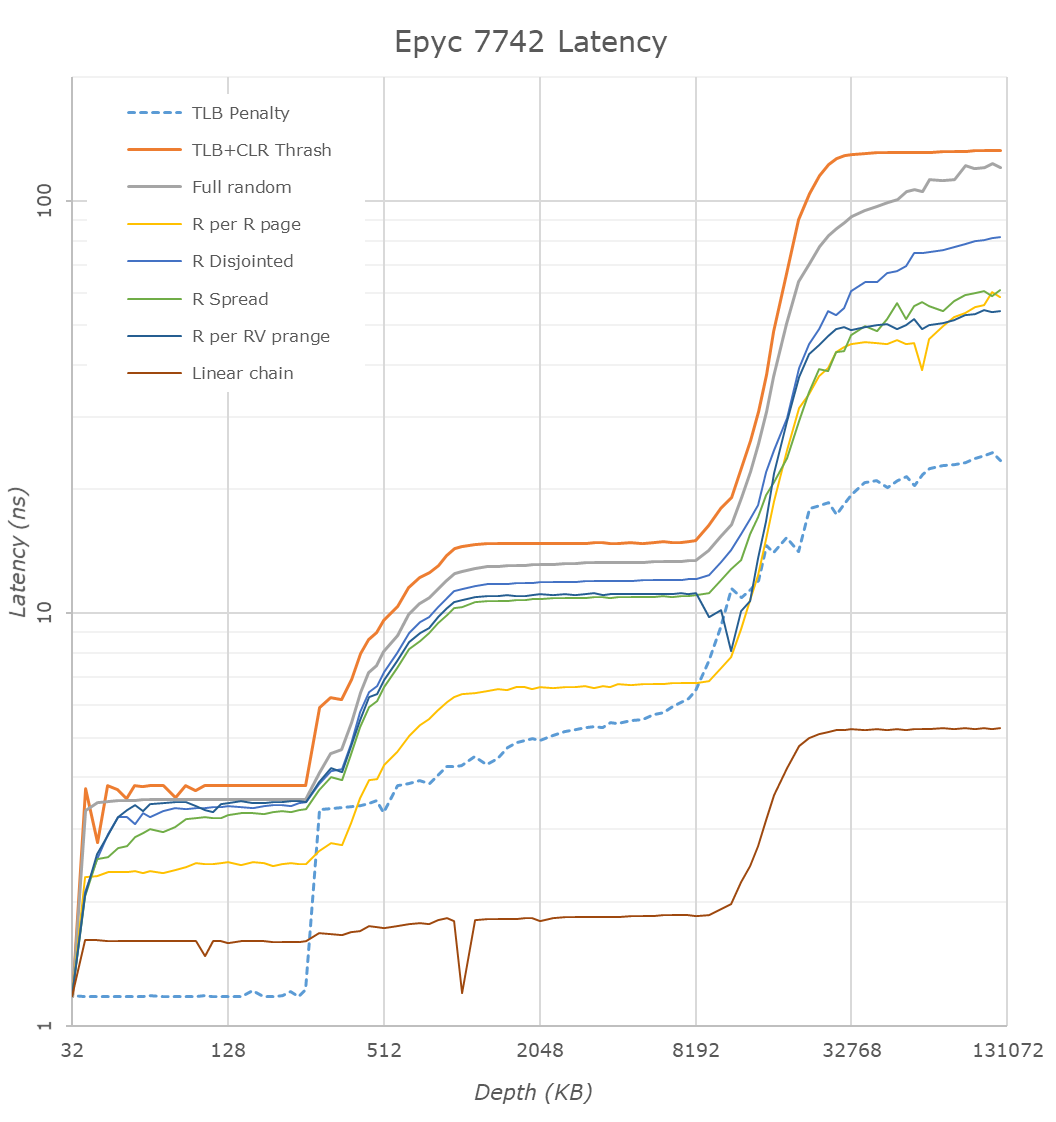
The latency tool also measures bandwidth and it became clear than once we move beyond 16 MB, DRAM is accessed. When Andrei compared with our Ryzen 9 3900x numbers, he noted:
The prefetchers on the Rome platform don't look nearly as aggressive as on the Ryzen unit on the L2 and L3
It would appear that parts of the prefetchers are adjusted for Rome compared to Ryzen 3000. In effect, the prefetchers are less aggressive than on the consumer parts, and we believe that AMD has made this choice by the fact that quite a few applications (Java and HPC) suffer a bit if the prefetchers take up too much bandwidth. By making the prefetchers less aggressive in Rome, it could aid performance in those tests.
While we could not retest all our servers with Andrei's memory latency test by the deadline (see the "Murphy's Law" section on page 5), we turned to our open source TinyMemBench benchmark results. The source was compiled for x86 with GCC and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
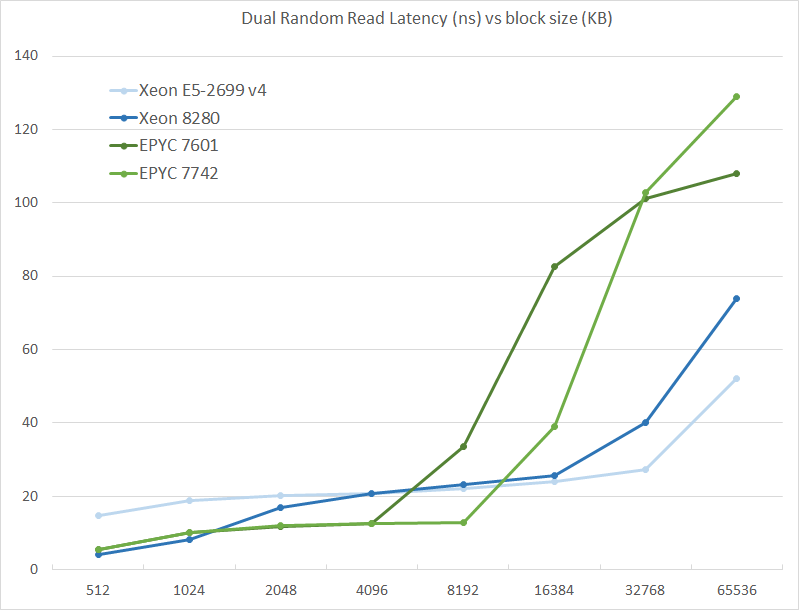
The graph shows how the larger L3 cache of the EPYC 7742 resulting in a much lower latency between 4 and 16 MB, compared to the EPYC 7601. The L3 cache inside the CCX is also very fast (2-8 MB) compared to Intel's Mesh (8280) and Ring topologies (E5).
However, once we access more than 16 MB, Intel has a clear advantage due to the slower but much larger shared L3 cache. When we tested the new EPYC CPUs in a more advanced NUMA setting (with NPS = 4 setting, meaning 4 nodes per socket), latency at 64 MB lowered from 129 to 119. We quote AMD's engineering:
In NPS4, the NUMA domains are reported to software in such a way as it chiplets always access the near (2 channels) DRAM. In NPS1 the 8ch are hardware-interleaved and there is more latency to get to further ones. It varies by pairs of DRAM channels, with the furthest one being ~20-25ns (depending on the various speeds) further away than the nearest. Generally, the latencies are +~6-8ns, +~8-10ns, +~20-25ns in pairs of channels vs the physically nearest ones."
So that also explains why AMD states that select workloads achieve better performance with NPS = 4.








180 Comments
View All Comments
wrkingclass_hero - Sunday, August 11, 2019 - link
What does AMD have to do to get a Gold or Platinum recommendation?oRAirwolf - Thursday, August 15, 2019 - link
This is a good questionimaskar - Sunday, August 11, 2019 - link
Single thread performance is very important for those who lives in cloud. A quick example: suppose I provision 2 core/4gig vm (this is of course hyperthreads). And on AWS I have a choice - m5 and m5a, where AMD is cheaper. What do I sacrifice? Not really throughput, because you don't run your prod workloads at 100% CPU. But there is the latency. If those cores clocked lower, I would get the same amount of responses, but slower. And since in microservice world you have a chain of calls, you get this decrease 10 times. Is it worth it?That was the case for 1st gen EPYC. Would 2nd gen have latency parity?
notashill - Sunday, August 11, 2019 - link
It's hard to say until the cloud instances actually launch.The current m5a instances are using a custom SKU which is clocked at 2.5GHz max boost.
Rome's IPC is ~15% higher and clock speeds are all around higher so single threaded performance should be quite a bit better, but ultimately the exact numbers will depend on which SKUs the cloud vendors decide to use and how high they clock.
duploxxx - Tuesday, August 13, 2019 - link
did you actually ever work with hypervisors?there are other things than raw clock speed.... its all about scheduling and when there are more cores / socket available the scheduling is more relaxed, less ready time..... EPYC generation 1 is already awesome for hypervisor way better choice than most Intel counter parts for sure if you look at socket cost... but than again I am probably talking to a typical retard ****
JoeBraga - Wednesday, August 14, 2019 - link
Can you Explain better? But the license isn't bought by the quantity of coresor Per socket?imaskar - Wednesday, August 14, 2019 - link
He probably talks about VmWare, which is licensed per socket, not per core. So with EPYC gen2 you need twice less licenses for the same cloud capacity (assuming cores are equal).JoeBraga - Wednesday, August 14, 2019 - link
Now I understoodimaskar - Wednesday, August 14, 2019 - link
Rather than calling others retards, you could first dig a little deeper into an issue. No, I don't work with hypervisors directly, I'm from the other side. I write software and I want good latency (not insane one like for HFT, but still a good one). Because for throughput we could just spin one more instance. You can't buy latency horizontally.I'm not taking numbers out of the blue. There is a benchmark for AMD instances vs Intel instances on AWS. I'm not sure if we are allowed to post links to other resources here. Put this string into Google and you will surely find it: "A Look At The AMD EPYC Performance On The Amazon EC2 Cloud". Despite this article being very enthusiastic about those instances, you can really see that per core performance on Intel is better, meaning better latencies for web apps.
I will probably write my own set of benchmarks, because that one seems to completely ignore web servers. I am very enthusiastic about AMD instances, but they are definitely not a no-brainer.
quadibloc - Tuesday, August 13, 2019 - link
The new Ryzen chips compete well with what Intel is currently producing. But while they doubled AVX 2 support, so as to match what Intel has, Ice Lake will double that - as has been known for some time. So if this is what AMD thought would be competitive with Ice Lake, as Forrest Norrod said, AMD was not trying hard enough - and they're just lucky Ice Lake was late. AMD's position relative to Intel with its previous generations of Ryzens seems to be the limit of their ambitions. Combine that with Intel reacting to its current issues, and it looks to me that AMD will have to rethink some aspects of its strategy to avoid Intel being ahead when it comes time for next year's chips from both companies.