AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTHPC: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX and AVX-512.
The NAMD binary is compiled with Intel ICC, optimized for AVX and mostly single preciscion floating point (fp32). For our testing, we used the "NAMD_2.13_Linux-x86_64-multicore" binary. At some point we want to use this test with AOCC or similar AMD optimized binary, but were unable to do so for this review.
We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
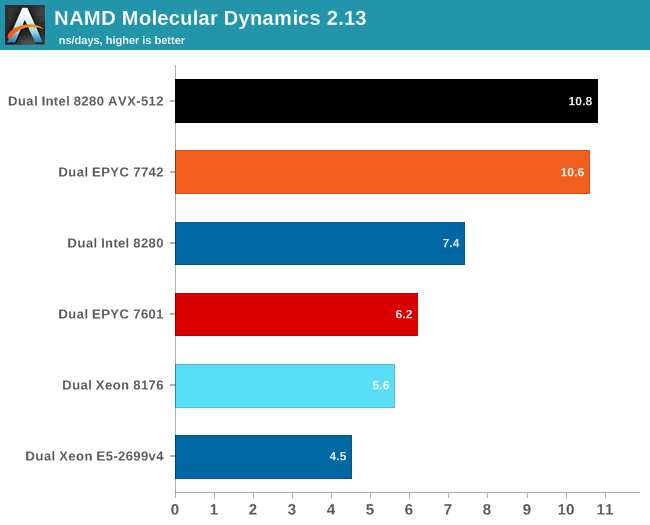
Even without AVX-512 and optimal AVX optimization, the 7742 is already offering the same kind of performance as an ultra optimized Intel binary on top of the top of the line Xeon 8280. When do an apples-to-apples comparison, the EPYC 7742 is no less than 43% faster.
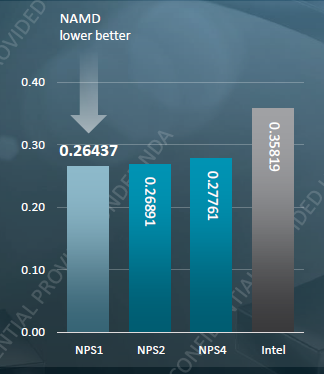
AMD claims a 35% advantage (3.8 ns/days vs 2.8 ns/days) and that seems to confirm our own preliminary benchmarking.








180 Comments
View All Comments
bobdvb - Thursday, August 8, 2019 - link
I think a four compute node, 2U, dual processor Epyc Rome combined with Mellanox ConnextX-6 VPI, should be quite frisky for HPC.JohanAnandtech - Sunday, August 11, 2019 - link
"One thing I wish they would have done is added quad socket support. "Really? That is extremely small niche market with very demanding customers. Why would you expect AMD to put so much effort in an essentially dead end market?
KingE - Wednesday, August 7, 2019 - link
> While standalone compression and decompression are not real world benchmarks (at least as far as servers go), servers have to perform these tasks as part of a larger role (e.g. database compression, website optimization).Containerized apps are usually delivered via large, compressed filesystem layers. For latency sensitive-applications, e.g. scale-from-zero serverless, single- and lightly-threaded decompression performance is a larger-than-expected consideration.
RSAUser - Thursday, August 8, 2019 - link
Usually the decompression overhead is minimal there.KingE - Thursday, August 8, 2019 - link
Sure, if you can amortize it over the life of a container, or can benefit from cached pulls. Otherwise, as is fairly common in an event-based 'serverless' architecture, it's a significant contributor to long-tail latency.Thud2 - Wednesday, August 7, 2019 - link
Will socket-to-socket IF link bandwidth management allow for better dual GPU performance?wabash9000 - Thursday, August 8, 2019 - link
"The city may be built on seven hills, but Rome's 8x8-core chiplet design is a truly cultural phenomenon of the semiconductor industry."The city of Rome was actually built on 8 hills, even their celebration of the 7 hills had 8 listed. Something got confused and it was actually 8 hills. Search "QI: Series O Overseas" on youtube
Ian Cutress - Thursday, August 8, 2019 - link
That episode is consequently where my onowdge about the 7 Hills / 8 Hills comes from.abufrejoval - Sunday, August 11, 2019 - link
sic transit gloria mundi... cum youtube non scolae discimus...I learned in Latin class, first of four foreign languages I learned in school (but I know that doesn't impress anyone from Belgium with three domestic ones :-)
ZolaIII - Thursday, August 8, 2019 - link
Seams that EPYC 7702P will be a absolute workstation killer deal. Hopefully AMD won't screw up with motherboard's this time around.