AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
AMD Zen 2 Microarchitecture Overview
The Quick Analysis
At AMD’s Tech Day, on hand was Fellow and Chief Architect Mike Clark to go through the changes. Mike is a great engineer to talk to, although what always amuses me (for any company, not just AMD) is that engineers that talk about the latest products coming to market are already working one, two, or three generations ahead at the company. Mike remarked that it took him a while to think back to the specific Zen+ to Zen 2 changes, while his mind internally is already several generations down the line.
An interesting element to Zen 2 is around the intention. Initially Zen 2 was merely going to be a die shrink of Zen+, going from 12nm down to 7nm, similar to what we used to see with Intel in its tick-tock model for the initial part of the century. However, based on internal analysis and the time frame for 7nm, it was decided that Zen 2 would be used as a platform for better performance, taking advantage of 7nm in multiple ways rather than just redesigning the same layout on a new process node. As a result of the adjustments, AMD is promoting a +15% IPC improvement for Zen 2 over Zen+.
When it comes down to the exact changes in the microarchitecture, what we’re fundamentally looking at is still a similar floorplan to what Zen looks like. Zen 2 is a family member of the Zen family, and not a complete redesign or different paradigm on how to process x86 – as will other architectures that have familial updates, Zen 2 affords a more efficient core and a wider core, allowing better instruction throughput.
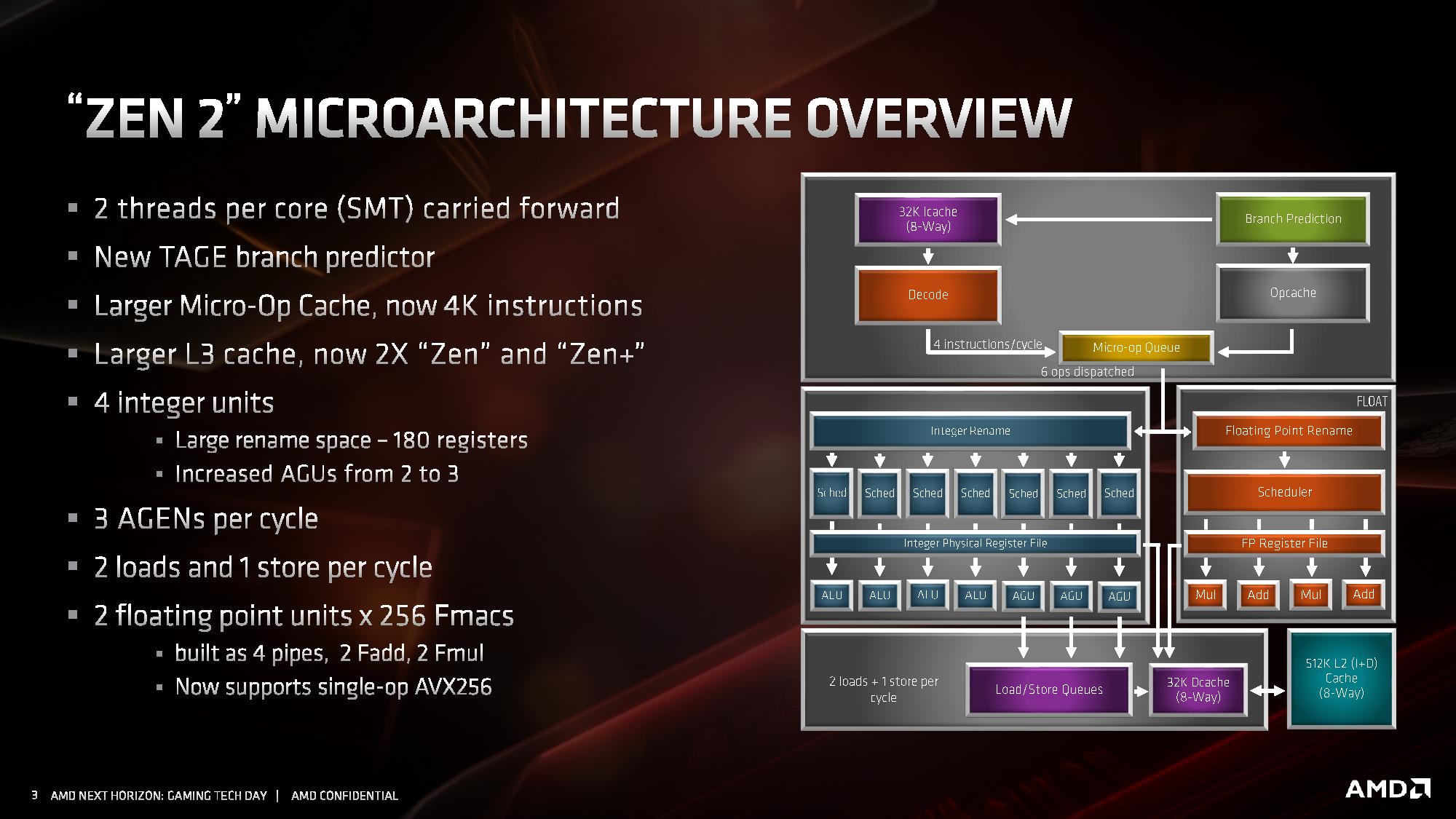
At a high level, the core looks very much the same. Highlights of the Zen 2 design include a different L2 branch predictor known as a TAGE predictor, a doubling of the micro-op cache, a doubling of the L3 cache, an increase in integer resources, an increase in load/store resources, and support for single-operation AVX-256 (or AVX2). AMD has stated that there is no frequency penalty for AVX2, based on its energy aware frequency platform.
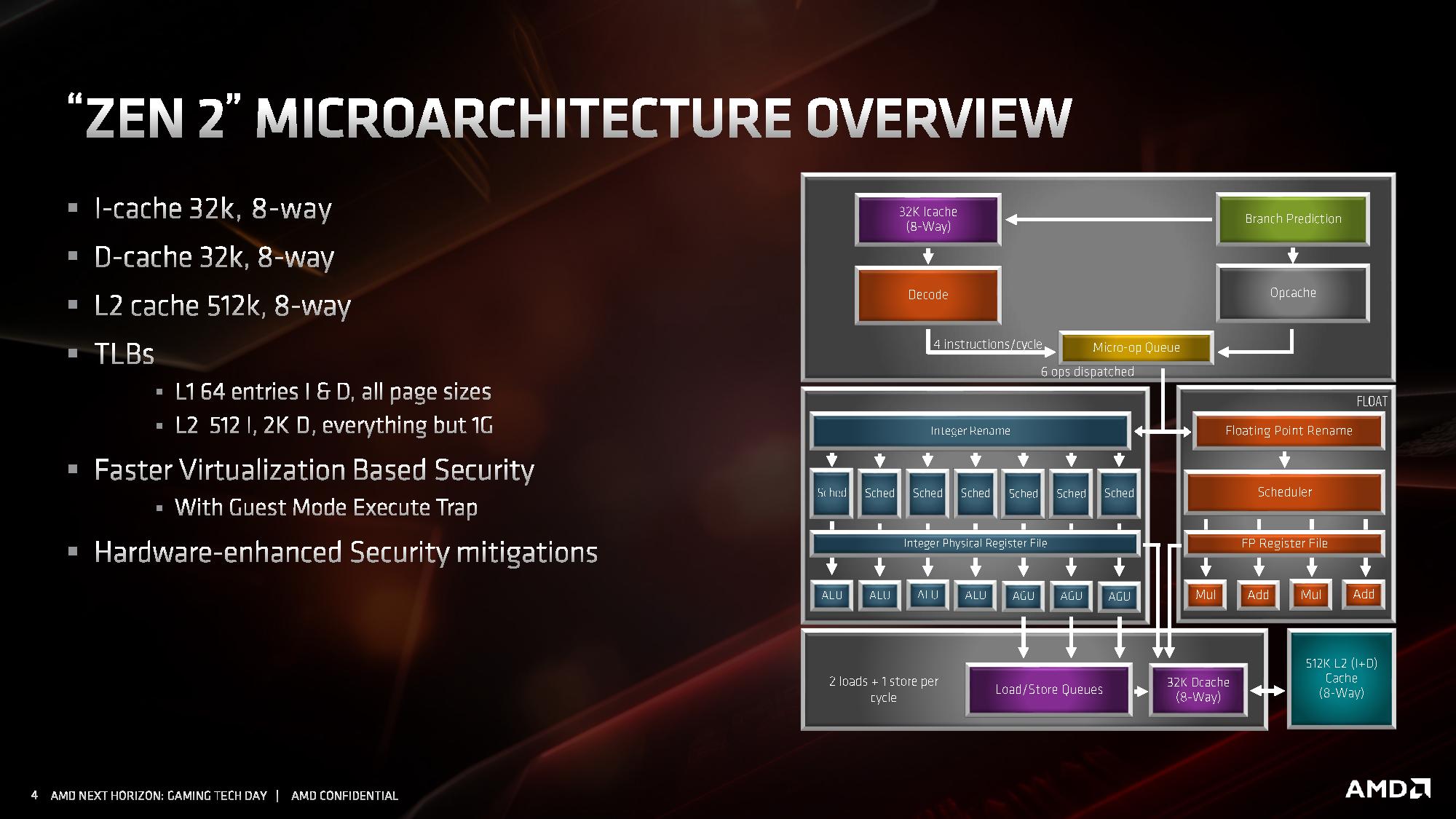
AMD has also made adjustments to the cache system, the most notable being for the L1 instruction cache, which has been halved to 32 kB, but associativity has doubled. This change was made for important reasons, which we’ll go into over the next pages. The L1 data cache and L2 caches are unchanged, however the translation lookaside buffers (TLBs) have increased support. AMD also states that it has added deeper virtualization support with respect to security, helping enable features further down the pipeline. As mentioned previously in this article, there are also security hardening updates.
For the quick analysis, it’s easy to tell that doubling the micro-op cache is going to offer a significant improvement to IPC in a number of scenarios, and combine that with an increase in load/store resources is going to help more instructions get pushed through. The double L3 cache is going to help in specific workloads, as would the AVX2 single-op support, but the improved branch predictor is also going to showcase raw performance uplift. All-in-all, for an on-paper analysis, AMD’s +15% IPC improvement seems like a very reasonable number to promote.
Over the next few pages, we’ll go deeper into how the microarchitecture has changed.








216 Comments
View All Comments
GreenReaper - Wednesday, June 12, 2019 - link
The last you heard? It says clearly on page 6 that there is "single-op" AVX 256, and on page 9 explicitly that the width has been increased to 256 bits:https://www.anandtech.com/show/14525/amd-zen-2-mic...
https://www.anandtech.com/show/14525/amd-zen-2-mic...
To be honest, I don't mind how it's implemented as long as the real-world performance is there at a reasonable price and power budget. It'll be interesting to see the difference in benchmarks.
arashi - Wednesday, June 12, 2019 - link
Don't expect too much cognitive abilities regarding AMD from HStewart, his pay from big blue depends on his misinformation disguised as misunderstanding.Qasar - Thursday, June 13, 2019 - link
HA ! so that explains it..... the more misinformation and misunderstanding he spreads.. the more he gets paid.......HStewart - Thursday, June 13, 2019 - link
I don't get paid for any of this - I just not extremely heavily AMD bias like a lot of people here. It just really interesting to me when Intel release information about new Ice Lake processor with 2 load / s store processor that with in a a couple days here bla bla about Zen+++. Just because 7nm does not mean they change much.Maybe AMD did change it 256 width - and not dual 128, they should be AVX 2 has been that way for a long time and Ice Lake is now 512. Maybe by time of Zen 4 or Zen+++++ it will be AVX 512 support.
Korguz - Thursday, June 13, 2019 - link
no.. but it is known.. you are heavily intel bias..whats zen +++++++++ ????
x 86-512 ??????
but you are usually the one spreading misinformation about amd...
" and support for single-operation AVX-256 (or AVX2). AMD has stated that there is no frequency penalty for AVX2 " " AMD has increased the execution unit width from 128-bit to 256-bit, allowing for single-cycle AVX2 calculations, rather than cracking the calculation into two instructions and two cycles. This is enhanced by giving 256-bit loads and stores, so the FMA units can be continuously fed. "
HStewart - Thursday, June 13, 2019 - link
Zen+++++ was my joke as every AMD fan jokes about Intel 10+++ Just get over itx-86 512 - is likely not going to happen, it just to make sure people are not confusing vector processing bits with cpu bits 64 bit is what most os uses now. for last decade or so
Intel has been using 256 AVX 2 since day one, the earlier version of AMD chips on only had two combine 128 bit - did they fix this with Zen 2 - this is of course different that AVX 512. which standard in in all Ice Lake and higher cpus and older Xeon's.
Qasar - Thursday, June 13, 2019 - link
sorry HStewart... but even sone intel fans are making fun of the 14++++++ and it would be funny.. if you were making fun of the process node.. not the architeCture..."
x-86 512 - is likely not going to happen, it just to make sure people are not confusing vector processing bits with cpu bits 64 bit is what most os uses now. for last decade or so " that makes NO sense...
HStewart - Thursday, June 13, 2019 - link
One more thing I stay away from AMD unless there are one that bias against Intel like spreading misinformation that AVX 512 is misleading. and it really not 512 surely they do not have proof of that.AVX 512 is not the same as x86-512, I seriously doubt we will ever need that that but then at time people didn't think we need x86-64 - I remember original day of 8088,. no body thought we needed more 64meg AVX-512 is for vectors which is totally different.
just4U - Thursday, June 13, 2019 - link
I always have a higher end Intel setup and normally a AMD setup as well.. plus I build a fair amount of setups on both. No bias here except maybe.. wanting AMD to be competitive. The news that dropped over the past month was the biggest for AMD in over a decade HS.. If you can't even acknowledge that (even grudgingly..) then geez.. I dunno.This has been awesome news for the industry and will put intel on their toes to do better. Be happy about it.
Xyler94 - Monday, June 17, 2019 - link
HStewart, please. You don't stay away from AMD at all. You take ANY opportunity to try and make Intel look better than AMD.There was an article, it was Windows on ARM. You somehow managed to make a post about Intel winning over AMD. Don't spew that BS. People don't hate Intel as much as you make them out to be, they don't like you glorifying Intel.