Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTRecurrent Neural Networks: LSTM
Our loyal readers know that we love real-world enterprise benchmarks. So in our quest for better benchmarks and better data, Pieter Bovijn, the head of research at the MCT IT Bachelor (dutch), turned a real-world AI model into a benchmark.
The input of the model is time series data, which is used to make predictions on how the time series will behave in the future. As this is a typical sequence prediction problem, we used a Long Short-Term Memory (LSTM) network as neural network. A type of RNN, LSTM selectively "remembers" patterns over a certain duration of time.
LSTM however come with the disadvantage that they are a lot more bandwidth intensive. We quote a recent paper on the topic:
LSTMs exhibit quite inefficient memory access pattern when executed on mobile GPUs due to the redundant data movements and limited off-chip bandwidth.
So we were very curious about how the LSTM network would behave. After all, our server Xeons have ample bandwidth, with a massive 38.5 MB of L3 and six channels of DDR4-2666/2933 (128-141 GB/s per socket). We run this test with 50 GB of data, and train the model for 5 epochs.
Of course, you have the make the most of the available AVX/AVX2/AVX512 SIMD power. That is why we tested with 3 different setups
- We used out of the box TensorFlow with conda
- We tested with the Intel optimized TensorFlow from PyPi repo
- We optimized from source using Bazel. This allowed us to use the very latest version of TensorFlow.
The results are very interesting.
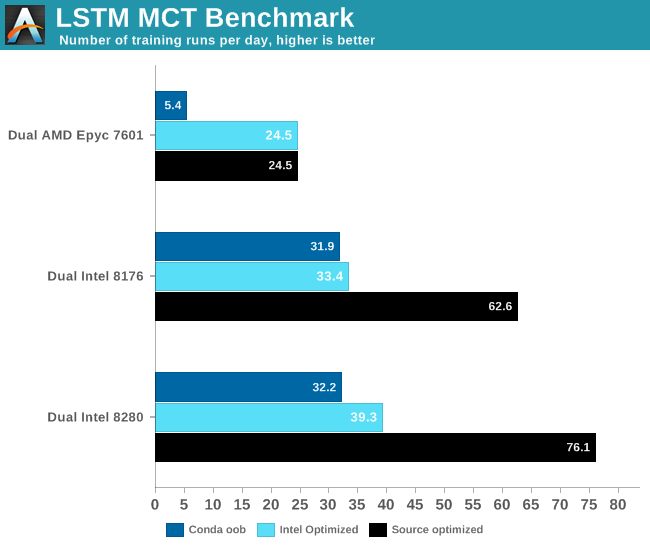
The most intensive TensorFlow applications are typically run on GPUs, so extra care must be taken when you test on a CPU. AMD's Zen core only has two 128-bit FMACs, and is limited to (256-bit) AVX2. Intel's high-end Xeons have two 256-bit FMACs and one 512-bit FMAC. In other words, on paper Intel's Xeon can deliver four times more FLOPs per clock cycle than AMD. But only if the software is right. Intel has been working intensively with Google to optimize TensorFlow for Intel new Xeons out of necessity: it has to offer a credible alternative in those situations where an NVIDIA Tesla is simply too expensive. Meanwhile, AMD hopes that ROCm catches on and that in the future software engineers run TensorFlow on a Radeon Pro.
Of course, the big question is how this compares to a GPU. Let us see how our NVIDIA Titan RTX deals with this workload.
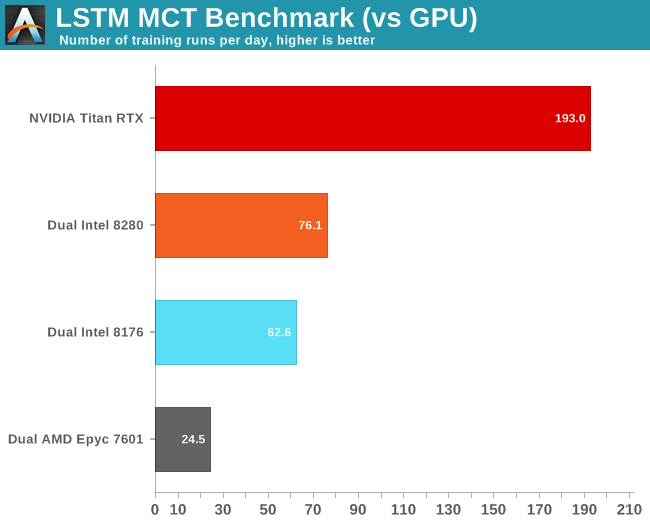
First of all, we noticed that FP16 did not make much of a difference. Secondly, we were quite amazed that our Titan RTX was less than 3 times faster than our dual Xeon setup.
Investigating further with NVIDIA's System Management Interface (SMI), we found out that GPU did run at a its highest turbo speed: 1.9 GHz, which is higher than the expected 1.775 GHz. Meanwhile utilization dropped to 40% from time to time.
Ultimately this is another example of how real-world applications behave differently from benchmarks, and how important software optimization is. If we would have just used conda, the results above would be very different. Using the right optimized software made the application run 2 to 6 times faster. Also, this another data point that proves that CNNs might be one of the best use cases for GPUs. You should use a GPU to decrease training times of complex LSTMs of course. Still, this kind of neural network is a bit more tricky - you cannot simply add more GPUs to further decrease training time.








56 Comments
View All Comments
Bp_968 - Tuesday, July 30, 2019 - link
Oh no, not 8 million, 8 *billion* (for the 8180 xeon), and 19.2 *billion* for the last gen AMD 32 core epyc! I don't think they have released much info on the new epyc yet buy its safe to assume its going to be 36-40 billion! (I dont know how many transistors are used in the I/O controller).And like you said, the connections are crazy! The xeon has a 5903 BGA connection so it doesn't even socket, its soldered to the board.
ozzuneoj86 - Sunday, August 4, 2019 - link
Doh! Thanks for correcting the typo!Yes, 8 BILLION... it's incredible! It's even more difficult to fathom that these things, with billions of "things" in such a small area are nowhere near as complex or versatile as a similarly sized living organism.
s.yu - Sunday, August 4, 2019 - link
Well the current magnetic storage is far from the storage density of DNA, in this sense.FunBunny2 - Monday, July 29, 2019 - link
"As a single SQL query is nowhere near as parallel as Neural Networks – in many cases they are 100% sequential "hogwash. SQL, or rather the RM which it purports to implement, is embarrassingly parallel; these are set operations which care not a fig for order. the folks who write SQL engines, OTOH, are still stuck in C land. with SSD seq processing so much faster than HDD, app developers are reverting to 60s tape processing methods. good for them.
bobhumplick - Tuesday, July 30, 2019 - link
so cpus will become more gpu like and gpus will become more cpu like. you got your avx in my cuda core. no, you got your cuda core in my avx......mmmmmmbobhumplick - Tuesday, July 30, 2019 - link
intel need to get those gpus out quickAmiba Gelos - Tuesday, July 30, 2019 - link
LSTM in 2019?At least try GRU or transformer instead.
LSTM is notorious for its non-parallelizablity, skewing the result toward cpu.
Rudde - Tuesday, July 30, 2019 - link
I believe that's why they benchmarked LSTM. They benchmarked gpu stronghold CNNs to show great gpu performance and benchmarked LSTM to show great cpu performance.Amiba Gelos - Tuesday, July 30, 2019 - link
Recommendation pipeline already demonstrates the necessity of good cpus for ML.Imho benching LSTM to showcase cpu perf is misleading. It is slow, performing equally or worse than alts, and got replaced by transformer and cnn in NMT and NLP.
Heck why not wavenet? That's real world app.
I bet cpu would perform even "better" lol.
facetimeforpcappp - Tuesday, July 30, 2019 - link
A welcome will show up on their screen which they have to acknowledge to make a call.So there you go; Mac to PC, PC to iPhone, iPad to PC or PC to iPod, the alternatives are various, you need to pick one that suits your needs. Facetime has magnificent video calling quality than other best video calling applications.
https://facetimeforpcapp.com/