The Samsung 983 ZET (Z-NAND) SSD Review: How Fast Can Flash Memory Get?
by Billy Tallis on February 19, 2019 8:00 AM ESTMixed Random Performance
Real-world storage workloads usually aren't pure reads or writes but a mix of both. It is completely impractical to test and graph the full range of possible mixed I/O workloads—varying the proportion of reads vs writes, sequential vs random and differing block sizes leads to far too many configurations. Instead, we're going to focus on just a few scenarios that are most commonly referred to by vendors, when they provide a mixed I/O performance specification at all. We tested a range of 4kB random read/write mixes at queue depths of 32 and 128. This gives us a good picture of the maximum throughput these drives can sustain for mixed random I/O, but in many cases the queue depth will be far higher than necessary, so we can't draw meaningful conclusions about latency from this test. As with our tests of pure random reads or writes, we are using 32 (or 128) threads each issuing one read or write request at a time. This spreads the work over many CPU cores, and for NVMe drives it also spreads the I/O across the drive's several queues.
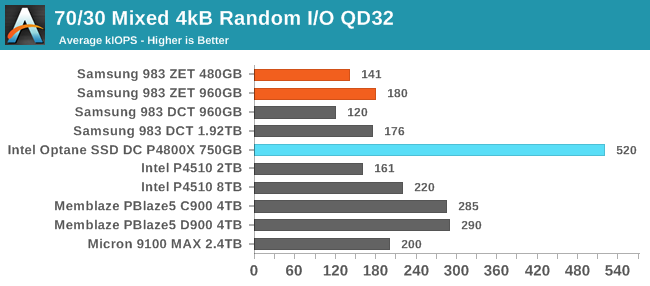
The full range of read/write mixes is graphed below, but we'll primarily focus on the 70% read, 30% write case that is a fairly common stand-in for moderately read-heavy mixed workloads.
 |
|||||||||
| Queue Depth 32 | Queue Depth 128 | ||||||||
On the 70/30 mixed random IO tests, the Samsung 983 ZET provides similar performance to a TLC-based 983 DCT of twice the capacity. This leaves both Samsung drives as among the slowest drives in this batch, because the other flash-based drives are mostly higher-capacity models using controllers with higher channel counts than the Samsung Phoenix. The Samsung drives perform about the same at QD128 as at QD32, while some of the larger drives take advantage of the higher queue depth to almost catch up to the Intel Optane SSD.
 |
|||||||||
| QD32 Power Efficiency in MB/s/W | QD32 Average Power in W | ||||||||
| QD128 Power Efficiency in MB/s/W | QD128 Average Power in W | ||||||||
The TLC-based 1.92TB 983 DCT uses the least power on these mixed IO tests and it ends up with some of the best efficiency scores among the flash-based SSDs, about 60% of the performance per Watt that the Intel Optane SSD provides. The two 983 ZET drives use a bit more power than the 983 DCT, so they end up with fairly ordinary efficiency scores that are outclassed by the largest TLC drives in the QD128 test.
 |
|||||||||
| QD32 | |||||||||
| QD128 | |||||||||
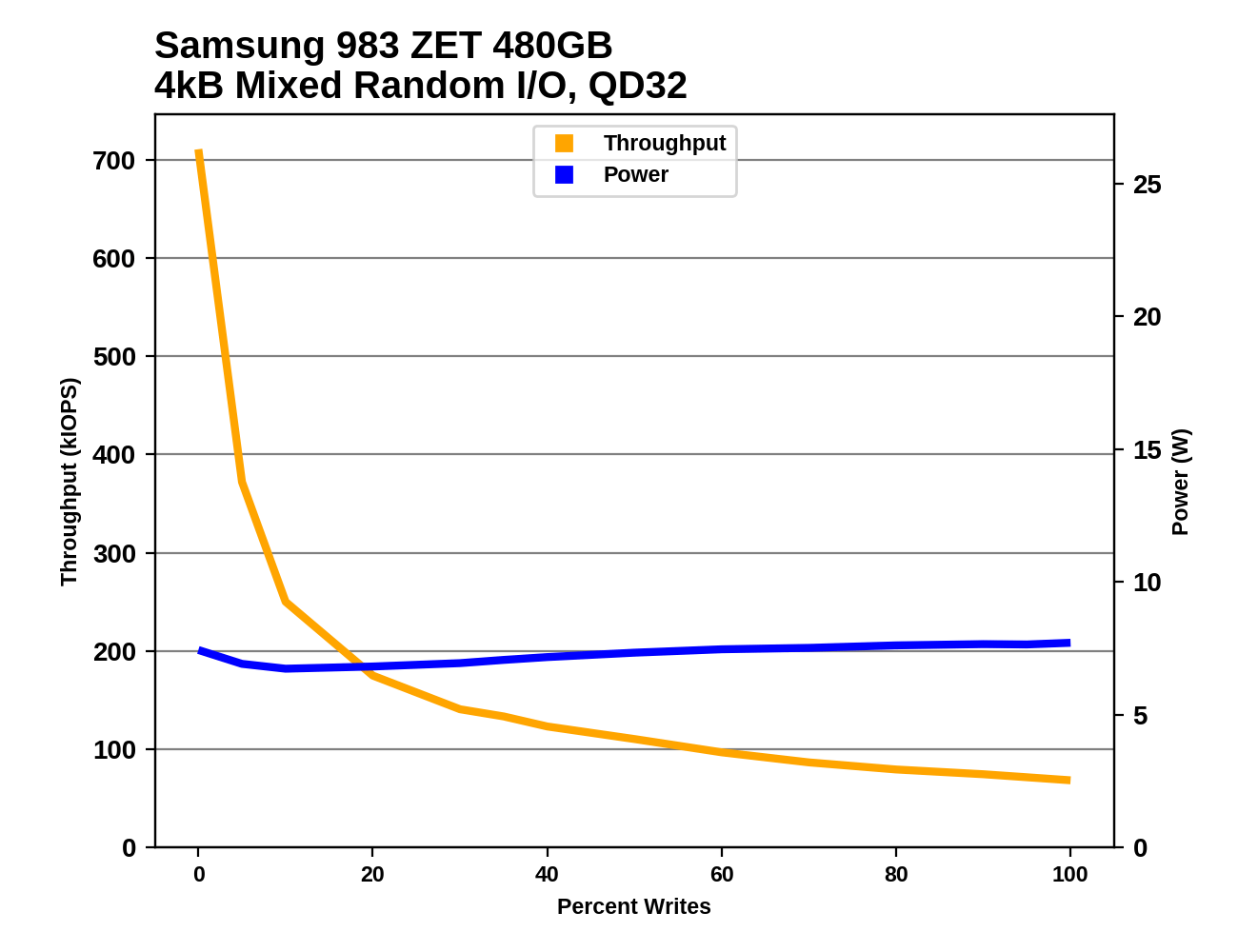
The Samsung 983 ZET starts off the mixed IO tests with extremely high random read performance, but the performance drops very steeply as writes are added to the mix—just 5% writes is enough to almost cut total throughput in half, and the advantage of Z-NAND is gone by the time the workload is 20% writes. Except on the most read-heavy workloads, the flash-based SSDs are limited largely by their steady-state write performance, and the 983 ZET is handicapped there by its low overall capacities.
Aerospike Certification Tool
Aerospike is a high-performance NoSQL database designed for use with solid state storage. The developers of Aerospike provide the Aerospike Certification Tool (ACT), a benchmark that emulates the typical storage workload generated by the Aerospike database. This workload consists of a mix of large-block 128kB reads and writes, and small 1.5kB reads. When the ACT was initially released back in the early days of SATA SSDs, the baseline workload was defined to consist of 2000 reads per second and 1000 writes per second. A drive is considered to pass the test if it meets the following latency criteria:
- fewer than 5% of transactions exceed 1ms
- fewer than 1% of transactions exceed 8ms
- fewer than 0.1% of transactions exceed 64ms
Drives can be scored based on the highest throughput they can sustain while satisfying the latency QoS requirements. Scores are normalized relative to the baseline 1x workload, so a score of 50 indicates 100,000 reads per second and 50,000 writes per second. Since this test uses fixed IO rates, the queue depths experienced by each drive will depend on their latency, and can fluctuate during the test run if the drive slows down temporarily for a garbage collection cycle. The test will give up early if it detects the queue depths growing excessively, or if the large block IO threads can't keep up with the random reads.
We used the default settings for queue and thread counts and did not manually constrain the benchmark to a single NUMA node, so this test produced a total of 64 threads scheduled across all 72 virtual (36 physical) cores.
The usual runtime for ACT is 24 hours, which makes determining a drive's throughput limit a long process. For fast NVMe SSDs, this is far longer than necessary for drives to reach steady-state. In order to find the maximum rate at which a drive can pass the test, we start at an unsustainably high rate (at least 150x) and incrementally reduce the rate until the test can run for a full hour, and then decrease the rate further if necessary to get the drive under the latency limits.

The Samsung 983 ZET outscores its TLC-based sibling 983 DCT, but doesn't beat the throughput that the larger TLC drives provide. There's enough write activity in this test to seriously limit the performance of the Z-SSDs, and so the drives with higher channel counts and much more capacity overall can pull ahead. The Intel Optane SSD DC P4800X still provides the best score on this test, 2.6 times that of the larger 983 ZET and 21% faster than the fastest flash-based SSD we have on hand.
 |
|||||||||
| Power Efficiency | Average Power in W | ||||||||
The 983 ZET and 983 DCT have similar power consumption during this test, and both use substantially less power than the other SSDs in this batch. That doesn't translate to any big advantage in power efficiency, though the larger 983 ZET does provide the second-best efficiency score among the flash-based SSDs. The Optane SSD provides 50% better performance per Watt than any of the flash-based SSDs.








44 Comments
View All Comments
jabber - Tuesday, February 19, 2019 - link
I just looked at the price in the specs and stopped reading right there.Dragonstongue - Tuesday, February 19, 2019 - link
Amen to that LOLFunBunny2 - Tuesday, February 19, 2019 - link
well... if one were to run a truly normalized RDBMS, i.e. 5NF and thus substantially smaller footprint compared to the common NoSQL flatfile alternative, this could be quite competitive. but that would require today's developers/coders to stop making apps just like their COBOL granddaddies did.FreckledTrout - Tuesday, February 19, 2019 - link
I have no idea why you are talking coding and database design principles as it does not apply here at all. To carry your tangent along, if you want to make max use of a SSD's you denormalize the hell out of the database and spread the load over a ton of servers, ie NoSQL.FunBunny2 - Tuesday, February 19, 2019 - link
well... that does keep coders employed forever. writing linguine code all day long.FreckledTrout - Tuesday, February 19, 2019 - link
Well it still is pointless in this conversation about fast SSD's. What spaghetti code has to do with that I have no idea. Sure they can move cloud native way of designing applications using micro services etl al but what the hell that has to do with fast SSD's baffles me.FunBunny2 - Tuesday, February 19, 2019 - link
" What spaghetti code has to do with that I have no idea. "well... you can write neat code against a 5NF datastore, or mountains of linguine to keep all that mound of redundant bytes from biting you. again, let's get smarter than our granddaddies. or not.
GreenReaper - Wednesday, February 20, 2019 - link
They have at least encouraged old-school databases to up their game. With parallel queries on the back-end, PostgreSQL can fly now, as long as you give it the right indexes to play with. Like any complex tool, you still have to get familiar with it to use it properly, but it's worth the investment.FunBunny2 - Wednesday, February 20, 2019 - link
"They have at least encouraged old-school databases to up their game. "well... if you actually look at how these 'alternatives' (NoSql and such) to RDBMS work, you'll see that they're just re-hashes (he he) of simple flat files and IMS. anything xml-ish is just another hierarchical datastore, i.e. IMS. which predates RDBMS (Oracle was the first commercial implementation) by more than a decade. hierarchy and flatfile are the very, very old-school datastores.
PG, while loved because it's Open Source, is buggy as hell. been there, endured that.
anyway. the point of my comments was simply aimed at naming a use-case for these sorts of devices, nothing more, since so many comments questioned why it should exist. which is not to say it's the 'best' implementation for the use-case. but the use-case exists, whether most coders prefer to do transactions in the client, or not. back in your granddaddies' day, terminals (3270 and VT-100) were mostly dumb, and all code existed on the server/mainframe. 'client code' existed in close proximity to the 'database' (VSAM files, mostly), sometimes in the same address space, sometimes just on the same machine, and sometimes on a tethered machine. the point being: with today's innterTubes speed, there's really no advantage to 'doing transactions in the client' other than allowing client-centric coders to avoid learning how to support data integrity declaratively in the datastore. the result, of course, is that data integrity is duplicated both places (client and server) by different folks. there's no way the database folks, DBA and designer, are going to assume that all data coming in over the wire from the client really, really is clean. because it almost never is.
GruffaloOnVacation - Thursday, March 18, 2021 - link
FunBunny2 you sound bitter, and this is the sentiment I see among the old school "database people". May I suggest, with the best of intentions for us all, that instead of sneering at the situation, you attempt to educate those who are willing to learn? I've been working on some SQL in my project at work recently, and so have read a number of articles, and parts of some database books. There was a lot of resentment and sneering at the stoopid programmers there, but no positive programme of action proposed. I'm interested in this subject. Where should I go for resources? Which talks should I watch? What books to read? Let's build something that is as cool as something you described. If it really is THAT good, once it is built - they will come, and they will change!