The Samsung 983 ZET (Z-NAND) SSD Review: How Fast Can Flash Memory Get?
by Billy Tallis on February 19, 2019 8:00 AM ESTPeak Random Read Performance
For client/consumer SSDs we primarily focus on low queue depth performance for its relevance to interactive workloads. Server workloads are often intense enough to keep a pile of drives busy, so the maximum attainable throughput of enterprise SSDs is actually important. But it usually isn't a good idea to focus solely on throughput while ignoring latency, because somewhere down the line there's always an end user waiting for the server to respond.
In order to characterize the maximum throughput an SSD can reach, we need to test at a range of queue depths. Different drives will reach their full speed at different queue depths, and increasing the queue depth beyond that saturation point may be slightly detrimental to throughput, and will drastically and unnecessarily increase latency. SATA drives can only have 32 pending commands in their queue, and any attempt to benchmark at higher queue depths will just result in commands sitting in the operating system's queues before being issued to the drive. On the other hand, some high-end NVMe SSDs need queue depths well beyond 32 to reach full speed.
Because of the above, we are not going to compare drives at a single fixed queue depth. Instead, each drive was tested at a range of queue depths up to the excessively high QD 512. For each drive, the queue depth with the highest performance was identified. Rather than report that value, we're reporting the throughput, latency, and power efficiency for the lowest queue depth that provides at least 95% of the highest obtainable performance. This often yields much more reasonable latency numbers, and is representative of how a reasonable operating system's IO scheduler should behave. (Our tests have to be run with any such scheduler disabled, or we would not get the queue depths we ask for.)
One extra complication is the choice of how to generate a specified queue depth with software. A single thread can issue multiple I/O requests using asynchronous APIs, but this runs into at several problems: if each system call issues one read or write command, then context switch overhead becomes the bottleneck long before a high-end NVMe SSD's abilities are fully taxed. Alternatively, if many operations are batched together for each system call, then the real queue depth will vary significantly and it is harder to get an accurate picture of drive latency. Finally, the current Linux asynchronous IO APIs only work in a narrow range of scenarios.
There is work underway to provide a new general-purpose async IO interface that will enable drastically lower overhead, but until that work lands in stable kernel versions, we're sticking with testing through the synchronous IO system calls that almost all Linux software uses. This means that we test at higher queue depths by using multiple threads, each issuing one read or write request at a time.
Using multiple threads to perform IO gets around the limits of single-core software overhead, and brings an extra advantage for NVMe SSDs: the use of multiple queues per drive. The NVMe drives in this review all support 32 separate IO queues, so we can have 32 threads on separate cores independently issuing IO without any need for synchronization or locking between threads.
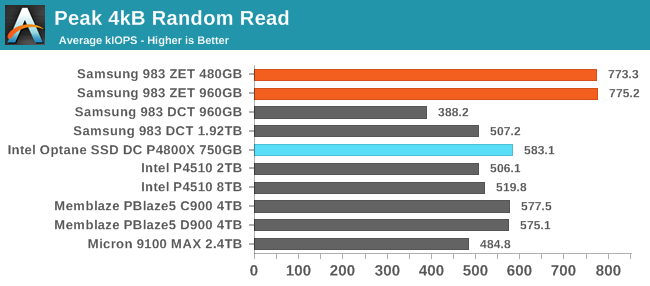
When performing random reads with a high thread count, the Samsung 983 ZET delivers significantly better throughput than any other drive we've tested: about 775k IOPS, which is over 3GB/s and about 33% faster than the Intel Optane SSD DC P4800X. The Optane SSD hits its peak throughput at QD8, while the 983 ZET requires a queue depth of at least 16 to match the Optane SSD's peak, and the peak for the 983 ZET is at QD64.
 |
|||||||||
| Power Efficiency in kIOPS/W | Average Power in W | ||||||||
At this point, it's no surprise to see the 983 turn in great efficiency scores. It's drawing almost 8W during this test, but that's not particularly high by the standards of enterprise NVMe drives. The TLC-based 983 DCT provides the next-best performance per Watt due to even lower power consumption than the Z-SSDs.
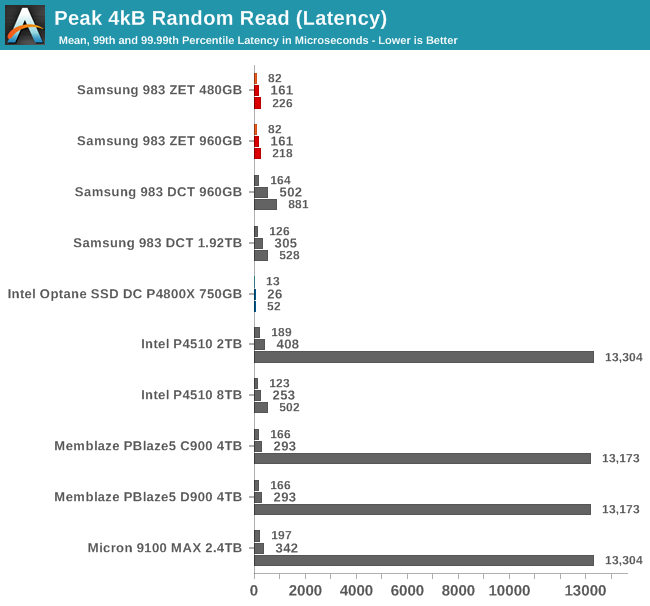
The Optane SSD still holds on to a clear advantage in the random read latency scores, with 99.99th percentile latency that is lower than the average read latency of even the Z-SSDs. The two Z-SSDs do provide lower tail latencies than the other flash-based SSDs, several of which require very high thread counts to reach full throughput and thus end up with horrible 99.99th percentile latencies due to contention for CPU cores.
Peak Sequential Read Performance
Since this test consists of many threads each performing IO sequentially but without coordination between threads, there's more work for the SSD controller and less opportunity for pre-fetching than there would be with a single thread reading sequentially across the whole drive. The workload as tested bears closer resemblance to a file server streaming to several simultaneous users, rather than resembling a full-disk backup image creation.

The Memblaze PBlaze5 C900 has the highest peak sequential read speed thanks to its PCIe 3.0 x8 interface. Among the drives with the more common four lane connection, the Samsung 983 ZETs are tied for first place, but they reach that ~3.1GB/s with a slightly lower queue depth than the 983 DCT or PBlaze5 D900. The Optane SSD DC P4800X comes in last place, being limited to just 2.5GB/s for multi-stream sequential reads.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
The Samsung 983s clearly have the best power efficiency on this sequential read test, but the TLC-based 983 DCT continues once again uses slightly less power than the 983 ZET, so the Z-SSDs don't quite take first place. The Optane SSD doesn't have the worst efficiency rating, because despite its low performance, it only uses 2W more than the Samsung drives, far less than the Memblaze or Micron drives.
Steady-State Random Write Performance
The hardest task for most enterprise SSDs is to cope with an unending stream of writes. Once all the spare area granted by the high overprovisioning ratios has been used up, the drive has to perform garbage collection while simultaneously continuing to service new write requests, and all while maintaining consistent performance. The next two tests show how the drives hold up after hours of non-stop writes to an already full drive.
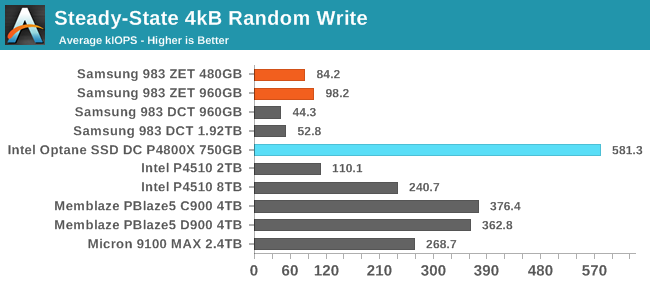
The Samsung 983 ZETs outperform the TLC-based 983 DCTs for steady-state random writes, but otherwise are outclassed by the larger flash-based SSDs and the Optane SSD, which is almost six times faster than the 960GB 983 ZET. Using Z-NAND clearly helps some with steady-state write performance, but the sheer capacity of the bigger TLC drives helps even more.
 |
|||||||||
| Power Efficiency in kIOPS/W | Average Power in W | ||||||||
The 983 ZET uses more power than the 983 DCT, but not enough to overcome the performance advantage; the 983 ZET has the best power efficiency among the smaller flash-based SSDs. The 4TB and larger drives outperform the 983 ZET so much that they have significantly better efficiency scores even drawing 2.6x the power. The Intel Optane SSD consumes almost twice the power of the 983 ZET but still offers better power efficiency than any of the flash-based SSDs.
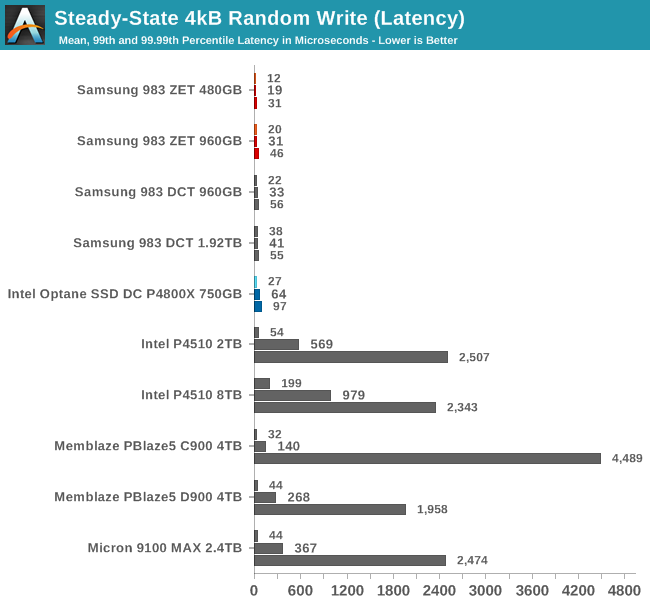
The Samsung drives and the Intel Optane SSD all have excellent latency stats for the steady-state random write test. The Intel P4510, Memblaze PBlaze5 and Micron 9100 all have decent average latencies but much worse QoS, with 99.99th percentile latencies of multiple milliseconds. These drives don't require particularly high queue depths to saturate their random write speed, so these QoS issues aren't due to any host-side software overhead.
Steady-State Sequential Write Performance

As with random writes, the steady-state sequential write performance of the Samsung 983 ZET is not much better than its TLC-based sibling. The only way for a flash-based SSD to handle sustained writes as well as the Optane SSD is to have very high capacity and overprovisioning.
 |
|||||||||
| Power Efficiency in MB/s/W | Average Power in W | ||||||||
The Samsung 983 ZET provides about half the performance per Watt of the Optane SSD during sequential writes. That's still decent compared to many other flash-based NVMe SSDs, but the 983 DCT and Memblaze PBlaze5 are slightly more efficient.








44 Comments
View All Comments
jabber - Tuesday, February 19, 2019 - link
I just looked at the price in the specs and stopped reading right there.Dragonstongue - Tuesday, February 19, 2019 - link
Amen to that LOLFunBunny2 - Tuesday, February 19, 2019 - link
well... if one were to run a truly normalized RDBMS, i.e. 5NF and thus substantially smaller footprint compared to the common NoSQL flatfile alternative, this could be quite competitive. but that would require today's developers/coders to stop making apps just like their COBOL granddaddies did.FreckledTrout - Tuesday, February 19, 2019 - link
I have no idea why you are talking coding and database design principles as it does not apply here at all. To carry your tangent along, if you want to make max use of a SSD's you denormalize the hell out of the database and spread the load over a ton of servers, ie NoSQL.FunBunny2 - Tuesday, February 19, 2019 - link
well... that does keep coders employed forever. writing linguine code all day long.FreckledTrout - Tuesday, February 19, 2019 - link
Well it still is pointless in this conversation about fast SSD's. What spaghetti code has to do with that I have no idea. Sure they can move cloud native way of designing applications using micro services etl al but what the hell that has to do with fast SSD's baffles me.FunBunny2 - Tuesday, February 19, 2019 - link
" What spaghetti code has to do with that I have no idea. "well... you can write neat code against a 5NF datastore, or mountains of linguine to keep all that mound of redundant bytes from biting you. again, let's get smarter than our granddaddies. or not.
GreenReaper - Wednesday, February 20, 2019 - link
They have at least encouraged old-school databases to up their game. With parallel queries on the back-end, PostgreSQL can fly now, as long as you give it the right indexes to play with. Like any complex tool, you still have to get familiar with it to use it properly, but it's worth the investment.FunBunny2 - Wednesday, February 20, 2019 - link
"They have at least encouraged old-school databases to up their game. "well... if you actually look at how these 'alternatives' (NoSql and such) to RDBMS work, you'll see that they're just re-hashes (he he) of simple flat files and IMS. anything xml-ish is just another hierarchical datastore, i.e. IMS. which predates RDBMS (Oracle was the first commercial implementation) by more than a decade. hierarchy and flatfile are the very, very old-school datastores.
PG, while loved because it's Open Source, is buggy as hell. been there, endured that.
anyway. the point of my comments was simply aimed at naming a use-case for these sorts of devices, nothing more, since so many comments questioned why it should exist. which is not to say it's the 'best' implementation for the use-case. but the use-case exists, whether most coders prefer to do transactions in the client, or not. back in your granddaddies' day, terminals (3270 and VT-100) were mostly dumb, and all code existed on the server/mainframe. 'client code' existed in close proximity to the 'database' (VSAM files, mostly), sometimes in the same address space, sometimes just on the same machine, and sometimes on a tethered machine. the point being: with today's innterTubes speed, there's really no advantage to 'doing transactions in the client' other than allowing client-centric coders to avoid learning how to support data integrity declaratively in the datastore. the result, of course, is that data integrity is duplicated both places (client and server) by different folks. there's no way the database folks, DBA and designer, are going to assume that all data coming in over the wire from the client really, really is clean. because it almost never is.
GruffaloOnVacation - Thursday, March 18, 2021 - link
FunBunny2 you sound bitter, and this is the sentiment I see among the old school "database people". May I suggest, with the best of intentions for us all, that instead of sneering at the situation, you attempt to educate those who are willing to learn? I've been working on some SQL in my project at work recently, and so have read a number of articles, and parts of some database books. There was a lot of resentment and sneering at the stoopid programmers there, but no positive programme of action proposed. I'm interested in this subject. Where should I go for resources? Which talks should I watch? What books to read? Let's build something that is as cool as something you described. If it really is THAT good, once it is built - they will come, and they will change!