The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTConclusions: Not All Cores Are Made Equal
Designing a processor is often a finely tuned craft. To get performance, the architect needs to balance compute with throughput and at all times have sufficient data in place to feed the beast. If the beast is left idle, it sits there and consumes power, while not doing any work. Getting the right combination of resources is a complex task, and the reason why top CPU companies hire thousands of engineers to get it to work right. As long as the top of the design is in place, the rest should follow.
Sometimes, more esoteric products fall out of the stack. The new generation of AMD Ryzen Threadripper processors are just that – a little esoteric. The direct replacements for the previous generation units, replacing like for like but with better latency and more frequency, are a known component at this point and we get the expected uplift. It is just this extra enabled silicon in the 2990WX, without direct access to memory, is throwing a spanner in the works.
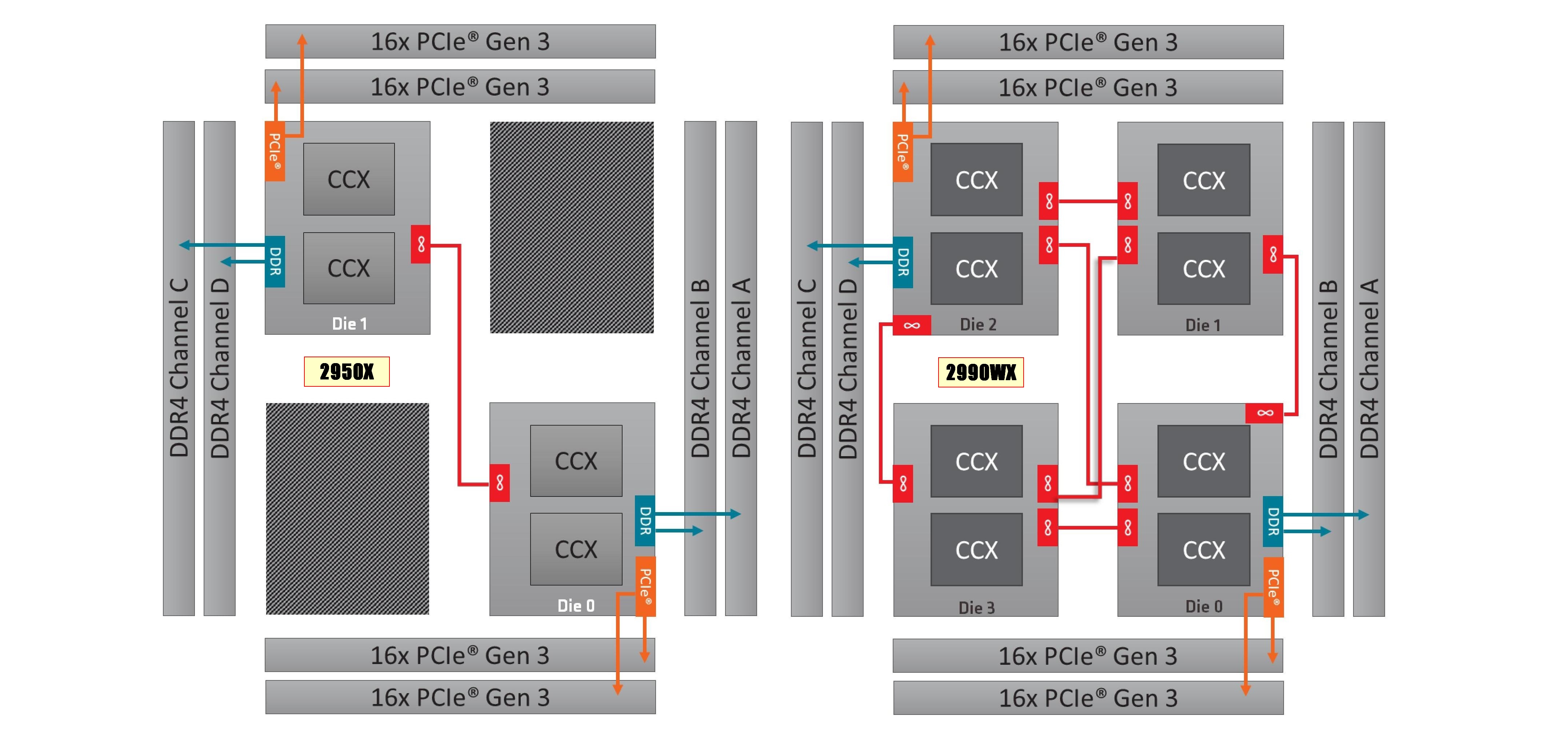
2950X (left) and 2990WX (right)
When some cores are directly connected to memory, such as the 2950X, all of the cores are considered equal enough that distributing a workload is a fairly easy task. With the new processors, we have the situation on the right, where only some cores are directly attached to memory, and others are not. In order to go from one of these cores to main memory, it requires an extra hop, which adds latency. When all the cores are requesting access, this causes congestion.
In order to take the full advantage of this setup, the workload has to be memory light. In workloads such as particle movement, ray-tracing, scene rendering, and decompression, having all 32-cores shine a light means that we set new records in these benchmarks.
In true Janus style, for other workloads that are historically scale with cores, such as physics, transcoding, and compression, the bi-modal core caused significant performance regression. Ultimately, there seems to be almost no middle ground here – either the workload scales well, or it sits towards the back of our high-end testing pack.
Part of the problem relates to how power is distributed with these big core designs. As shown on page four, the more chiplets that are in play, or the bigger the mesh, the more power gets diverted from the cores to the internal networking, such as the uncore or Infinity Fabric. Comparing the one IF link in the 2950X to the six links in 2990WX, we saw the IF consuming 60-73% of the chip power total at small workloads, and 25-40% at high levels.
In essence, at full load, a chip like the 2990WX is only using 60% of its power budget for CPU frequency. In our EPYC 7601, because of the additional memory links, the cores were only consuming 50% of the power budget at load. Rest assured, once AMD and Intel have finished fighting over cores, the next target on their list will be this interconnect.
But the knock on effect of not using all the power for the cores, as well as having a bi-modal operation of cores, is that some workloads will not scale: or in some cases regress.
The Big Cheese: AMD’s 32-Core Behemoth
There is no doubting that when the AMD Ryzen Threadripper 2990WX gets a change to work its legs, it will do so with gusto. We were able to overclock the system to 4.0 GHz on all cores by simply changing the BIOS settings, although AMD also supports features like Precision Boost Overdrive in Windows to get more out of the chip. That being said, the power consumption when using half of the cores at 4.0 GHz pushes up to 260W, leaving a full loaded CPU nudging 450-500W and spiking at over 600W. Users will need to make sure that their motherboard and power supply are up to the task.
This is the point where I mention if we would recommend AMD’s new launches. The 2950X slots right in to where the 1950X used to be, and at a lower price point, and we are very comfortable with that. However the 2950X already sits as a niche proposition for high performance – the 2990WX takes that ball and runs with it, making it a niche of a niche. To be honest, it doesn’t offer enough cases where performance excels as one would expect – it makes perfect sense for a narrow set of workloads where it toasts the competition. It even outperforms almost all the other processors in our compile test. However there is one processor that did beat it: the 2950X.
For most users, the 2950X is enough. For the select few, the 2990WX will be out of this world.








171 Comments
View All Comments
Lolimaster - Monday, August 13, 2018 - link
Then build one yourself.tmnvnbl - Monday, August 13, 2018 - link
How did you measure power numbers for core/uncore? Did these validate with e.g. wall measurements? The interconnect power study is very interesting, but I would like to see some more methodology there.seafellow - Monday, August 13, 2018 - link
I second the ask...how was measurement performed? How can we (the readers) have confidence in the numbers without an understanding of how the numbers were generated?GreenReaper - Wednesday, August 15, 2018 - link
Modern CPUs measure this themselves. AMD itself has boasted of the number of points at which they measure power usage throughout its new CPUs. Check out 'turbostat' in the 'linux-cpupower' package - or grab a copy of HWiNFO that will show it.Darty Sinchez - Monday, August 13, 2018 - link
This here article be awesome. I is so ready to buy. But, me no have enough money so I wait for it sale.perfmad - Monday, August 13, 2018 - link
So is the 2990WX bottlenecking in Handbrake because of the indirect memory access for some cores? Would be interesting to know if that bottleneck can be worked around by running multiple encodes simultaniously, The latest Vidcoder beta uses the handbrake core and has recently added support for multiple simultanous encodes. Would be really appreciated if you had time to look into that.Also do you share the source file and presets you use for the handbrake tests so we can run them on our hardware to get a comparison? My CPU isn't one you've tested.
Thanks for the review thus far.
AlexDaum - Monday, August 13, 2018 - link
I think, the problem with the memory bandwidth cannot be easily fixed, as it isn't a Problem, that one Process uses to much memory, but one core on one of the dies without memory controller, needs to access the infinity fabric to get Data. When all of the cores are active and want to fetch data from memory, it would cause contention on the IF Bus, which reduces the available memory bandwidth a whole lot and the core is just waiting for memory.This is just my speculation though, not based on facts, other than the bottleneck.
Aephe - Monday, August 13, 2018 - link
Those 2990WX Corona results! Can't wait to get a machine based on this baby! Holding up for TR2 release was worth it for me at least.Ian Cutress - Monday, August 13, 2018 - link
That benchmark result broke my graphing engine ! Had to start reporting it the millions.melgross - Monday, August 13, 2018 - link
It’s interesting. This reminds me of Bulldozer, where they made a bad bet with floating point (among some other things), and that held then back for years. This looks almost too specialized for most uses.