The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTFeed Me: Infinity Fabric Requires More Power
When moving from a ring bus to move data between cores and the memory controllers to a mesh or chiplet system, communication between the cores gets a lot more complex. At this point each core or core subset has to act like a router, and decide the best path for the data to go if multiple hops are required to reach the intended target. As we saw with Intel’s MoDe-X mesh at the launch of Skylake-X, the key here is to both avoid contention for the best performance and reduce wire lengths to decrease power. It turns out that in these systems, the inter-core communication technique starts eating up a lot of power, and can consume more power than the cores.
To describe chip power, all consumer processors have a rated ‘TDP’, or thermal design power. Intel and AMD measure this value differently, based on workloads and temperatures, but the technical definition of TDP is the ability of the cooler to dissipate this much thermal energy when the processor is fully loaded (and usually defined at base frequency, not all-core turbo). Actual power consumption might be higher, based on losses by the power delivery, or thermal dissipation through the board, but for most situations TDP and power consumption are broadly considered equal.
This means that the TDP ratings on modern processors, such as 65W, 95W, 105W, 140W, 180W, and now 250W, should broadly indicate the peak sustained power consumption. However, as explained in the first paragraph, not all that power gets to go to pushing frequency in the cores. Some has to be used in the memory controllers, in the IO, into integrated graphics (for the chips that have them), and now the core-to-core interconnect becomes a big part of this. Just how much should be something eye-opening.
For most CPUs, we have the ability to measure either per-core or all-core power, as well as the power of the whole chip. If we subtract the 'core' power from the 'chip' power, we are left with a number of things: DRAM controller power plus interconnect power, and in some cases, L3 power as well.
To see the scale of this, let us start with something straight-forward and known to most users. Intel’s latest Coffee Lake processors, such as the Core i7-8700K, use what is known as a ring-bus design. These processors use a single ring to connect each of the cores and the memory controller – if data has to be moved, it gets placed into the ring and shuttles along to go to where it is needed. This system has historically been called the ‘Uncore’, and can run at a different frequency to the main cores, allowing for its power to scale with what is available. The power distribution looks like this:
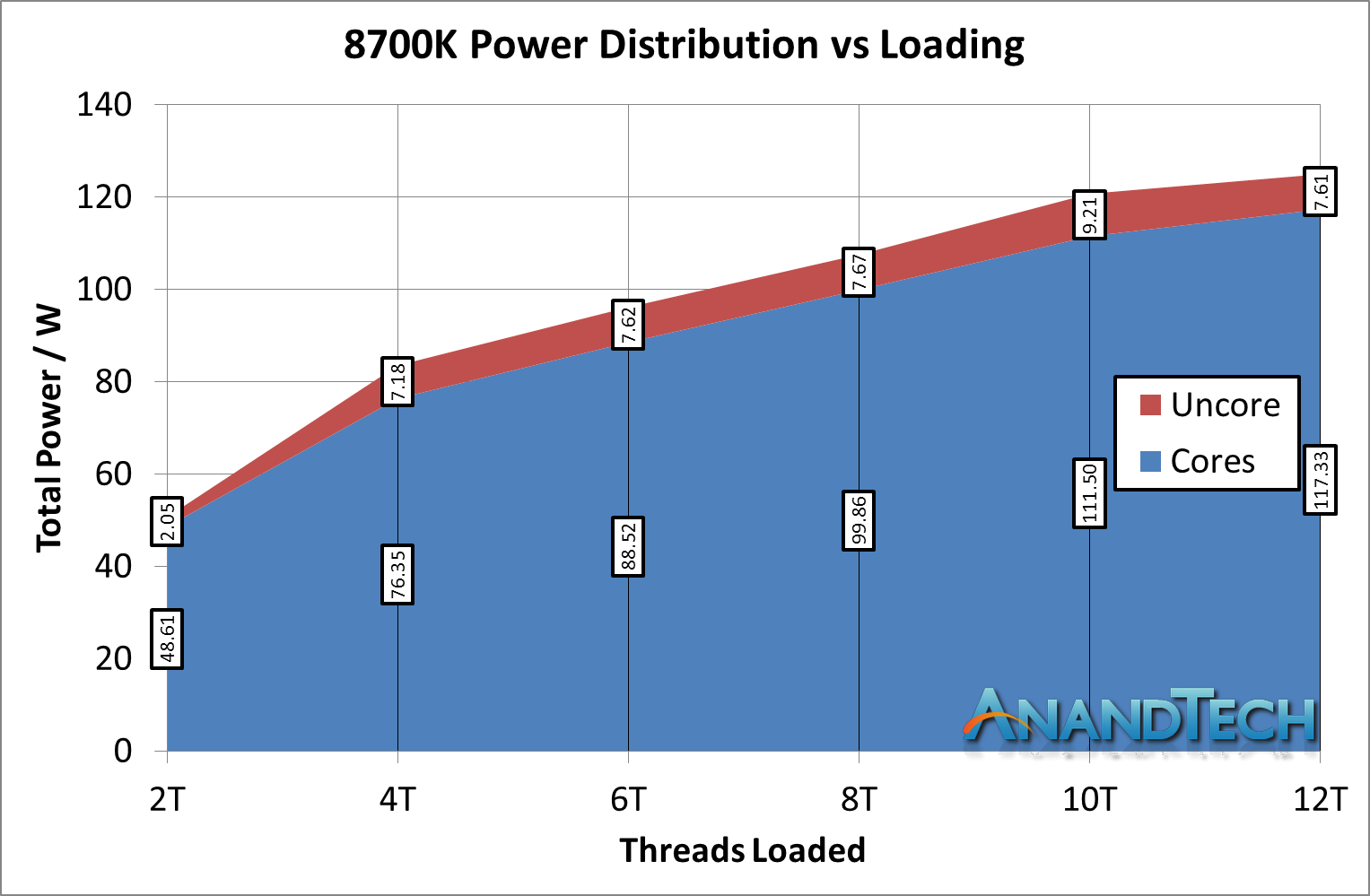
Despite the 95W TDP, this processor at stock frequencies consumes around 125 W at load, beyond its TDP (which is defined at base frequency). However it is more the ratio of the uncore to the total power we are concerned with: at light loading, the uncore is only 4% of the total power, but that rises to 7-9% as we load up the cores. For argument, let us call this a maximum of 10%.
Now let us go into something more meaty: Intel’s Skylake-X processors. In this design, Intel uses its new ‘mesh’ architecture, similar to MoDe-X, whereby each subset of the processor has a small router / crossbar partition that can direct a data packet to the cores around it, or to itself, as required.
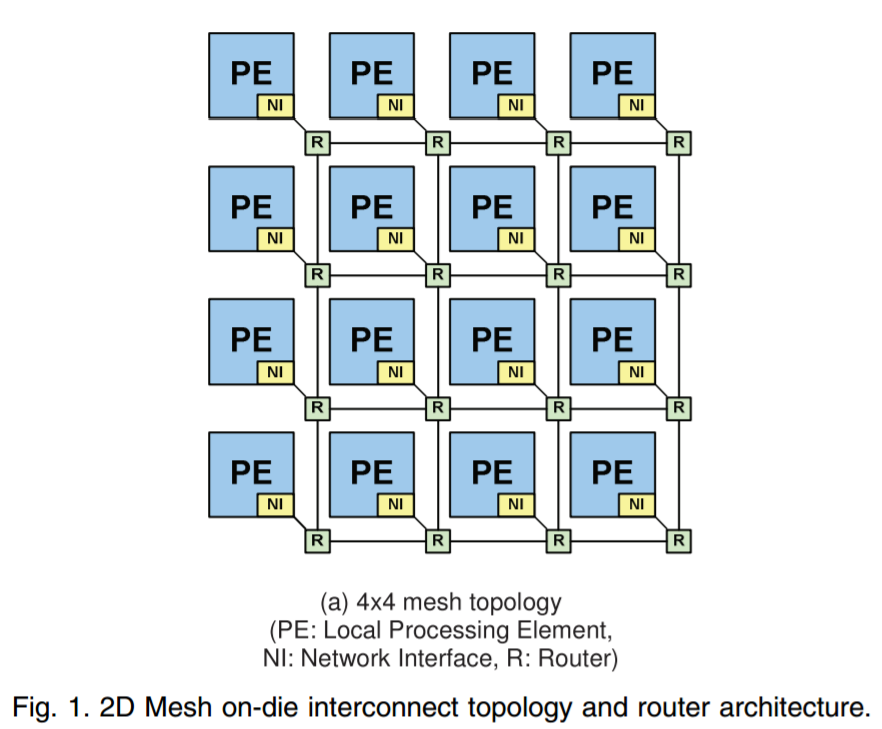
This design allows the processor to scale, given that ring based systems occur additional latency beyond about 14 cores or so (going by how Intel intercepted the mesh design). However, the mesh runs at a lower latency than the ring systems that Intel used to use, and they also consume a lot more power.
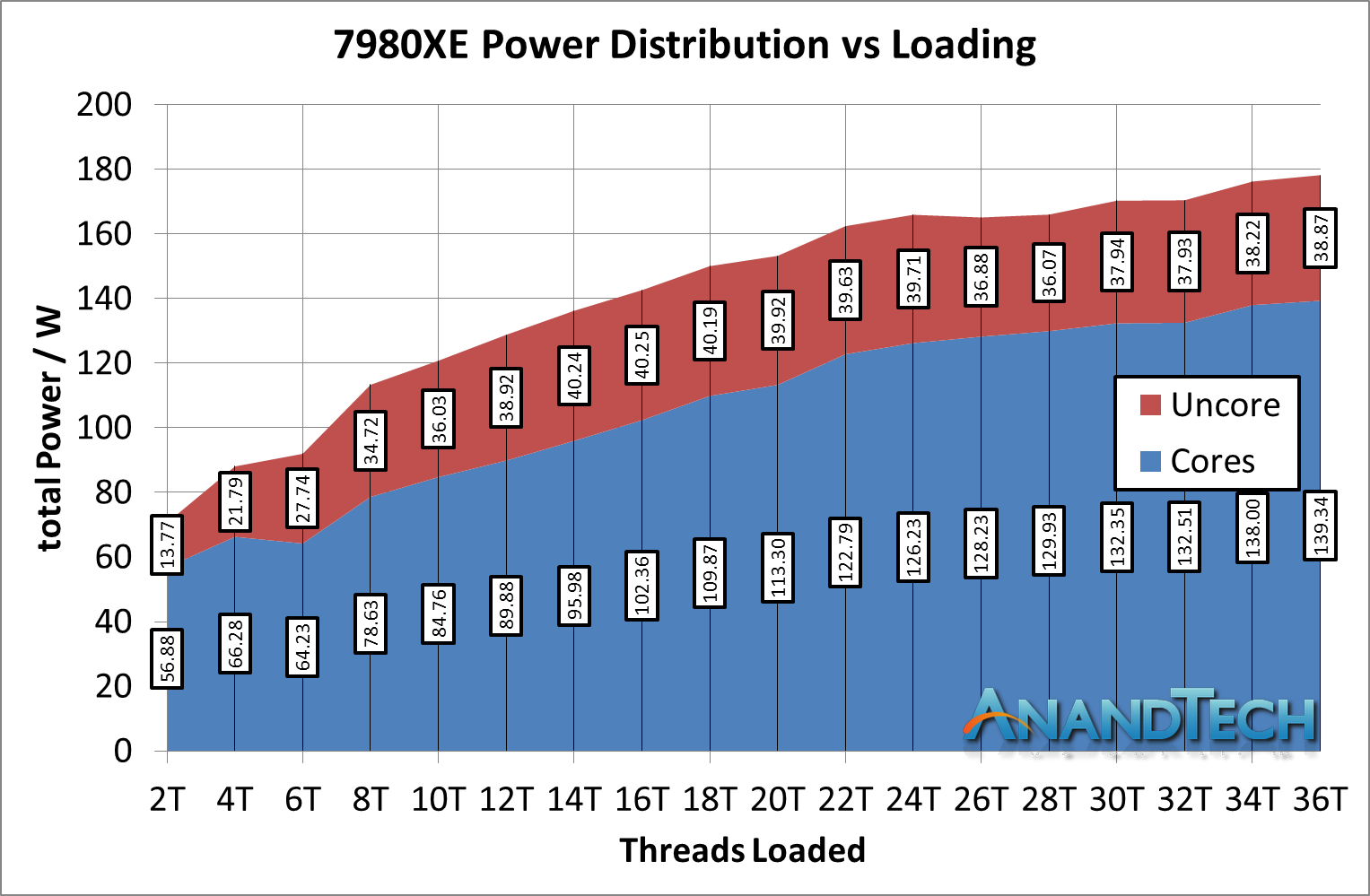
In this setup, we see the power that isn't for the cores starting at 20% of the total chip power, moving up to 25-30% as more cores are loaded. As a result, around one-quarter to one-third of the power on the chip is being used for core-to-core and core-to-memory communication, as well as IO. This is despite the fact that the mesh is often cited as one of the key criticisms of the performance of this processor: the benefit of being able to scale out beyond 24 processors properly is the reason why Intel has gone down this path.
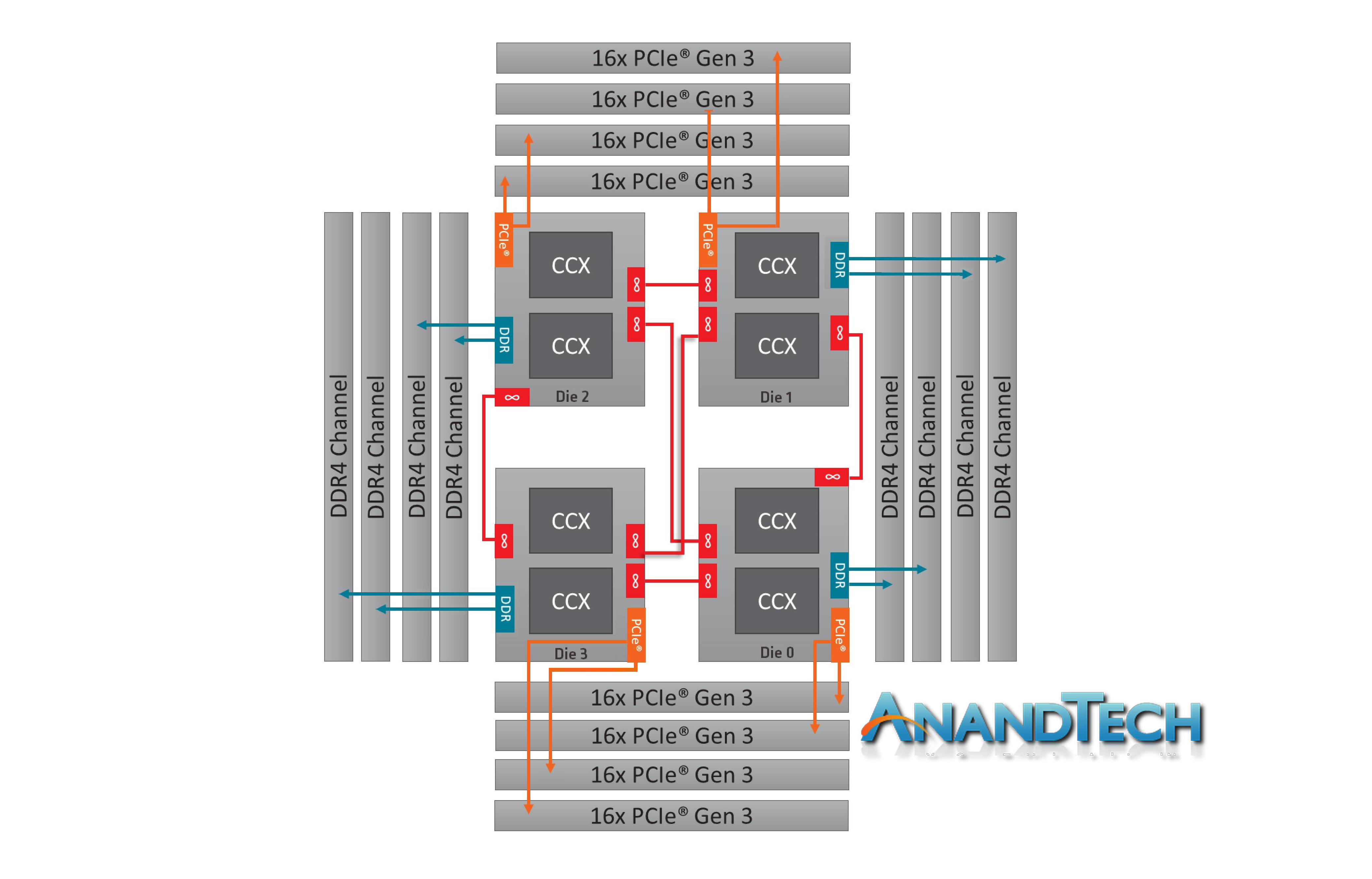
For AMD, the situation is a bit mix and match. With a single four-core complex, communication between cores is relatively simple and uses a centralized crossbar. When dealing with so few cores, the communication method is simple and light. However, within two sets of complexes on the same silicon, or the memory controller, the interconnect comes into play. This is not so much a ring, but is based on an internal version of Infinity Fabric (IF).
The IF is designed to be scalable across cores, silicon, and sockets. We can probe what it does within a single piece of silicon by looking directly at the Ryzen 7 2700X, which has a TDP of 105W.
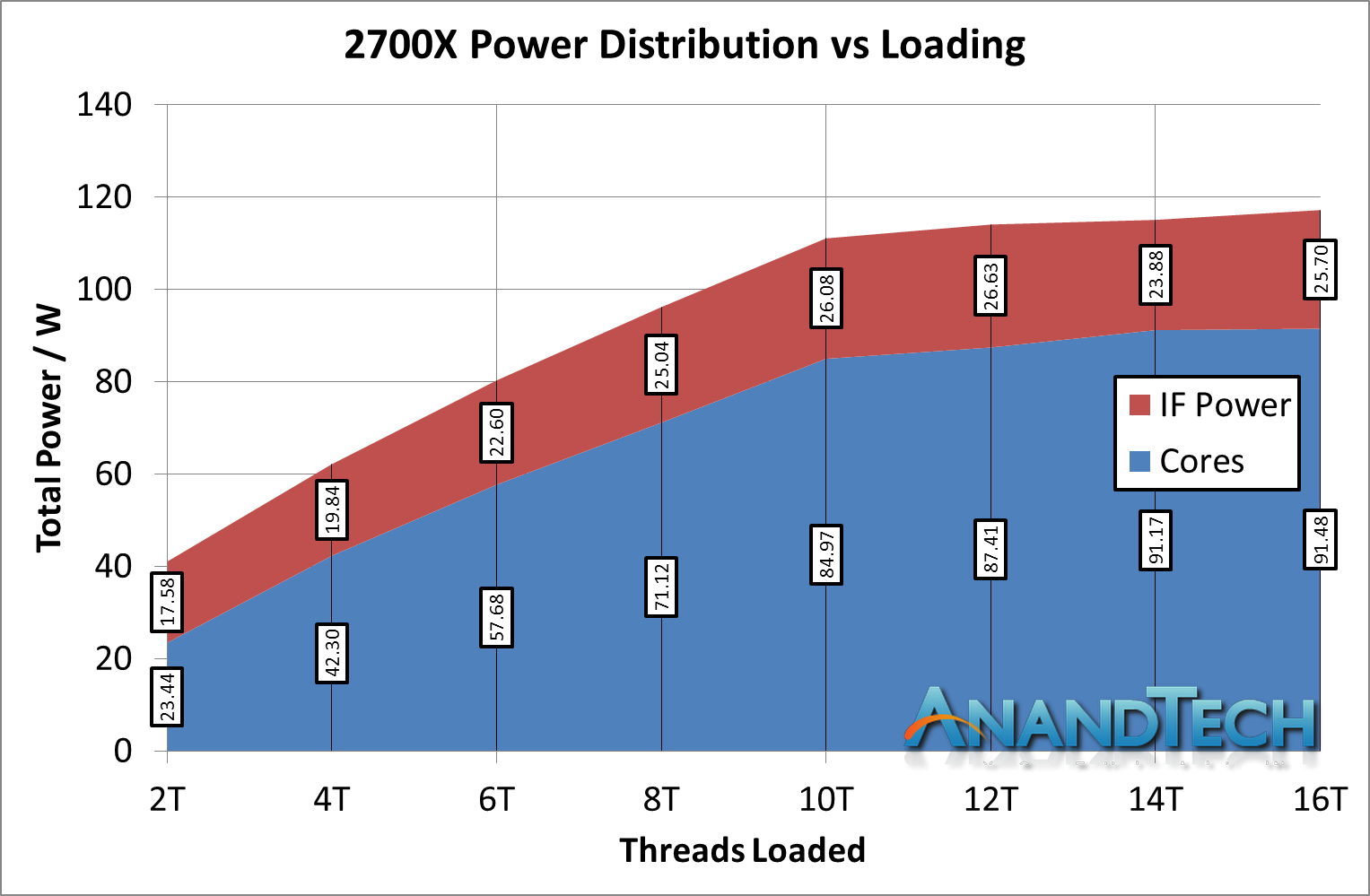
*IF Power should be 'Non-Core' power, which includes IF + DRAM controller + IO
AMD’s product here gives two interesting data points. Firstly, when the cores are weakly loaded, the IF + DRAM controller + IO accounts for a massive 43% of the total power of the processor. This is compared to 4% for the i7-8700K and 19% for the i9-7980XE. However, that 43% reduces down to around 25% of the full chip, but this is still on par with the bigger mesh based processor from Intel.
Another interesting point is that the combined non-core power doesn’t change that much scaling up the cores, going from ~17.6W to ~25.7W. For the big Intel chip, we saw it rise from ~13.8W up to beyond 40W in some cases. This brings the question as to if Intel’s offering can scale in power at the low end, and if AMD’s non-core power as an initial ‘power penalty’ to pay before the cores start getting loaded up.
With this data, let us kick it up a notch to the real story here. The Ryzen Threadripper 2950X is the updated 16-core version of Threadripper, which uses a single IF link between the two silicon dies to talk between the sets of core complexes.
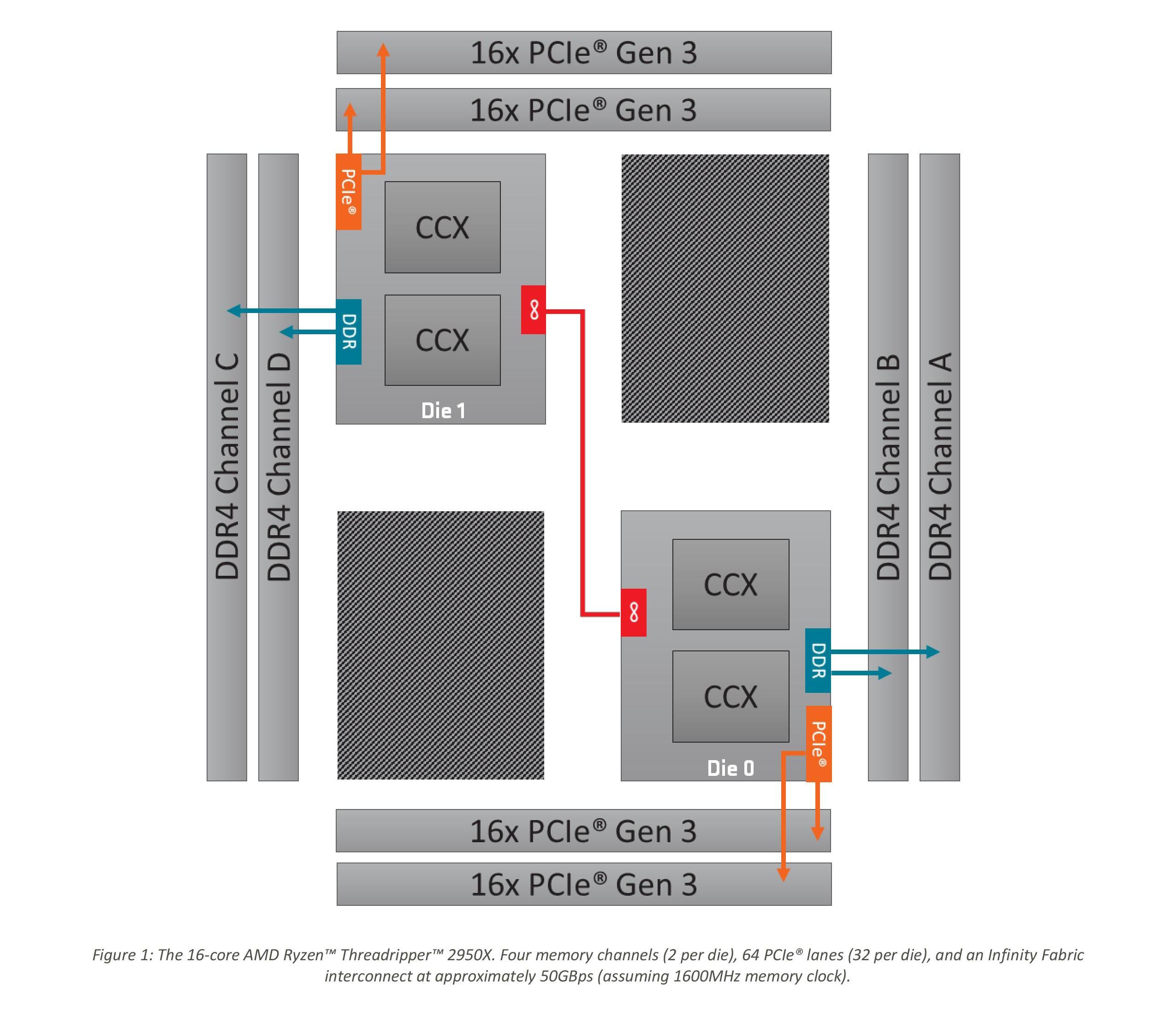
As shown on the diagram, the red line represents the IF link combined with the DRAM controller and IO. In this case, the non-core we measure includes the intra-silicon interconnect as well as the inter-silicon interconnect.
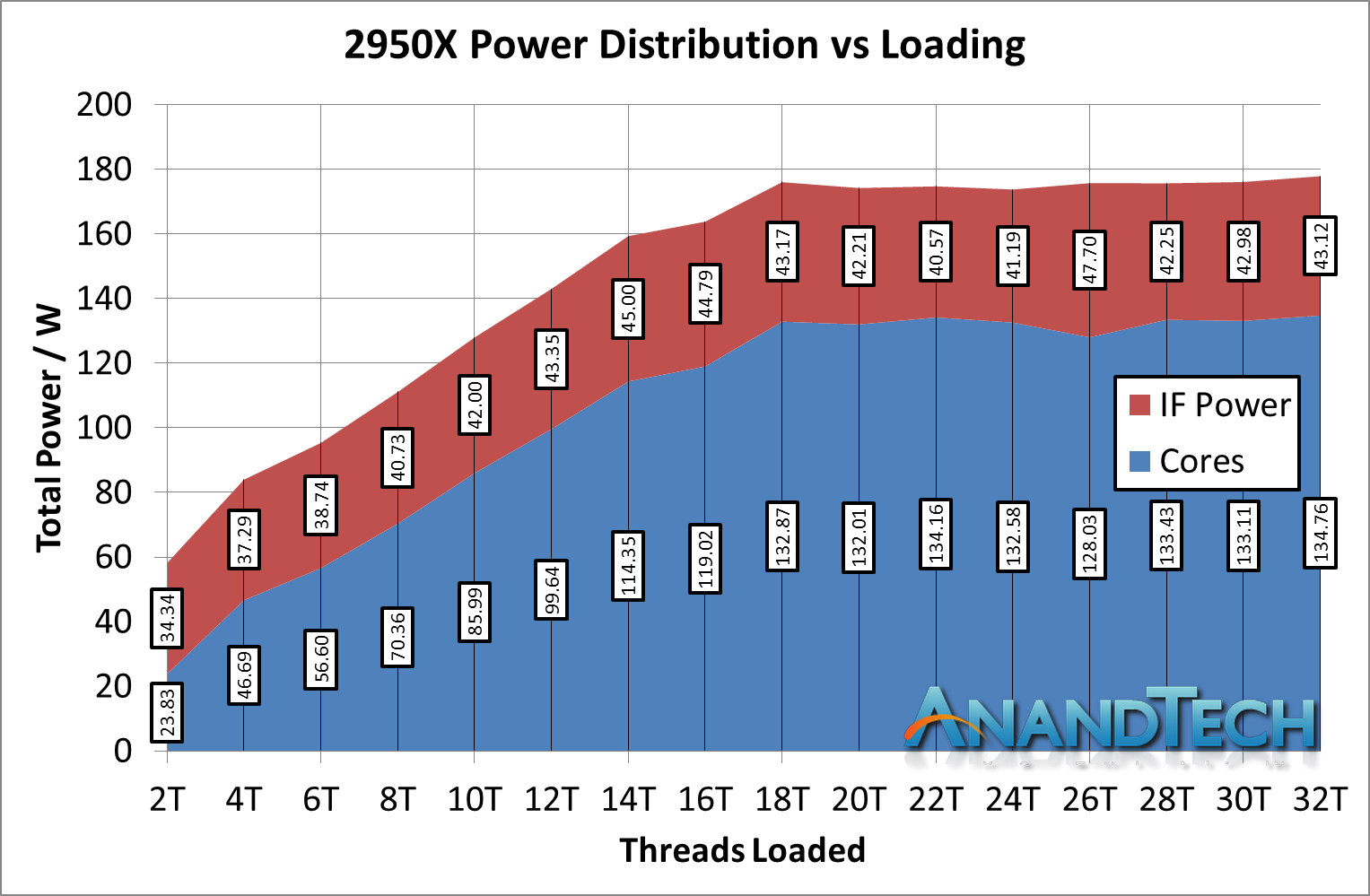
*IF Power should be 'Non-Core' power, which includes IF + DRAM controller + IO
In percentage of power, the non-core power consumes 59% of the total power consumption of the chip when loaded at two threads. So even though both threads are located on the same core on the same CCX, because it needs to have access to all of the memory of the system, the die-to-die silicon link is enabled as well as the intra-silicon links are all fired up.
However, the amount of power consumed by the IF + DRAM controller + IO, as the core loading scales, does not increase all that much, from 34W to 43W, slowly reducing to around 25% of the total chip power, similar to the 2700X. It is just that initial bump that screams a lot, because of the way that that core still needs access to all the memory bandwidth available.
Now we should consider the 2990WX. Because all four silicon dies are enabled on the package, and each die needs an IF interconnect to each other die, there are now six IF links to fire up:
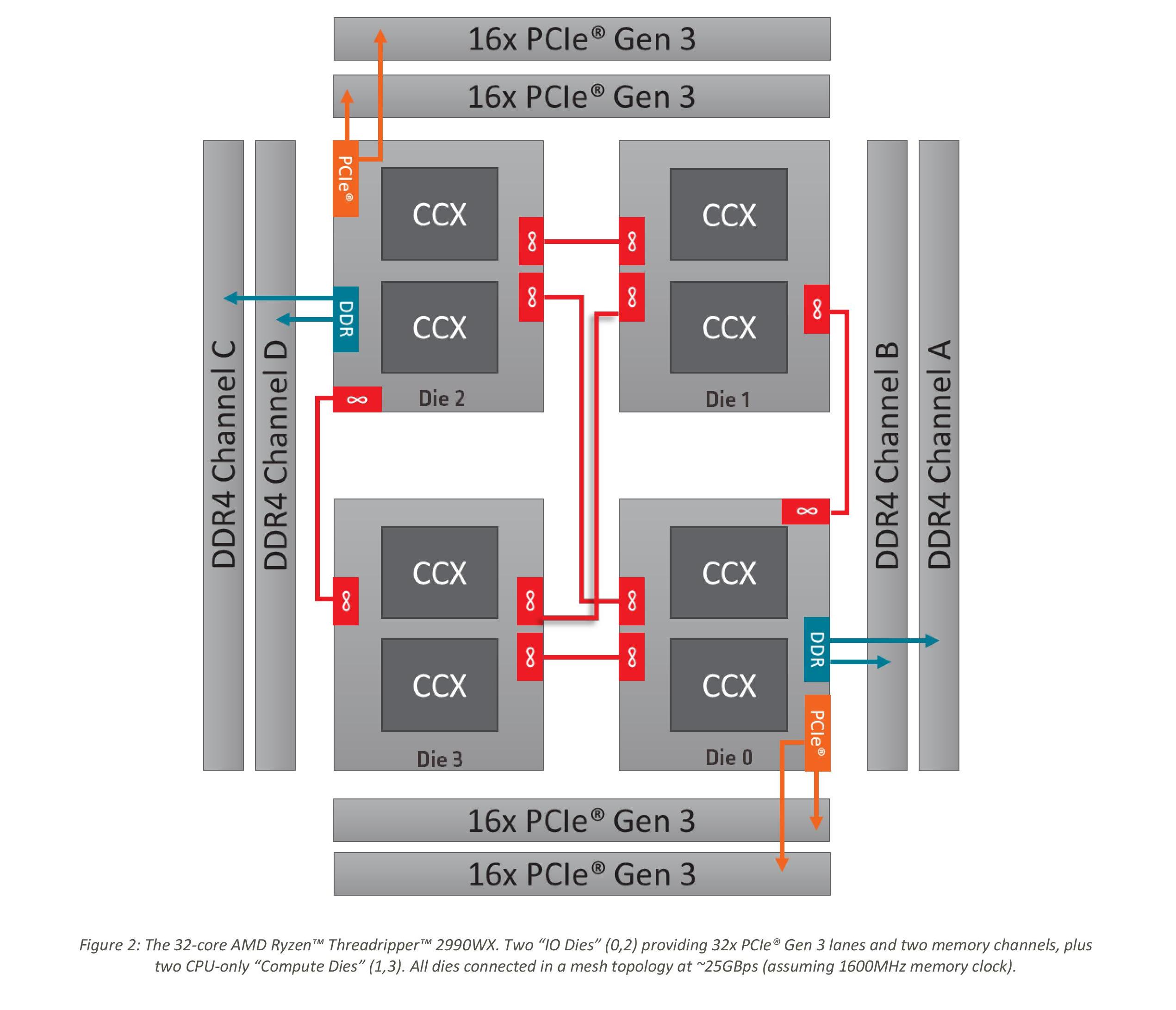
There’s a lot of red in that diagram. It is noteworthy that two of the silicon dies do not have DRAM attached to them, and so when only a few cores are enabled, theoretically AMD should be able to power down those IF links as they would only cause additional latency hops if other IF links are congested. In fact, we get something very odd indeed.
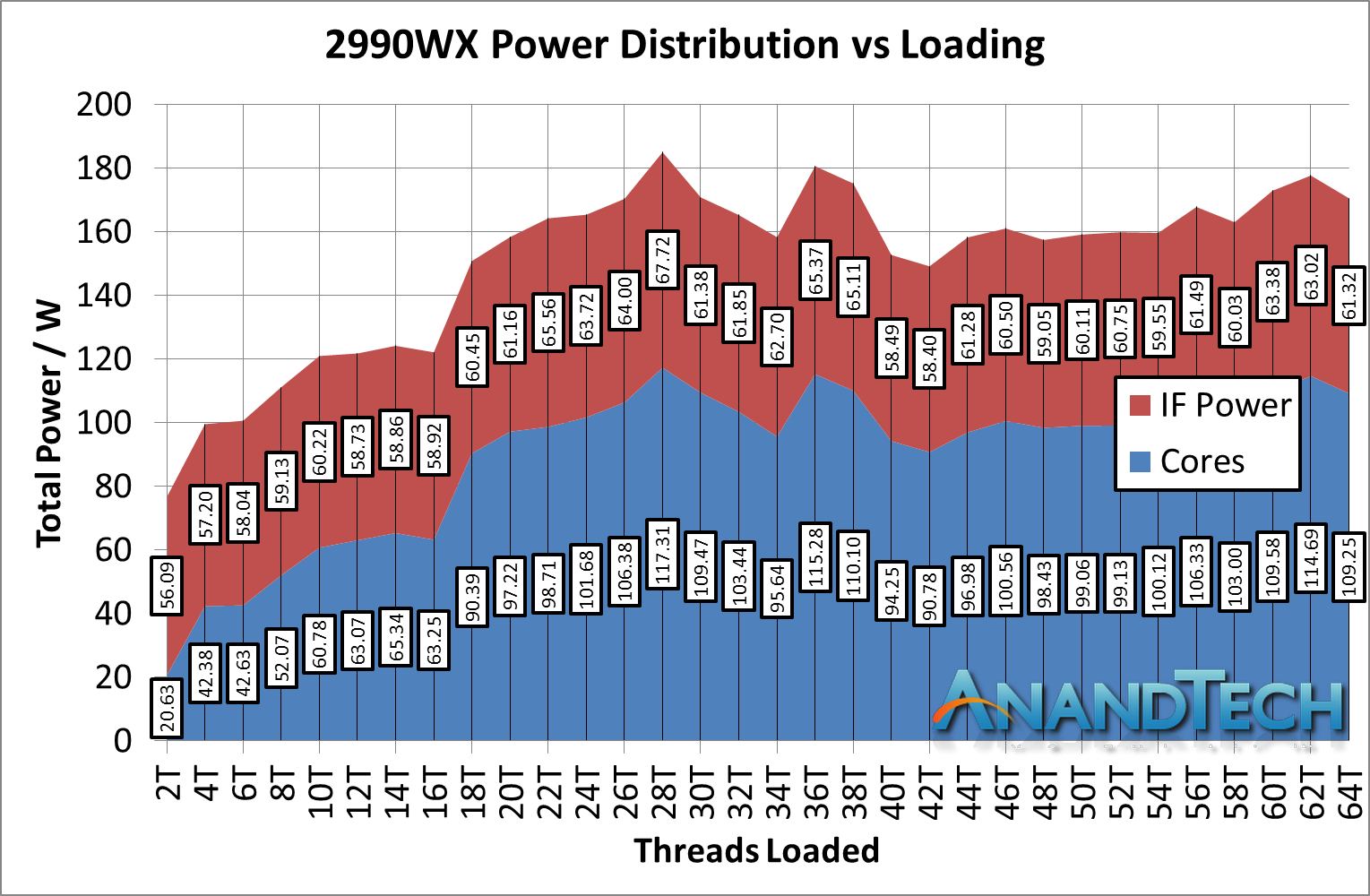
*IF Power should be 'Non-Core' power, which includes IF + DRAM controller + IO
First, let us start with the low-loading metrics. Here the non-core power is consuming 56.1W from the total 76.7W power consumption, a massive 73% of the total power consumption of the processor. If a single link on the 2950W was only 34W, it is clear that the 56W here means that more than a single IF link is being fired up. There are perhaps additional power management opportunities here.
Moving through the stack, you will notice that our 2990WX sample never goes near the 250W rated TDP of the processor, actually barely hitting 180W at times. We are unsure why this is. What we can say is that as loading increases, the total contribution that the non-core power gives does decrease, slowly settling around 36%, varying between 35% and 40% depending on the specific workload. This is a rise up from the 25% we saw in the 2700X and 2950X.
So given that this is the first review with our EPYC 7601 numbers, how about we take it up another notch? While based on the older first generation Zen cores, EPYC has additional memory controllers and IO to worry about, all of which fall under the uncore power category.
Moving into the power consumption numbers, and similar to the 2990WX as we load up all the cores, the values do get a little bit squirrely. However the proportion numbers are staggering.
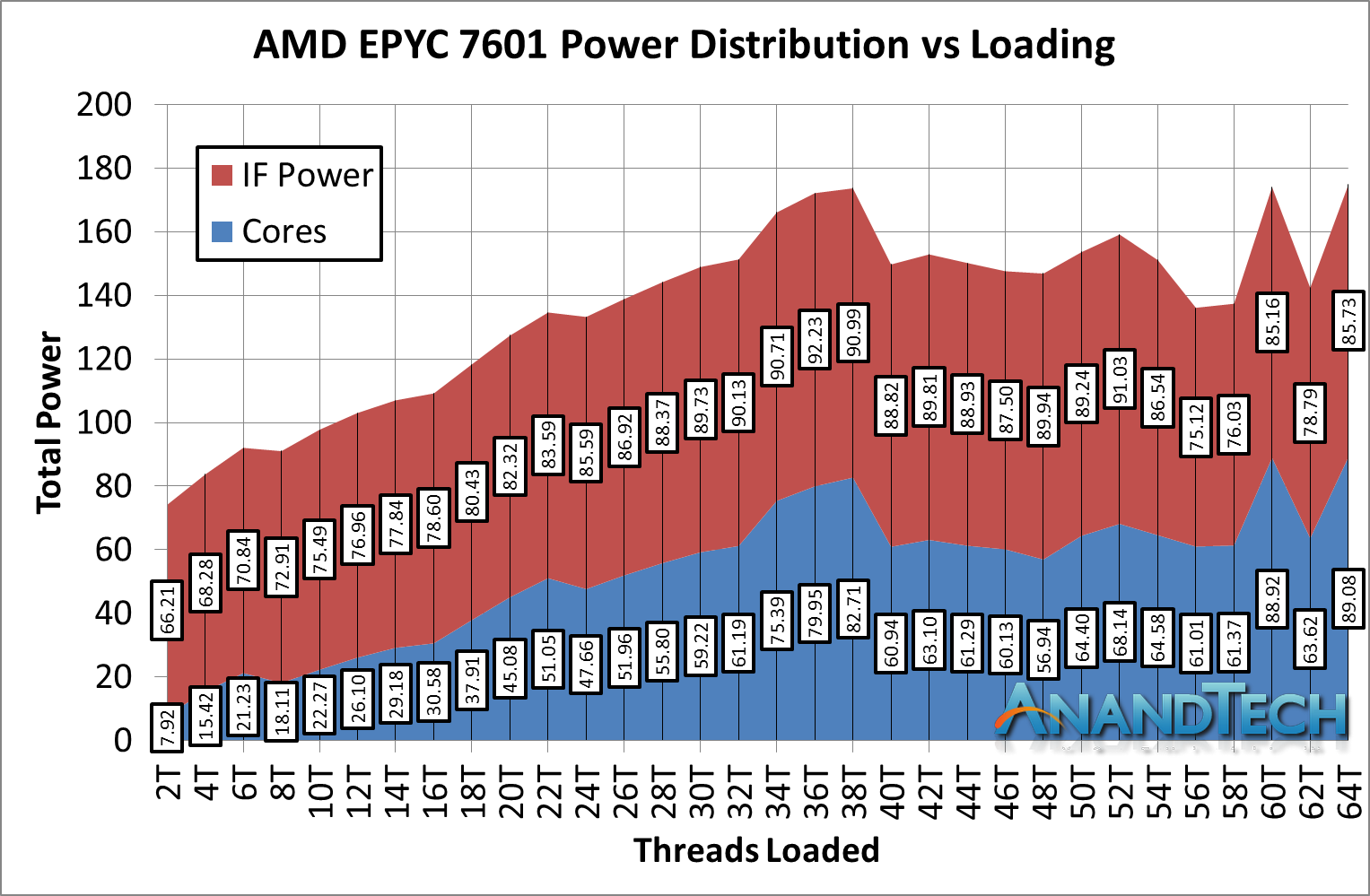
*IF Power should be 'Non-Core' power, which includes IF + DRAM controller + IO
At low loading, out of a total package power of 74.1W, the non-core power consumes 66.2W, or a staggering 89% ! As we go up through the cores, that 66.2W becomes up to 90W in places, but even at its lowest point, the IF accounts for 50% of the power of the total chip. The cores are barely getting 90W out of the 180W TDP!
This raises an interesting point – if we are purely considering the academic merits of one core compared to another, does the uncore power count to that contribution? For a real-world analysis, yes, but for a purely academic one? It also means I can claim the following prophecy:
After core counts, the next battle will be on the interconnect. Low power, scalable, and high performance: process node scaling will mean nothing if the interconnect becomes 90% of the total chip power.








171 Comments
View All Comments
kiphackman - Monday, August 3, 2020 - link
Great review! I really trust your expertise. Please keep them coming. Thank you!https://www.krygerglass.com/locations/missouri/spr...