Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
ThunderX: From Small & Simple to Wide & Complex
As a brief recap, the original ThunderX was an improved version of the Octeon III: a dual-issue in-order CPU core with two short pipelines.
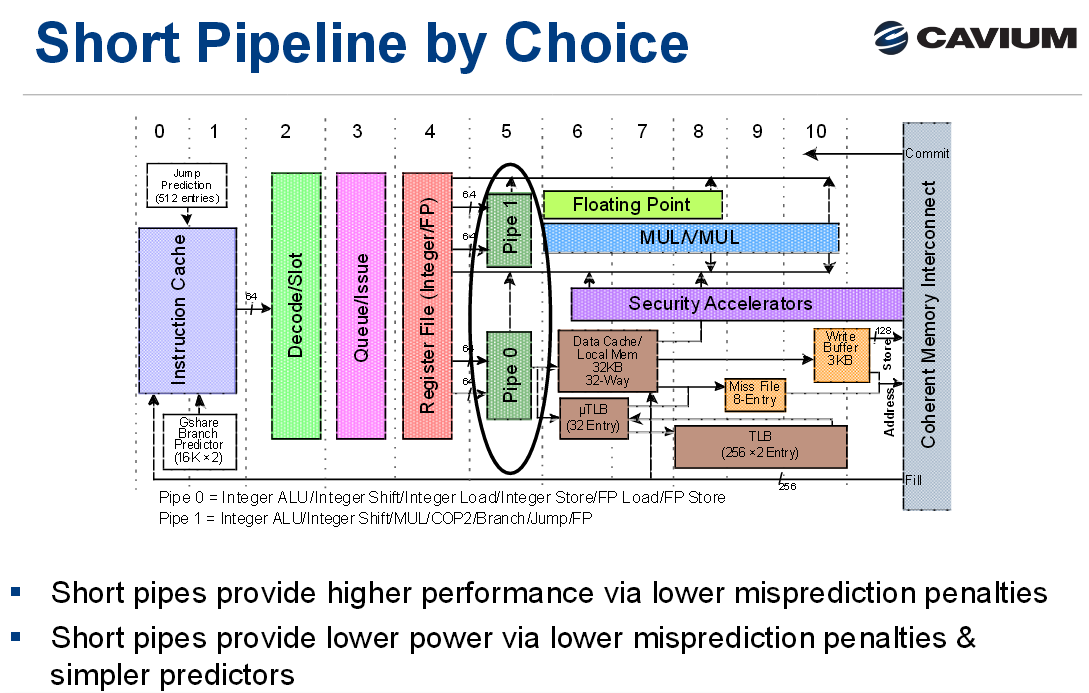
The advantage of the original ThunderX design is that such a simple core can be very energy efficient, especially for "low ILP" (instruction level parallelism) workloads such as web servers and most database servers. Of course, such a short pipeline limits the clockspeed, and such a simple in-order design offers low single threaded performance in medium and high ILP workloads, whereas more advanced out-of-order processors can extract significant parallelism.
Cavium's "New" Core: Vulcan
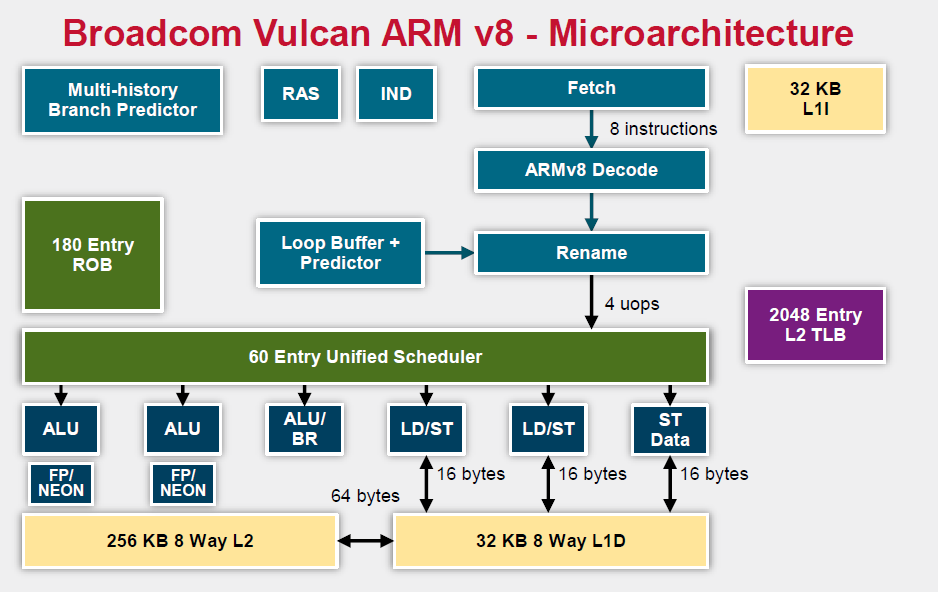
Relative to the original ThunderX, the Vulcan core of the ThunderX2 is an entirely different beast. Announced in 2014 by Broadcom, it is a relatively wide core that runs 4 simultaneous threads (SMT4). As a result, the wide back end should be quite busy even when running low-ILP server workloads.
To make sure that all 4 SMT threads can be sustained, the ThunderX2 front-end can fetch up to 64 bytes from the 8-way set associative 32 KB instruction cache, which is outfitted with a simple next line prefetcher. However, fetching 8 instructions is only possible if there is no taken branch inside those 64 bytes. In that case, the fetch breaks off at the taken branch.
That means that in branch intensive code (databases, AI...) the fetcher will get +/- 5 instructions per clock cycle on average, as one out of 5 instructions is a branch. The fetched instructions are then sent to a smoothing buffer – a buffer where the fetched instructions are held for decoding.
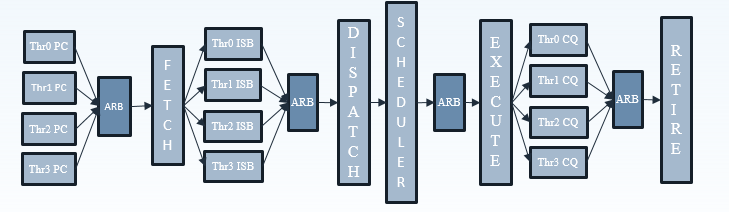
The decoder will then work on a bundle of 4 instructions. Between the decoder and the rename phase each thread has "skid buffer" which consists of 8 bundles. So between the 4 threads up to 32 bundles (128 instructions) can be skid buffered at any one time..
Those 4 instructions – a bundle – travel together through the pipeline until they reach the unified issue queue of the scheduler. Just like Intel has implemented in Nehalem, there is also a loop buffer and predictor, which Intel used to call a "Loop Stream Detector". This loop buffer avoids branch mispredictions and contains decoded µops, which "shortens" the pipeline and reduces the amount of power spent on decoding.
Overall, up to 6 instructions can be executed at the same time. This is divided into 2 ALU/FP/NEON slots, 1 ALU/branch slot, 2 load/store slots (16 bytes), and 1 pure store slot that sends 16 bytes to the D-cache. There is a small (Cavium would not disclose how small) L1 TLB for zero latency translation from Virtual to physical addresses. There is no hardware prefetcher for the L1 D-cache, but the L2 cache has a rather complex hardware prefetcher which is able to recognize patterns (besides being able to stride or fetching the next line).
This is enough to feed the back-end, which can sustain 4 instructions per cycle from 4 different threads.
Micro Architecture Differences
Ultimately Cavium has only published a limited amount of information on the ThunderX2 cores, so there are some limits to our knowledge. But we've gone ahead and summarized some of the key specifications of the different CPU architectures below.
| Feature | Cavium ThunderX2 |
Qualcomm Centriq "Falkor" |
Intel "Skylake"-SP |
AMD EPYC "Zen" |
| L1-I cache Associativity |
32 KB 8-way |
64KB 8-way (+ 24 KB L0) |
32 KB 8-way |
64KB 4-way |
| L1-D cache Associativity |
32 KB 8-way |
32 KB 8-way* |
32 KB 8-way |
32 KB 8-way |
| Load Bandwith | 2x 16B | 2x 16B | 2x 32B | 2x 16B |
| L2-cache | 256 KB 8-way |
256 KB 8-way |
1 MB 16-way |
512 KB 8-way |
| Fetch Width | 8 instructions | 4 instructions | 16 bytes (+/- 4-5 x86) | 32 bytes (+/- 6-8 x86) |
| Issue Queue | 60 | 76 | 97 unified | 6x14 |
| Sustainable Instructions/cycle | 4 | 4 | 5-6 | 4-5 |
| Instructions in Flight | 180 (ROB) | 128 | 224 (ROB) | 192 |
| Int. Pipeline Length |
? |
15 stages | 19 stages 14 stage from µop cache |
19 stages? |
| TLB Instructions TLB Data |
"Small L1" + 2048 unified L2 | ? 64+512 |
128 64 +1536 Unified |
8+64+512 64+1532 |
A detailed analysis is out of the scope of this article. But you can read Ian's analyses of the Falkor, Skylake and Zen architectures here at AnandTech. We limit ourselves to the most obvious differences.
It is pretty clear that Intel's single-threaded performance remains unchallenged: the Skylake core is the widest core, keeps the most instructions in flight, and most importantly runs at the highest clockspeed. The ThunderX2 core is the one that fetches the most instructions per cycle, as it has to be able to keep 4 threads running. The fetch unit will grab 8 instructions from one thread, than grab 8 from the second thread and it will keep cycling between threads. A bad prediction could thus lower the performance of single thread significantly.








97 Comments
View All Comments
DrizztVD - Wednesday, May 23, 2018 - link
It amazes me how the one big advantage ARM could have is the power efficiency, yet no power efficiency numbers in this review? It's like someone just isn't thinking about what can best showcase the ARM advantage and testing it.boeush - Thursday, May 24, 2018 - link
You must have missed this bit:"So as is typically the case for early test systems, we are not able to do any accurate power comparisons.
In fact, Cavium claims that the actual systems from HP, Gigabyte and others will be far more power efficient."
This was an early (and apparently quite buggy, especially from the power management standpoint) test system. It's not representative of final production systems in these respects, so doing what you request on it would only put a very crude lower bound on efficiency, at best.
That's why the final section of the write-up has a title ending in ": so far"... (obviously, there will be more to come if/when real production-quality systems are available for benchmarking/analysis.)
ZolaIII - Thursday, May 24, 2018 - link
It's broken currently on the MB. If you want to see real power/performance metrics for a SoC made on comparable lithography to the lintels 14 nm (aka TSMC 10nm) & with optimised software read this:https://blog.cloudflare.com/neon-is-the-new-black/
drwho9437 - Wednesday, May 23, 2018 - link
Thanks Johan, I've been reading since Ace's. I can't believe it has been more almost 20 years. Even though I don't work in this market I still read everything you write.JohanAnandtech - Friday, May 25, 2018 - link
It was indeed almost 20 years ago that I published my first article about the K6-2 vs Pentium MMX. And Anand's star was about to rise with the launch of the K6-3 :-).Spatz - Wednesday, May 30, 2018 - link
Wow. Aces hardware... that used to be my go to for hardware reviews back in the day. I can’t believe your still at it! This article was great. Keep up the good work.beginner99 - Thursday, May 24, 2018 - link
So it for sure is an option. however I d not get the focus on price. The CPU cost is a small fraction of the total server cost and a tiny if infrastructure cost (network, HVAC,...) is included. Add to that the software and data running on that server and if your CPU is 5% faster at same power it costing $5000 more might be totally worth it.Apple Worshipper - Thursday, May 24, 2018 - link
Errmm... does ARM feature SMT now?Ryan Smith - Thursday, May 24, 2018 - link
Not in Arm's own cores. But in Cavium's ThunderX2, yes.sgeocla - Thursday, May 24, 2018 - link
What's up with EPYC comparison missing in almost all benchmarks?EPYC has been out for a while and the only benchmarks are from almost a year ago?