Assessing Cavium's ThunderX2: The Arm Server Dream Realized At Last
by Johan De Gelas on May 23, 2018 9:00 AM EST- Posted in
- CPUs
- Arm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Cavium
- ThunderX
- ThunderX2
ThunderX: From Small & Simple to Wide & Complex
As a brief recap, the original ThunderX was an improved version of the Octeon III: a dual-issue in-order CPU core with two short pipelines.
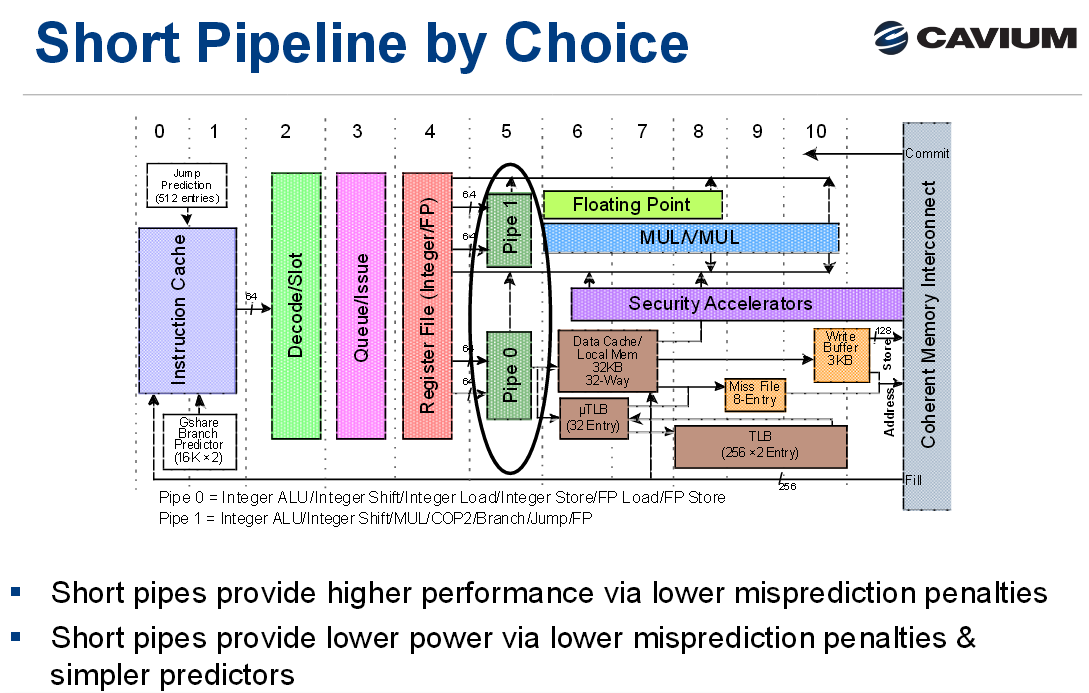
The advantage of the original ThunderX design is that such a simple core can be very energy efficient, especially for "low ILP" (instruction level parallelism) workloads such as web servers and most database servers. Of course, such a short pipeline limits the clockspeed, and such a simple in-order design offers low single threaded performance in medium and high ILP workloads, whereas more advanced out-of-order processors can extract significant parallelism.
Cavium's "New" Core: Vulcan
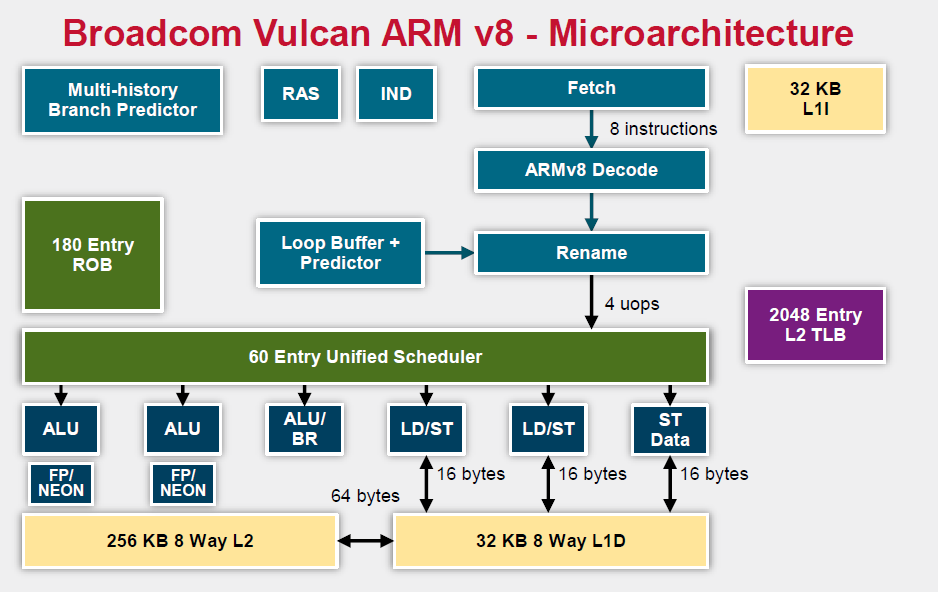
Relative to the original ThunderX, the Vulcan core of the ThunderX2 is an entirely different beast. Announced in 2014 by Broadcom, it is a relatively wide core that runs 4 simultaneous threads (SMT4). As a result, the wide back end should be quite busy even when running low-ILP server workloads.
To make sure that all 4 SMT threads can be sustained, the ThunderX2 front-end can fetch up to 64 bytes from the 8-way set associative 32 KB instruction cache, which is outfitted with a simple next line prefetcher. However, fetching 8 instructions is only possible if there is no taken branch inside those 64 bytes. In that case, the fetch breaks off at the taken branch.
That means that in branch intensive code (databases, AI...) the fetcher will get +/- 5 instructions per clock cycle on average, as one out of 5 instructions is a branch. The fetched instructions are then sent to a smoothing buffer – a buffer where the fetched instructions are held for decoding.
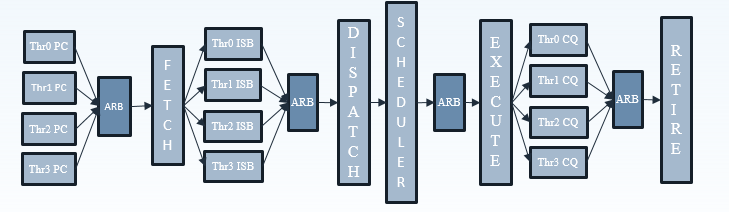
The decoder will then work on a bundle of 4 instructions. Between the decoder and the rename phase each thread has "skid buffer" which consists of 8 bundles. So between the 4 threads up to 32 bundles (128 instructions) can be skid buffered at any one time..
Those 4 instructions – a bundle – travel together through the pipeline until they reach the unified issue queue of the scheduler. Just like Intel has implemented in Nehalem, there is also a loop buffer and predictor, which Intel used to call a "Loop Stream Detector". This loop buffer avoids branch mispredictions and contains decoded µops, which "shortens" the pipeline and reduces the amount of power spent on decoding.
Overall, up to 6 instructions can be executed at the same time. This is divided into 2 ALU/FP/NEON slots, 1 ALU/branch slot, 2 load/store slots (16 bytes), and 1 pure store slot that sends 16 bytes to the D-cache. There is a small (Cavium would not disclose how small) L1 TLB for zero latency translation from Virtual to physical addresses. There is no hardware prefetcher for the L1 D-cache, but the L2 cache has a rather complex hardware prefetcher which is able to recognize patterns (besides being able to stride or fetching the next line).
This is enough to feed the back-end, which can sustain 4 instructions per cycle from 4 different threads.
Micro Architecture Differences
Ultimately Cavium has only published a limited amount of information on the ThunderX2 cores, so there are some limits to our knowledge. But we've gone ahead and summarized some of the key specifications of the different CPU architectures below.
| Feature | Cavium ThunderX2 |
Qualcomm Centriq "Falkor" |
Intel "Skylake"-SP |
AMD EPYC "Zen" |
| L1-I cache Associativity |
32 KB 8-way |
64KB 8-way (+ 24 KB L0) |
32 KB 8-way |
64KB 4-way |
| L1-D cache Associativity |
32 KB 8-way |
32 KB 8-way* |
32 KB 8-way |
32 KB 8-way |
| Load Bandwith | 2x 16B | 2x 16B | 2x 32B | 2x 16B |
| L2-cache | 256 KB 8-way |
256 KB 8-way |
1 MB 16-way |
512 KB 8-way |
| Fetch Width | 8 instructions | 4 instructions | 16 bytes (+/- 4-5 x86) | 32 bytes (+/- 6-8 x86) |
| Issue Queue | 60 | 76 | 97 unified | 6x14 |
| Sustainable Instructions/cycle | 4 | 4 | 5-6 | 4-5 |
| Instructions in Flight | 180 (ROB) | 128 | 224 (ROB) | 192 |
| Int. Pipeline Length |
? |
15 stages | 19 stages 14 stage from µop cache |
19 stages? |
| TLB Instructions TLB Data |
"Small L1" + 2048 unified L2 | ? 64+512 |
128 64 +1536 Unified |
8+64+512 64+1532 |
A detailed analysis is out of the scope of this article. But you can read Ian's analyses of the Falkor, Skylake and Zen architectures here at AnandTech. We limit ourselves to the most obvious differences.
It is pretty clear that Intel's single-threaded performance remains unchallenged: the Skylake core is the widest core, keeps the most instructions in flight, and most importantly runs at the highest clockspeed. The ThunderX2 core is the one that fetches the most instructions per cycle, as it has to be able to keep 4 threads running. The fetch unit will grab 8 instructions from one thread, than grab 8 from the second thread and it will keep cycling between threads. A bad prediction could thus lower the performance of single thread significantly.








97 Comments
View All Comments
imaheadcase - Sunday, May 27, 2018 - link
Yah i tried that for a bit, it worked ok. But was not foolproof, it missed some stuff.repoman27 - Wednesday, May 23, 2018 - link
Just to provide a counter point, this article made my day. And that’s coming entirely from intellectual curiosity—I don’t plan on deploying any servers with these chips in the near future. I always enjoy Johan’s writing, and was really looking forward to seeing how ThunderX2 would stack up. Many people are convinced that ARM is really only suitable in low power / mobile scenarios, but this is the chip that may finally prove otherwise. That has significant ramifications for the entire industry (including the consumer space), especially when you consider that Cavium could put out a TSMC 10nm or even 7nm shrink of ThunderX2 before Intel can get off of 14nm.HStewart - Wednesday, May 23, 2018 - link
This does not proved that ARM is suitable in higher end space - look at the core specific speed - it extremely low compare to Intel and AMD server chips. Keep in mind it takes 128 total cores - running at 4SMT system. And what about other operations - what about Virtual Machine situation - where you have many virtual x86 machines on VMWare server,How about high end mathematical and vector logic?
It does seem like ARM can run more threads - but maybe Intel or AMD has never had the need to
I think this latest Core battle is silly - I think it really not the number of cores you have but combination of type and speed of cores along with number of cores.
Wilco1 - Wednesday, May 23, 2018 - link
It certainly does prove that Arm can do high end servers - the results clearly show IPC/GHz is very close on SPECINT. Base clock speeds are the same as the Intel cores, and that's the speed the server runs at when not idle. But there are more cores as you say, so who will win is obvious.Now imagine a next-gen 7nm version before Intel manages 10nm. Not a pretty picture, right?
HStewart - Wednesday, May 23, 2018 - link
Ok I have learn to agree to disagree with some peopleCan this server run the VMWare server
https://kb.vmware.com/s/article/1003882
The answer is no - just one example - many more,
On 10nm - it not number that matters - it technology behind it - Intel supposely has a i3 and Y based for CannonLake coming this year - probably more.
Wilco1 - Wednesday, May 23, 2018 - link
There are plenty of VMs for Arm, so virtualization is not an issue.10nm will be behind 7nm even if it ends up as originally promised and not using relaxed rules to become viable for volume production.
ZolaIII - Thursday, May 24, 2018 - link
When optimized for SIMD NEON extension things changed dramatically. All tho NEON isn't exactly the best SIMD never the less number's speak for them self.https://blog.cloudflare.com/neon-is-the-new-black/
Tho Centriq is a bit pricier, bit overly slower than this but main point is it whose built on comparable lithography to current Intel's 14nm. So you get cheaper hardware, which can be packaged tighter & will consume much less power while being compatible regarding the performance. Triple win situation (initial cost, cost of ownership and scaling) but it still isn't turn key one whit isn't crucial for big vendor server farms anyway.
name99 - Thursday, May 24, 2018 - link
ARM (and this particular chip) aren't trying to solve every problem in the world. They're trying to offer a better (cheaper) solution for a PARTICULAR subset of customers.If you think such customers don't exist, then why do you think Intel has such a wide range of Xeons, including eg all those Xeon Silvers that only turbo up to 3GHz? Or Xeon Gold's that max out at 2.8GHz?
lmcd - Thursday, May 24, 2018 - link
Second page: supports SR-IOV, which is important for KVM and Xen. If you're not aware, Xen and KVM are powerful virtualization solutions that cover the feature set of VMWare quite nicely.HStewart - Wednesday, May 23, 2018 - link
"I really think Anandtech needs to branch into different websites. Its very strange and unappealing to certain users to have business/consumer/random reviews/phone info all bunched together."I different in this - I don't think AnandTech should concentrate on just gaming in focus - this is rather old school - I am not sure about mobile phones in the mess of all this
But comparing ARM cpu's to Intel/AMD is interesting subject. It basically RISC vs CISC discussion - yes RISC can do operations quicker in some cases - but by definition of the architecture they are Reduce in what they do. Fox example it would take RISC a ton of instructions to executed a single AVX style operation.
This article is closest I have seen in comparing ARM vs x86 base machines - but even though I see some holes - it comes close - but having just be Linux based leaves out why people purchase such machine - I think Virtual Machine server is huge - but like everything else on the internet that is just an opinion