HiSilicon Kirin 970 - Android SoC Power & Performance Overview
by Andrei Frumusanu on January 22, 2018 9:15 AM ESTNPU Performance Tested
To test the performance of the NPU we need a benchmark which currently targets all of the various vendor APIs. Unfortunately at this stage short of developing our own implementation the choices are scarce, but luckily there is one: Popular Chinese benchmark suite Master Lu recently introduced an AI benchmark implementing both HiSilicon’s HiAI as well as Qualcomm’s SNPE frameworks. The benchmarks implements three different neural network models: VGG16, InceptionV3 as well as ResNet34. The input dataset are 100 images which are a subset of the ImageNet reference database. As a fall-back the app implements the TensorFlow inferencing library to run on the CPU. I’ve ran the performance figures on the Mate 10 Pro, Mate 9 as well as two Snapdragon 835 (Pixel 2 XL & V30) devices respectively running on the CPU as well as the Hexagon DSP.

Similarly to the SPEC2006 results I chose to use a more complex graph to better showcase the three dimensions of average power (W), efficiency (mJ/inference) as well as absolute performance (fps / inferences per second).
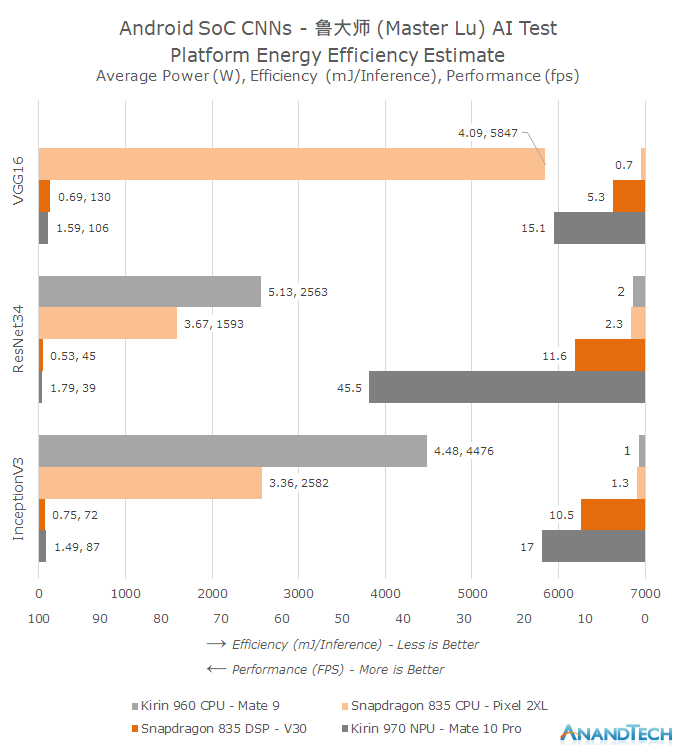
First thing we notice from the graph is that we can observe an order of magnitude difference in performance between the NPU and CPU implementations. Running the networks as they are on the CPUs we’re not able to exceed 1-2fps and we do so at very heavy CPU power consumption. Both the Snapdragon 835 as well as the Kirin 960 CPUs struggle with the workloads with average power exceeding sustainable workloads.
Qualcomm’s Hexagon DSP is able to improve on the CPU performance by a factor of 5-8x. But Huawei’s NPU performance figures are again several factors above that, showcasing up to a 4x lead in ResNet34. The reason for the different performance ratio differences between the different models is their design. Convolutional layers are heavily parallelisable whilst the polling and fully connected layers of the models must use more serial processing steps. ResNet in particular makes use of a larger percentage of convolution processing for a single inference and thus is able to achieve a higher utilization rate of the Kirin NPU.

In terms of power efficiency we’re very near to Huawei’s claims of up to a 50x improvement. This is the key characteristic that will enable CNNs to be used in real-world use-cases. I was quite surprised to see Qualcomm’s DSP reach similar efficiency levels as Huawei’s NPU – albeit at 1/3rd to 1/4th of the performance. This should bode quite well in terms of the Snapdragon 845’s Hexagon 685 which promises up to a 3x increase in performance.
I wanted to take the opportunity to make a rant about Google’s Pixel 2: I was able to actually run the benchmark on the Snapdragon 835’s CPU because the Pixel 2 devices lacked support for the SNPE framework. This was in a sense maybe both expected as well as unexpected. With the introduction of the NN API in Android 8.1, which the Pixel 2 phones support and use acceleration through the dedicated Pixel Visual Core SoC, it’s natural that Google would want to push usage of Android’s standard APIs. But on the other hand this is also a limitation on the capabilities of the phone by the OEM vendor which I can’t help but compare to the decision by Google to by default omit OpelCL in Android. This is a decision which in my eyes has heavily stifled the ecosystem and is why we don’t see more GPU accelerated compute workloads, out of which CNNs could have been one.
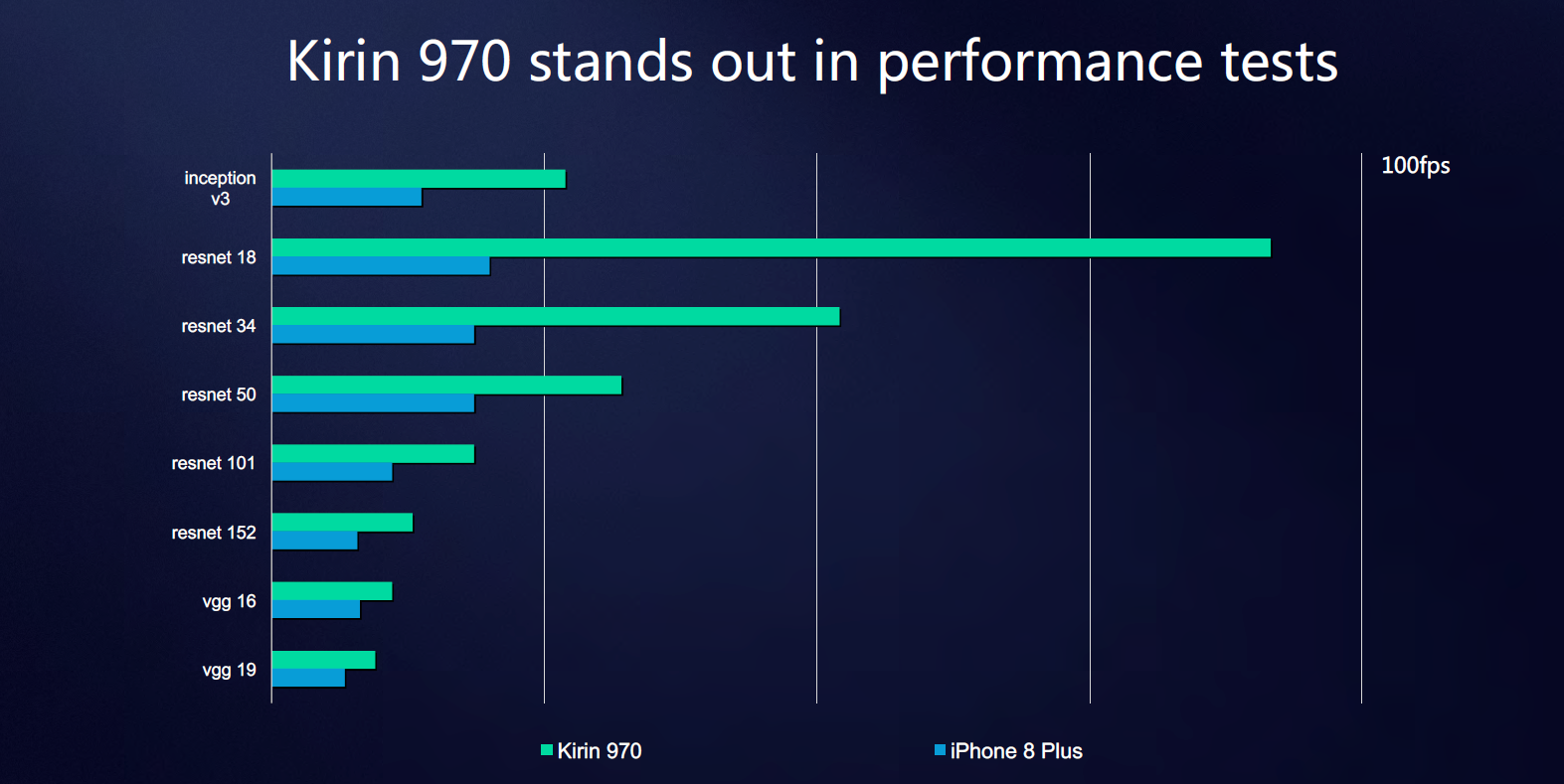
While we can’t run the Master Lu AI test on an iPhone, HiSilicon did publish some slides with reported internally numbers we can try to correlate. Based on the models included in the slide, the Apple A11 neural network IP’s performance should land somewhere slightly ahead of the Snapdragon 835’s DSP but still far behind the Kirin NPU, but again we can't independently verify these figures due to lack of a fitting iOS benchmark we can run ourselves.

Of course the important question is, what is this all good for? HiSilicon discloses that one use-case being used is noise reduction via CNN processing, and thus is able to increase voice recognition rate in heavy traffic from 80% to 92%.

The other most publicised use-case is the implementation in the camera app. The Mate 10’s camera makes use of the NPU to run inferencing to recognize different scenarios and optimize the camera settings based on pre-sets for those scenarios. The Mate 10 comes with a translation app which was developed with Microsoft, which is able to use the NPU for accelerated offline translation, and this was definitely the single most impressive usage for me. Inside the built-in gallery application we also see the use of image classification to create a new section where pictures are organized by content type. The former scenarios where the SoC is doing live inferencing on a media stream such as the camera feed is also the use-case where HiSilicon has an advantage over Qualcomm as employs both a DSP and the NPU whereas Snapdragon SoCs have to share the DSP resources between vision processing and neural network inferencing workloads.
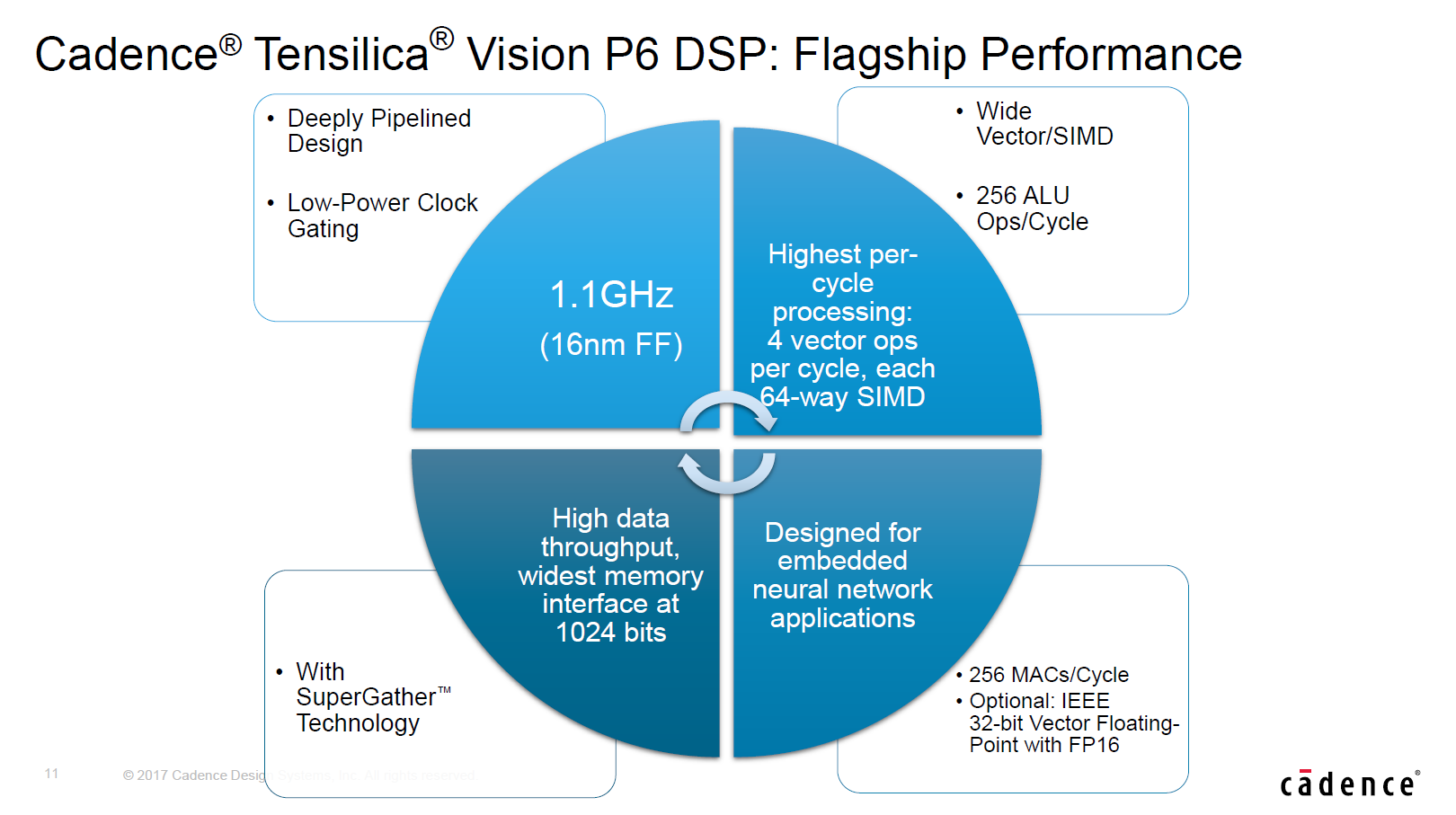
Oddly enough the Kirin 970 has sort of double the silicon IP capable of running neural network efficiently as its vision pipeline also includes a Cadence Tensilica Vision P6 DSP which should be in the same performance class as Qualcomm’s Hexagon 680 DSP, but is currently not exposed for user applications.
While the Mate 10 does make some use of the NPU it’s hard to argue that it’s a definitive differentiating factor for the end-user. Currently neural network usage in mobile doesn’t seem to have the same killer-applications that they have in automotive and security camera sectors. Again this is due to the ecosystem being its early days and the Mate 10 among the first devices to actually offer such a dedicated acceleration block. It’s arguable if it’s worth it for the Kirin 970 to have implemented such a piece and Huawei is very open about the fact that it’s reaching out to developers to try and find more use-cases for the silicon, and at least Huawei should be lauded for innovating with something new.
Huawei/Microsoft's translation app seemed to be the most distinguished experience on the Mate 10 so maybe there’s more non-image based use-cases that can be explored in the future. Currently the app allows the traditional snapshot of a foreign language text and then shows a translated overlay, but imagine a future implementation where it’s able to do it live from the camera feed and allow for an AR experience. MediaTek at CES also showed a distinguishing use-case of using CNNs: for video conferencing the video encoder is fed metadata on scene composition by a CNN layer doing image recognition and telling the encoder to use finer-grained block sizes where a user’s face would be, thus increasing video quality. It’s more likely that neural network use-cases will slowly creep up with time rather than there being a new revolutionary thing, as more devices will start to incorporate such IPs and they become more widespread so will developers be more enticed to find uses for them.








116 Comments
View All Comments
GreenReaper - Thursday, January 25, 2018 - link
If it can do 2160p60 Decode then I'd imagine that of course it can do 2160p30 Decode, just as it can do 1080p60/30 decode. You list the maximum in a category.yhselp - Tuesday, January 23, 2018 - link
What a wonderful article: a joy to read, thoughtful, and very, very insightful. Thank you, Andrei. Here's to more coverage like that in the future.It looks like the K970 could be used in smaller form factors. If Huawei were to make a premium, bezel-less ~ 4.8" 18:9 model power by K970, it would be wonderful - a premium, Android phone about the size of the iPhone SE.
Even though Samsung and Qualcomm (S820) have custom CPUs, it feels like their designs are much closer to stock ARM than Apple's CPUs. Why are they not making wider designs? Is it a matter of inability or unwillingness?
Raqia - Tuesday, January 23, 2018 - link
Props for a nice article with data rich diagrams filled with interesting metrics as well as the efforts to normalize tests now and into the future w/ LLVM + SPECINT 06. (Adding the units after the numbers in the chart and "avg. watts" to the rightward pointing legend at the bottom would have helped me grok faster...) Phones are far from general purpose compute devices and their CPUs are mainly involved in directing program flow rather than actual computation, so leaning more heavily into memory operations with the larger data sets of SPECINT is a more appropriate CPU test than Geekbench. The main IPC uplift from OoOE comes from the prefetching and execution in parallel of the highest latency load and store operations and a good memory/cache subsystem does wonders for IPC in actual workloads. Qualcomm's Hexagon DSP hasIt would be interesting to see the 810 here, but its CPU figures would presumably blow off the chart. A modem or wifi test would also be interesting (care for a donation toward the aforementioned harness?), but likely a blowout in the good direction for the Qualcomm chipsets.
Andrei Frumusanu - Friday, January 26, 2018 - link
Apologies for the chart labels, I did them in Excel and it doesn't allow for editing the secondary label position (watts after J/spec).The Snapdragon 810 devices wouldn't have been able to sustain their peak performance states for SPEC so I didn't even try to run it.
Unless your donation is >$60k, modem testing is far beyond the reach of AT because of the sheer cost of the equipment needed to do this properly.
jbradfor - Wednesday, January 24, 2018 - link
Andrei, two questions on the Master Lu tests. First, is there a chance you could run it on the 835 GPU as well and compare? Second, do these power number include DRAM power, or are they SoC only? If they do not include DRAM power, any chance you could measure that as well?Andrei Frumusanu - Friday, January 26, 2018 - link
The Master Lu uses the SNPE framework and currently doesn't have the option to chose computing target on the SoC. The GPU isn't any or much faster than the DSP and is less efficient.The power figures are the active power of the whole platform (total power minus idle power) so they include everything.
jbradfor - Monday, January 29, 2018 - link
Thanks. Do you have the capability of measuring just the SoC power separately from the DRAM power?ReturnFire - Wednesday, January 24, 2018 - link
Great article Andrei. So glad there is new mobile stuff on AT. Fingers crossed for more 2018 flagship / soc articles!KarlKastor - Thursday, January 25, 2018 - link
"AnandTech is also partly guilty here; you have to just look at the top of the page: I really shouldn’t have published those performance benchmarks as they’re outright misleading and rewarding the misplaced design decisions made by the silicon vendors. I’m still not sure what to do here and to whom the onus falls onto."That is pretty easy. Post sustained performace values and not only peak power. Just run the benchmarks ten times in a row, it's not that difficult.
If in every review sustained performance is shown, the people will realize this theater.
And it is a big problem. Burst GPU performance is useless. No one plays a game for half a minute.
Burst CPU performance ist perhaps a different matter. It helps to optimize the overall snappiness.
Andrei Frumusanu - Friday, January 26, 2018 - link
I'm planning to switch to this in future reviews.