The AnandTech Coffee Lake Review: Initial Numbers on the Core i7-8700K and Core i5-8400
by Ian Cutress on October 5, 2017 9:00 AM EST- Posted in
- CPUs
- Intel
- Core i5
- Core i7
- Core i3
- 14nm
- Coffee Lake
- 14++
- Hex-Core
- Hyperthreading
Benchmarking Performance: CPU System Tests
Our first set of tests is our general system tests. These set of tests are meant to emulate more about what people usually do on a system, like opening large files or processing small stacks of data. This is a bit different to our office testing, which uses more industry standard benchmarks, and a few of the benchmarks here are relatively new and different.
All of our benchmark results can also be found in our benchmark engine, Bench.
Strategic AI
One of the hot button topics this year (and for the next few years, no doubt) is how technology is shifting to using artificial intelligence and purpose built AI hardware to perform better analysis in low power environments. AI is not relatively new as a concept, as we have had it for over 50 years. What is new is the movement to neural network based training and inference: moving from ‘if this then that’ sort of AI to convolutional networks that can perform fractional analysis of all the parameters.
Unfortunately the movement of the neural-network ecosystem is fast paced right now, especially in software. Every few months or so, announcements are made on new software frameworks, improvements in accuracy, or fundamental paradigm shifts in how these networks should be calculated for accuracy, power, performance, and what the underlying hardware should support in order to do so. There is no situational AI benchmarking tools using network topologies that will remain relevant in 2-4 months, let alone an 18-24 month processor benchmark cycle. So to that end our AI test becomes the best of the rest: strategic AI in the latest video games.
For our test we use the in-game Civilization 6 AI benchmark with a few custom modifications. Civilization is one of the most popular strategy video games on the market, heralded for its ability for extended gameplay and for users to suddenly lose 8 hours in a day because they want to play ‘one more turn’. A strenuous setting would involve a large map with 20 AI players on the most difficult settings, leading to a turn time (waiting for the AI players to all move in one turn) to exceed several minutes on a mid-range system. Note that a Civilization game can easily run for over 500 turns and be played over several months due to the level of engagement and complexity.
Before the benchmark is run, we change the game settings for medium visual complexity at a 1920x1080 resolution while using a GTX 1080 graphics card, such that any rendered graphics are not interfering with the benchmark measurements. Our benchmark run uses a command line method to call the built-in AI benchmark, which features 8 AI players on a medium size map but in a late game scenario with most of the map discovered, each civilization in the throes of modern warfare. We set the benchmark to play for 15 turns, and output the per-turn time, which is then read into the script with the geometric mean calculated. This benchmark is newer than most of the others, so we only have a few data points so far:
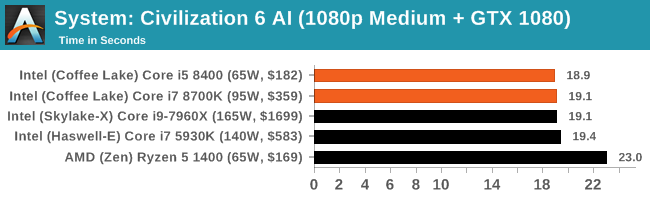
Our Strategic AI test is new to the scene, and it looks like there is at least an asymptotic result wken you have a 'good enough' processor.
PDF Opening
First up is a self-penned test using a monstrous PDF we once received in advance of attending an event. While the PDF was only a single page, it had so many high-quality layers embedded it was taking north of 15 seconds to open and to gain control on the mid-range notebook I was using at the time. This put it as a great candidate for our 'let's open an obnoxious PDF' test. Here we use Adobe Reader DC, and disable all the update functionality within. The benchmark sets the screen to 1080p, opens the PDF to in fit-to-screen mode, and measures the time from sending the command to open the PDF until it is fully displayed and the user can take control of the software again. The test is repeated ten times, and the average time taken. Results are in milliseconds.

Single thread frequency usualy works well for PDF Opening, although as we add on more high performance cores it becomes more difficult for the system to pin that individual thread to a single core and get the full turbo boost - if anything flares up on any other core then it brings the frequencies down. I suspect that is what is happening here and the next couple of thests where the i7-8700K sits behind the i7-7700K and i7-7740X.
FCAT Processing: link
One of the more interesting workloads that has crossed our desks in recent quarters is FCAT - the tool we use to measure stuttering in gaming due to dropped or runt frames. The FCAT process requires enabling a color-based overlay onto a game, recording the gameplay, and then parsing the video file through the analysis software. The software is mostly single-threaded, however because the video is basically in a raw format, the file size is large and requires moving a lot of data around. For our test, we take a 90-second clip of the Rise of the Tomb Raider benchmark running on a GTX 980 Ti at 1440p, which comes in around 21 GB, and measure the time it takes to process through the visual analysis tool.
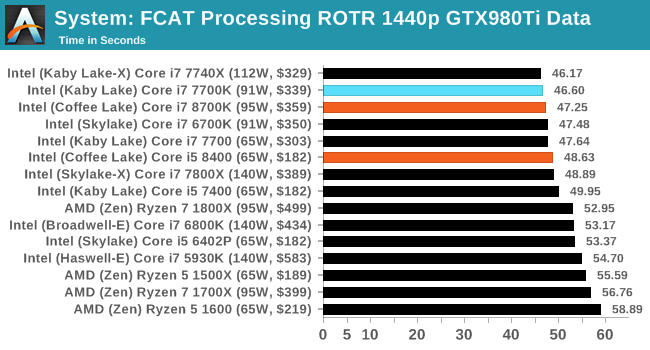
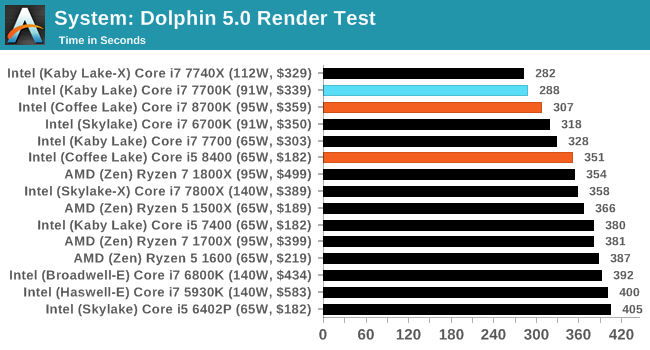
Dolphin Benchmark: link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in minutes, where the Wii itself scores 17.53 minutes.
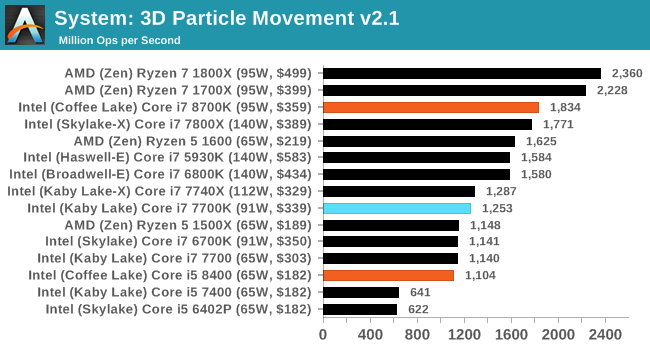
3D Movement Algorithm Test v2.1: link
This is the latest version of the self-penned 3DPM benchmark. The goal of 3DPM is to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in. It affords a ~25% speed-up over v2.0, which means new data.
DigiCortex v1.20: link
Despite being a couple of years old, the DigiCortex software is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation. The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
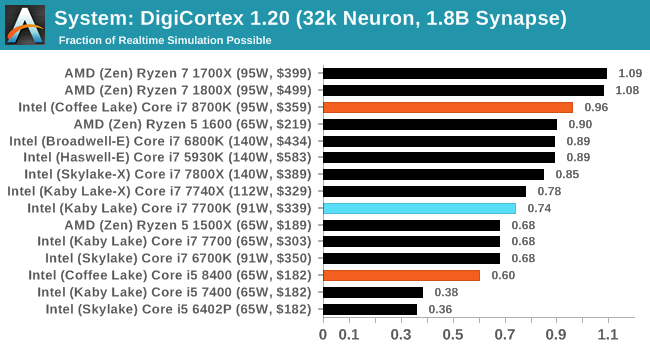
DigiCortex can take advantage of the extra cores, paired with the faster DDR4-2666 memory. The Ryzen 7 chips still sit at the top here however.
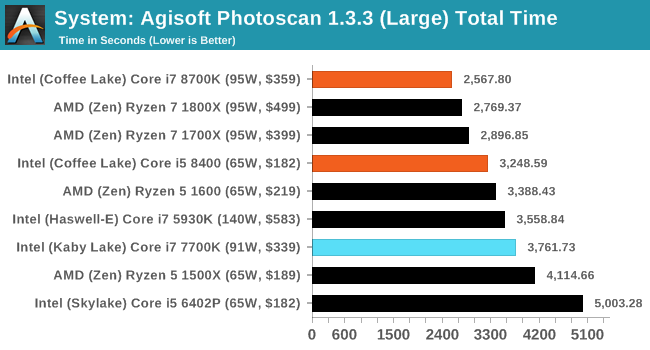
Agisoft Photoscan 1.3.3: link
Photoscan stays in our benchmark suite from the previous version, however now we are running on Windows 10 so features such as Speed Shift on the latest processors come into play. The concept of Photoscan is translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the model. The algorithm has four stages, some single threaded and some multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures. The 1.3.3 test is relatively new, so has only been run on a few parts so far.








222 Comments
View All Comments
boeush - Friday, October 6, 2017 - link
To expand on this a bit more, with the "core wars" now in effect, I wonder if hyperthreading might be an unnecessary holdover feature that could be actually reducing performance of many(8+)-core chips in all but the most extremely threaded scenarios. Might it not be better to have many simple/efficient cores, rather than perhaps fewer cores loaded with the hyperthreading overhead both in terms of die area and energy density, as well as cache thrashing?Zingam - Saturday, October 7, 2017 - link
Hyperthreading was invented to optimize the use of CPU logic that would otherwise remain unutilized during high loads.There is no way of reducing performance with current architectures. There are "hyperthreading-less" CPUs and you compare them to hyperthreded CPUs.boeush - Monday, October 9, 2017 - link
Hyperthreading was particularly useful in the context of not having a lot of cores to work with - allowing to squeeze extra multi-threaded performance from your dual- or quad-core CPU. It comes at the cost of extra silicon and complexity in the CPU pipeline, but allows better utilization of CPU resources as you mention. At runtime, it has the dual detrimental effects on single-thread performance, of (1) splitting/sharing the on-CPU cache among more threads, thereby raising the frequency of cache misses for any given thread due to the threads trampling over each other's cached data, and (2) indeed maximizing CPU resource utilization, thereby maximizing dissipated energy per unit area - and thereby driving the CPU into a performance-throttling regime.With more cores starting to become available per CPU in this age of "core wars", it's no longer as important to squeeze every last ounce of resource utilization from each core. Most workloads/applications are not very parallelizable in practice, so you end up hitting the limits of Amdahl's law - at which point single-thread performance becomes the main bottleneck. And to maximize single-thread performance on any given core, you need two things: (a) maximum attainable clock frequency (resource utilization be damned), and (b) as much uncontested, dedicated on-CPU cache as you can get. Hyperthreading is an impediment to both of those goals.
So, it seems to me that if we're going toward the future where we routinely have CPUs with 8 or more cores, then it would be beneficial for each of those cores to be simpler, more compact, more streamlined and optimized for single-thread performance (while foregoing hyperthreading support), while spending any resulting die space savings on more cores and/or more cache.
boeush - Monday, October 9, 2017 - link
To add to the above: 'more cores and/or more cache' - and/or better branch predictor, and/or faster/wider ALU and/or FPU, and/or more pipeline stages to support a faster clock, and/or...alinypd - Saturday, October 7, 2017 - link
Slowest GAMING CPU Ever, Garbage!yhselp - Saturday, October 7, 2017 - link
The i3-8100 is made utterly redundant by the the necessity to buy a Z370 motherboard along with it; it'd be cheaper to get an i5-7400 with a lower-end motherboard. Intel...watzupken - Saturday, October 7, 2017 - link
This applies to all the non-overclocking chips, particularly i5 and below. The high cost of the Z370 boards currently simply wipe out any price benefits. For example, a i5 840 is good value for money, but once you factor in the price of a motherboard with a Z370 chipset, it may not be that good value for money anymore.FourEyedGeek - Saturday, October 7, 2017 - link
Enjoyed the article, thanks. An overclocked Ryzen 1700 looks appealing.nierd - Saturday, October 7, 2017 - link
"The problem here is *snip* Windows 10, *snip* All it takes is for a minor internal OS blip and single-threaded performance begins to diminish. Windows 10 famously kicks in a few unwanted instruction streams when you are not looking,"This is why single threaded performance is a silly benchmark in today's market, unless you happen to boot to DOS to run something. Your OS is designed to use threads. There are no systems in use today as a desktop (in any market these processors will compete - even if used as a server) where they will ever run a single thread. The only processors that run single threads today are ... single core processors (without hyperthreading even).
Open your task manager - click the performance tab - look at the number of threads - when you have enough cores to match that number then single threaded performance is important. In the real world how the processor handles multiple tasks and thread switching is more important. Even hardcore gamers seem to miss this mark forgetting that behind the game the OS has threads for memory management, disk management, kernel routines, checking every piece of hardware in your system, antivirus, anti-malware (perhaps), network stack management, etc. That's not even counting if you run more than one monitor and happen to have web browsing or videos playing on another screen - and anything in the background you are running.
The myth that you never need more than 4 cores is finally coming to rest - lets start seeing benchmarks that stress a system with 10 programs going in the background. My system frequently will be playing a movie, playing a game, and running handbrake in the background while it also serves as a plex server, runs antivirus, has 32 tabs open in 2 different browsers, and frequently has something else playing at the same time - A true benchmark would be multiple programs all tying up as many resources as possible - while a single app can give a datapoint I want to see how these new multi-core beasts handle real world scenarios and response times.
coolhardware - Sunday, October 8, 2017 - link
Your comment has merit. It is crazy the number of tasks running on a modern OS. I sometimes miss the olden days where a clean system truly was clean and had minimal tasks upon bootup. ;-)