Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Floating Point
Normally our HPC benchmarking is centered around OpenFoam, a CFD software we have used for a number of articles over the years. However, since we moved to Ubuntu 16.04, we could not get it to work anymore. So we decided to change our floating point intensive benchmark for now. For our latest article, we're testing with C-ray, POV-Ray, and NAMD.
The idea is to measure:
- A FP benchmark that is running out of the L1 (C-ray)
- A FP benchmark that is running out of the L2 (POV-Ray)
- And one that is using the memory subsytem quite often (NAMD)
Floating Point: C-ray
C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out of the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing.
We use the standard benchmarking resolution (3840x2160) and the "sphfract" file to measure performance. The binary was precompiled.
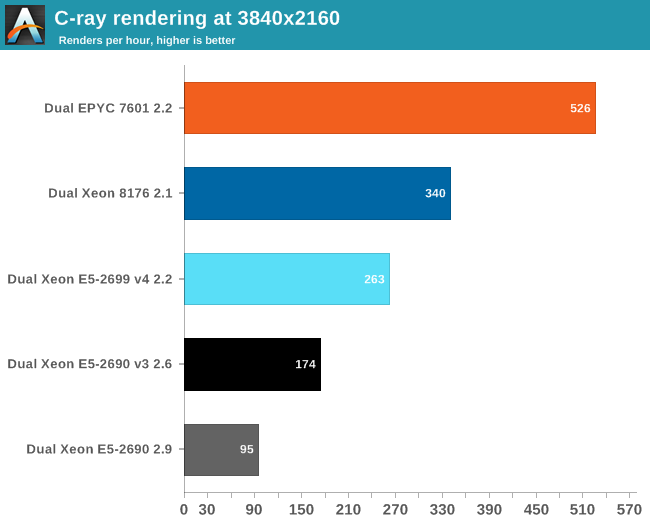
Wow. What just happened? It looks like a landslide victory for the raw power of the four FP pipes of Zen: the EPYC chip is no less than 50% faster than the competition. Of course, it is easy to feed FP units if everything resides in the L1. Next stop, POV-Ray.
Floating Point: POV-Ray 3.7
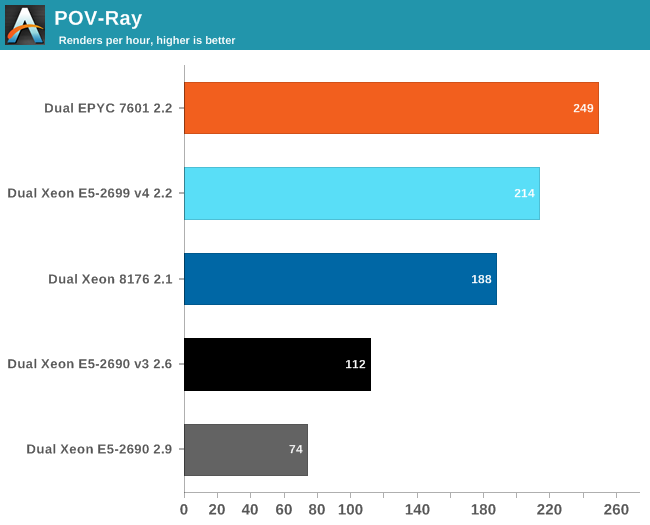
POV-Ray is known to run mostly out of the L2-cache, so the massive DRAM bandwidth of the EPYC CPU does not play a role here. Nevertheless, the EPYC CPU performance is pretty stunning: about 16% faster than Intel's Xeon 8176. But what if AVX and DRAM access come in to play? Let us check out NAMD.
Floating Point: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX.
First, we used the "NAMD_2.10_Linux-x86_64-multicore" binary. We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
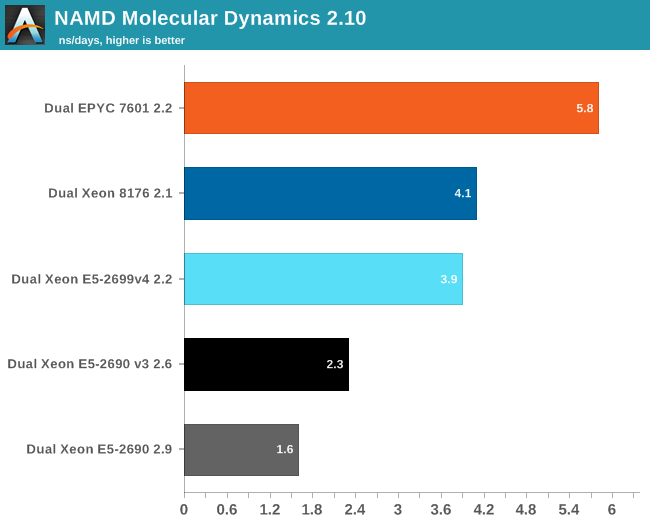
Again, the EPYC 7601 simply crushes the competition with 41% better performance than Intel's 28-core. Heavily vectorized code (like Linpack) might run much faster on Intel, but other FP code seems to run faster on AMD's newest FPU.
For our first shot with this benchmark, we used version 2.10 to be able to compare to our older data set. Version 2.12 seems to make better use of "Intel's compiler vectorization and auto-dispatch has improved performance for Intel processors supporting AVX instructions". So let's try again:
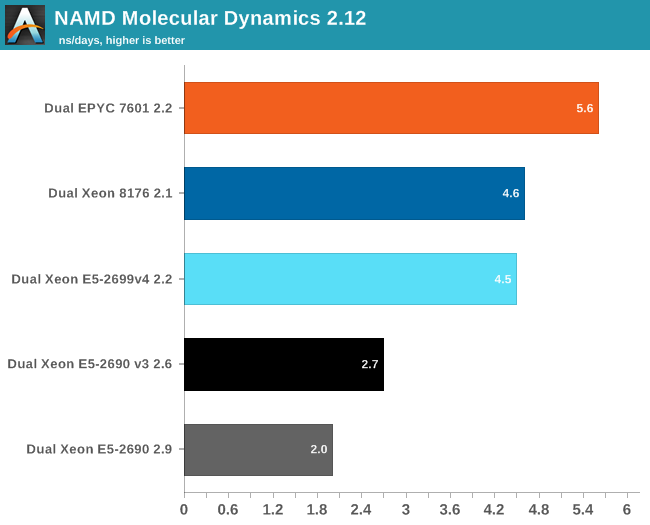
The older Xeons see a perforance boost of about 25%. The improvement on the new Xeons is a lot lower: about 13-15%. Remarkable is that the new binary is slower on the EPYC 7601: about 4%. That simply begs for more investigation: but the deadline was too close. Nevertheless, three different FP tests all point in the same direction: the Zen FP unit might not have the highest "peak FLOPs" in theory, there is lots of FP code out there that runs best on EPYC.








219 Comments
View All Comments
tamalero - Tuesday, July 11, 2017 - link
How is that different if AMD ran stuff that is extremely optimized for them?Friendly0Fire - Tuesday, July 11, 2017 - link
That's kinda the point? You want to benchmark the CPUs in optimal scenarios, since that's what you'd be looking at in practice. If one CPU's weakness is eliminated by using a more recent/tweaked compiler, then it's not a weakness.coder543 - Tuesday, July 11, 2017 - link
Rather, you want to test under practical scenarios. Very few people are going to be running 17.04 on production grade servers, they will run an LTS release, which in this case is 16.04.It would be good to have benchmarks from 17.04 as another point of comparison, but given how many things they didn't have time to do just using 16.04, I can understand why they didn't use 17.04.
Santoval - Wednesday, July 12, 2017 - link
A compromise can be found by upgrading Ubuntu 16.04's outdated kernel. Ubuntu LTS releases include support for rolling HWE Stacks, which is a simple meta package for installing newer kernels compiled, modified, tested and packaged by the Ubuntu Kernel Team, and installed directly from the official Ubuntu repositories (not via a Launchpad PPA). With HWE 16.04 LTS can install up to the kernel of 18.04 LTS.I also use 16.04 LTS + HWE (it just requires installing the linux-generic-hwe-16.04 package), which currently provides the 4.8 kernel. There is even a "beta" version of HWE (the same package plus an -edge at the end) for installing the 4.10 kernel (aka the kernel of 17.04) earlier, which will normally be released next month.
I just spotted various 4.10 kernel listings after checking in Synaptic, so they must have been added very recently. After that there are two more scheduled kernel upgrades, as is shown in the following link. Of course HWE upgrades solely the kernel, it does not upgrade any application or any of the user level parts to a more recent version of Ubuntu.
https://wiki.ubuntu.com/Kernel/RollingLTSEnablemen...
CajunArson - Tuesday, July 11, 2017 - link
Considering the similarities between RyZen and Haswell (that aren't coincidental at all) you are already seeing a highly optimized set of RyZen results.But I have no problem seeing RyZen be tested with the newest distros, the only difference being that even Ubuntu 16.04 already has most of the optimizations for RyZen baked in.
coder543 - Tuesday, July 11, 2017 - link
What similarities? They're extremely different architectures. I can't think of any obvious similarities. Between the CCX model, caches being totally different layouts, the infinity fabric, Intel having better AVX-256/512 stuff (IIRC), etc.I don't think 16.04 is naturally any more optimized for Ryzen than it is for Skylake-SP.
CajunArson - Tuesday, July 11, 2017 - link
Oh please, at the core level RyZen is a blatant copy-n-paste of Haswell with the only exception being they just omitted half the AVX hardware to make their lives easier.It's so obvious that if you followed any of the developer threads for people optimizing for RyZen they say to just use the Haswell compiler optimizations that actually work better than the official RyZen optimization flags.
ddriver - Tuesday, July 11, 2017 - link
Can't tell if this post is funny or sad.CajunArson - Tuesday, July 11, 2017 - link
It's neither: It's accurate.Don't believe me? Look at the differences in performance of the holy 1800X over multiple Linux distros ranging from pretty new (OpenSuse Tumbleweed) to pretty old (Fedora 23 from 2015): http://www.phoronix.com/scan.php?page=article&...
Nowhere near the variation that we see with Skylake X since Haswell was already a solved problem long before RyZen lauched.
coder543 - Tuesday, July 11, 2017 - link
Right, of course. Ryzen is a copy-and-paste of Haswell.Don't make me laugh.