Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Intel’s Turbo Modes
A last minute detail from Intel yesterday was information on the Turbo modes. As expected, not all of the processors actually run at their rated/base frequency: most will apply a series of turbo modes depending on how many cores are registered as ‘active’. Each core can have its frequency adjusted independently, allowing VMs to take advantage of different workload types and not be hamstrung by occupants on other VMs in the same socket. This becomes important when AVX, AVX2 and AVX-512 are being used at the same time.
Most of the turbo modes are a sliding scale, with the peak turbo used when only one or two cores are active, sliding down to a minimum frequency that may be the ‘base’ frequency or just above it. There’s a lot of information for the parts here, so we’ll break it down into stages.
First up, a look at the Platinum 8180 in the different modes:
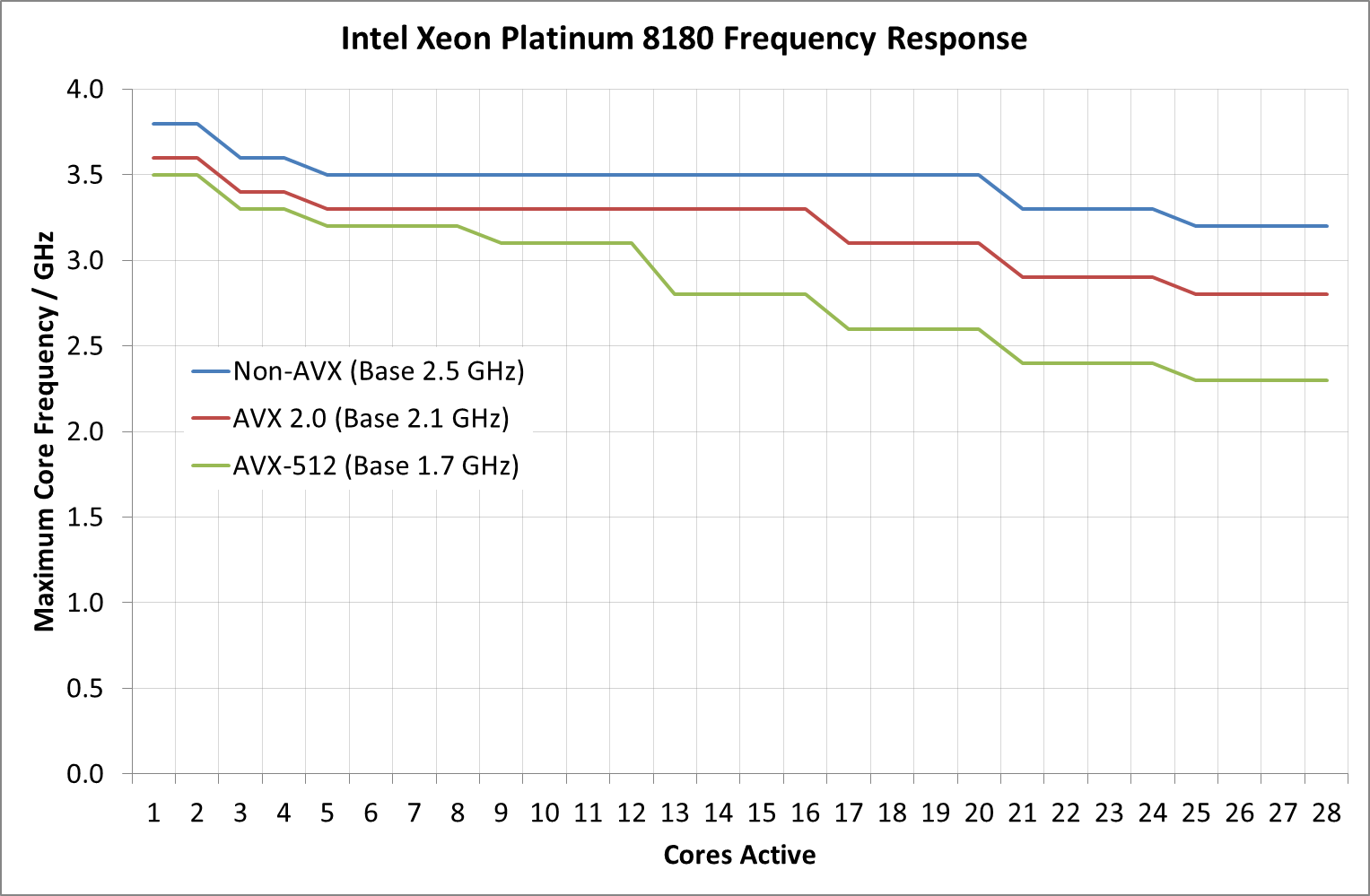
It should be worth noting what the base frequency actually is, and some of the nuance in Intel’s wording here. The base frequency is the guaranteed frequency of the chip – Intel sells the chip with the base frequencies as the guarantee, such that when the chip is not idle and not in normal conditions (i.e. when not in thermal power states to reduce temperature) should operate at this frequency or above it. Intel also lists the per-core turbo frequencies as ‘Maximum Core Frequencies’ indicating that the processors could be running lower than listed, depending on power distribution and requirements in other areas of the chip (such as the uncore, or memory controller). It’s a vague set of terms but ultimately the frequency is determined on the fly and can be affected by many factors, but Intel guarantees a certain amount and provides guides as to what it expects the turbo frequencies to be.
As for the Platinum 8180, it keeps its top turbo modes while up to two cores are active, and then drops down. It does this again for another two cores, and a further two cores. From this point, under non-AVX load the CPU is pretty much the same frequency until >20 cores are loaded, but does not decrease that much in all. For AVX 2.0 and AVX-512, the downward slope of more cores means less frequency continues, with AVX-512 taking a bigger jump down at 13 cores loaded. The final turbo frequency for AVX-512 running on all cores is 2.3 GHz.
Comparing the two 28-core CPUs for which we have turbo information gives this graph. The numbers relate to the number of cores need to be loaded for that frequency.

Both processors are equal to each other for dual core loading, but the separation occurs when more cores are loaded. As we move through to AVX 2.0 and AVX-512, it is clear where the separations are in performance – to get the best for variable core loading, the more expensive processors are required.
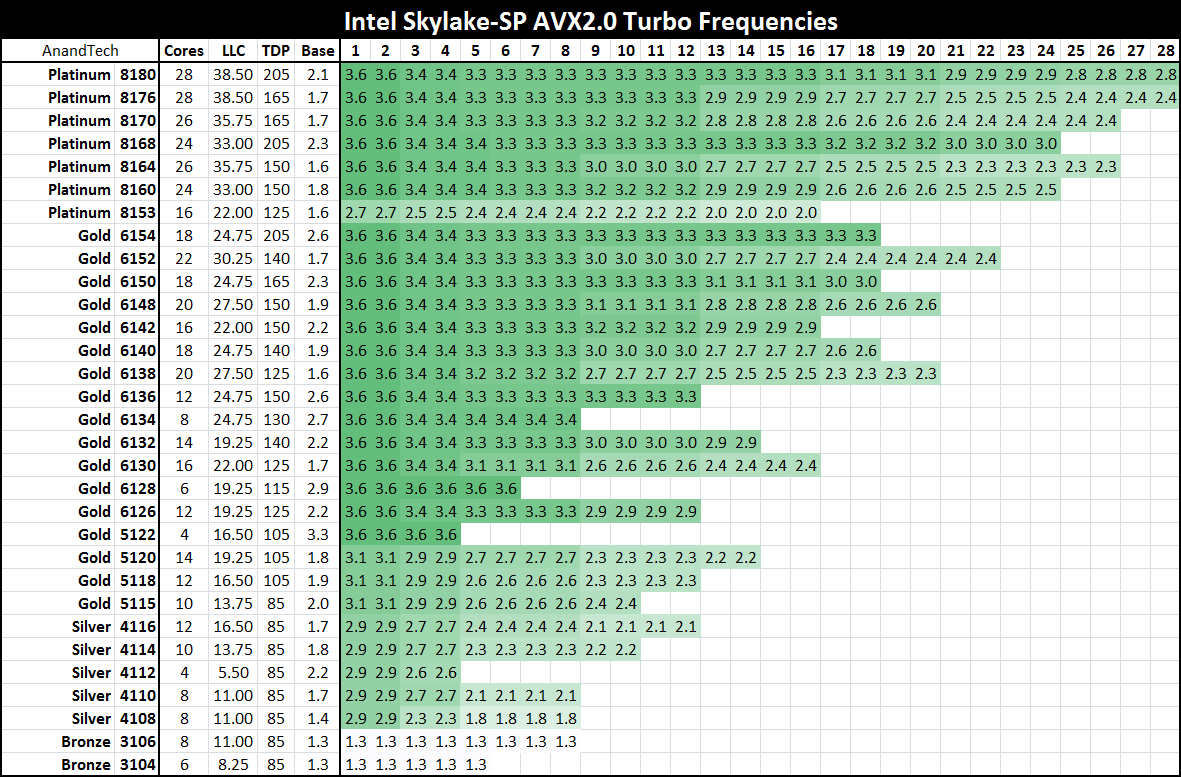
Here’s the big table for all the processors on Non-AVX loading:

Despite the 2.0/2.1 GHz base on most of the Platinum series, all the CPUs will turbo up to 3.7-3.8 GHz on low core loading except for the lower power Platinum 8153. For users wanting to strike a good balance between the core count and frequency, the Gold 6154 is probably the place to be: 18 cores that will only ever run at 3.7 GHz with non-AVX loading (3.5-2.7 GHz on AVX-512 depending on core count), and will be $3543 as a list price at 205W. It is perhaps worth noting that this will likely top any of the Core i9 processors planned: at 18-cores and 205W for 3.7 GHz, the Core i9-7980XE which will have 18 cores but run 165W will likely be clocked lower (but also only ~$2000).
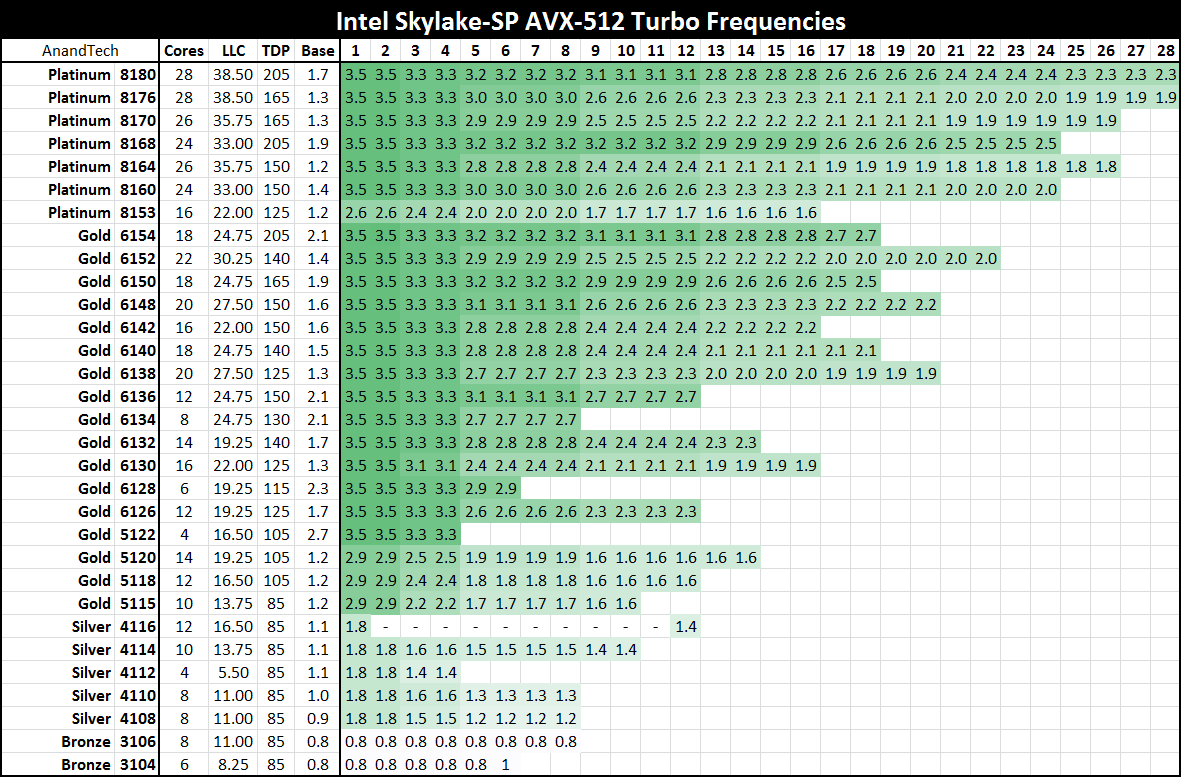
Moving onto AVX2.0 and AVX-512:








219 Comments
View All Comments
oldlaptop - Thursday, July 13, 2017 - link
Why on earth is gcc -Ofast being used to mimic "real-world", non-"aggressively optimized"(!) conditions? This is in fact the *most* aggressive optimization setting available; it is very sensitive to the exact program being compiled at best, and generates bloated (low priority on code size) and/or buggy code at worst (possibly even harming performance if the generated code is so big as to harm cache coherency). Most real-world software will be built with -O2 or possibly -Os. I can't help but wonder why questions weren't asked when SPEC complained about this unwisely aggressive optimization setting...peevee - Thursday, July 13, 2017 - link
"added a second full-blown 512 bit AVX-512 unit. "Do you mean "added second 256 ALU, which in combination with the first one implements full 512-bit AVX-512 unit"?
peevee - Thursday, July 13, 2017 - link
"getting data from the right top node to the bottom left node – should demand around 13 cycles. And before you get too concerned with that number, keep in mind that it compares very favorably with any off die communication that has to happen between different dies in (AMD's) Multi Chip Module (MCM), with the Skylake-SP's latency being around one-tenth of EPYC's."1/10th? Asking data from L3 on the chip next to it will take 130 (or even 65 if they are talking about averages) cycles? Does not sound realistic, you can request data from RAM at similar latencies already.
AmericasCup - Friday, July 14, 2017 - link
'For enterprises with a small infrastructure crew and server hardware on premise, spending time on hardware tuning is not an option most of the time.'Conversely, our small crew shop has been tuning AMD (selected for scalar floating point operations performance) for years. The experience and familiarity makes switching less attractive.
Also, you did all this in one week for AMD and two weeks for Intel? Did you ever sleep? KUDOS!
JohanAnandtech - Friday, July 21, 2017 - link
Thanks for appreciating the effort. Luckily, I got some help from Ian on Tuesday. :-)AntonErtl - Friday, July 14, 2017 - link
According to http://www.anandtech.com/show/10158/the-intel-xeon... if you execute just one AVX256 instruction on one core, this slows down the clocks of all E5v4 cores on the same socket for at least 1ms. Somewhere I read that newer Xeons only slow down the core that executes the AVX256 instruction. I expect that it works the same way for AVX512, and yes, this means that if you don't have a load with a heavy proportion of SIMD instructions, you are better off with AVX128 or SSE. The AMD variant of having only 128-bit FPUs and no clock slowdown looks better balanced to me. It might not win Linpack benchmark competitions, but for that one uses GPUs anyway these days.wagoo - Sunday, July 16, 2017 - link
Typo on the CLOSING THOUGHTS page: "dual Silver Xeon solutions" (dual socket)Great read though, thanks! Can finally replace my dual socket shanghai opteron home server soon :)
Chaser - Sunday, July 16, 2017 - link
AMD's CPU future is looking very promising!bongey - Tuesday, July 18, 2017 - link
EPYC power consumption is just wrong. Somehow you are 50W over what everyone else is getting at idle. https://www.servethehome.com/amd-epyc-7601-dual-so...Nenad - Thursday, July 20, 2017 - link
Interesting SPECint2006 results:- Intel in their slide #9 claims that Intel 8160 is 2% faster than EPYC 7601
- Anandtech in article tests that EPYC 7601 is 42% faster than Intel 8176
Those two are quite different, even if we ignore that 8176 should be faster than 8160. In other words, those Intel test results look very suspicious.