Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Floating Point
Normally our HPC benchmarking is centered around OpenFoam, a CFD software we have used for a number of articles over the years. However, since we moved to Ubuntu 16.04, we could not get it to work anymore. So we decided to change our floating point intensive benchmark for now. For our latest article, we're testing with C-ray, POV-Ray, and NAMD.
The idea is to measure:
- A FP benchmark that is running out of the L1 (C-ray)
- A FP benchmark that is running out of the L2 (POV-Ray)
- And one that is using the memory subsytem quite often (NAMD)
Floating Point: C-ray
C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out of the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing.
We use the standard benchmarking resolution (3840x2160) and the "sphfract" file to measure performance. The binary was precompiled.
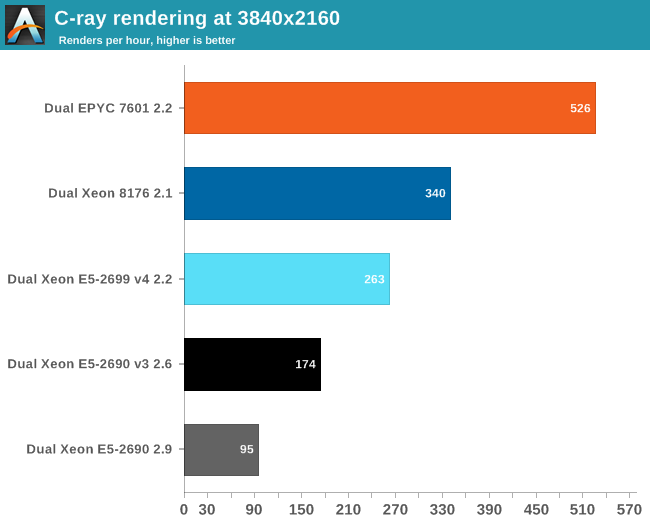
Wow. What just happened? It looks like a landslide victory for the raw power of the four FP pipes of Zen: the EPYC chip is no less than 50% faster than the competition. Of course, it is easy to feed FP units if everything resides in the L1. Next stop, POV-Ray.
Floating Point: POV-Ray 3.7
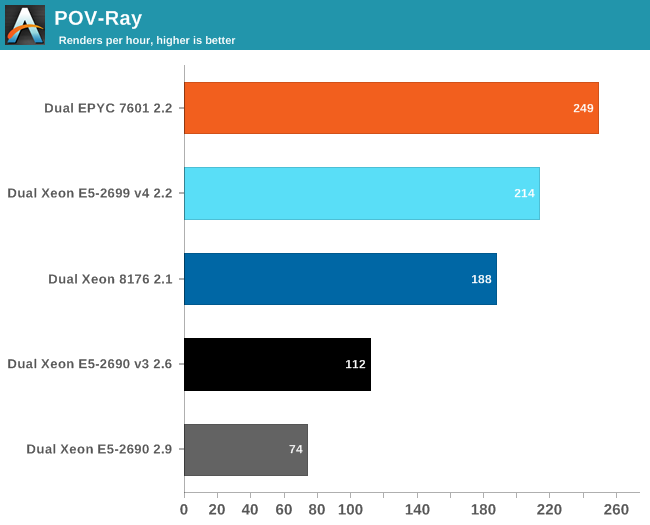
POV-Ray is known to run mostly out of the L2-cache, so the massive DRAM bandwidth of the EPYC CPU does not play a role here. Nevertheless, the EPYC CPU performance is pretty stunning: about 16% faster than Intel's Xeon 8176. But what if AVX and DRAM access come in to play? Let us check out NAMD.
Floating Point: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX.
First, we used the "NAMD_2.10_Linux-x86_64-multicore" binary. We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
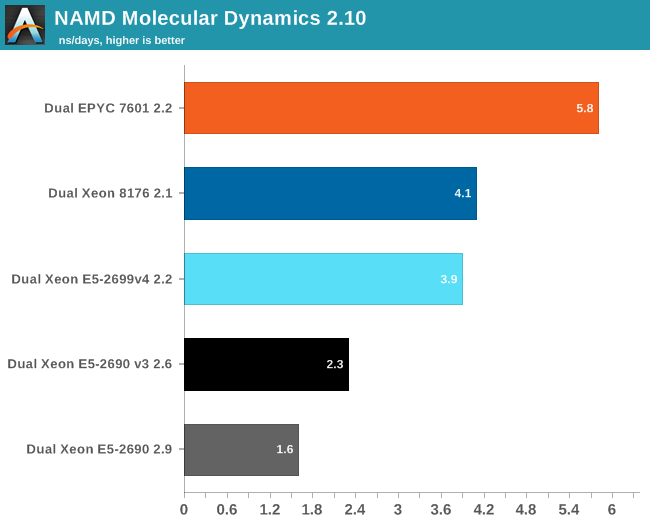
Again, the EPYC 7601 simply crushes the competition with 41% better performance than Intel's 28-core. Heavily vectorized code (like Linpack) might run much faster on Intel, but other FP code seems to run faster on AMD's newest FPU.
For our first shot with this benchmark, we used version 2.10 to be able to compare to our older data set. Version 2.12 seems to make better use of "Intel's compiler vectorization and auto-dispatch has improved performance for Intel processors supporting AVX instructions". So let's try again:
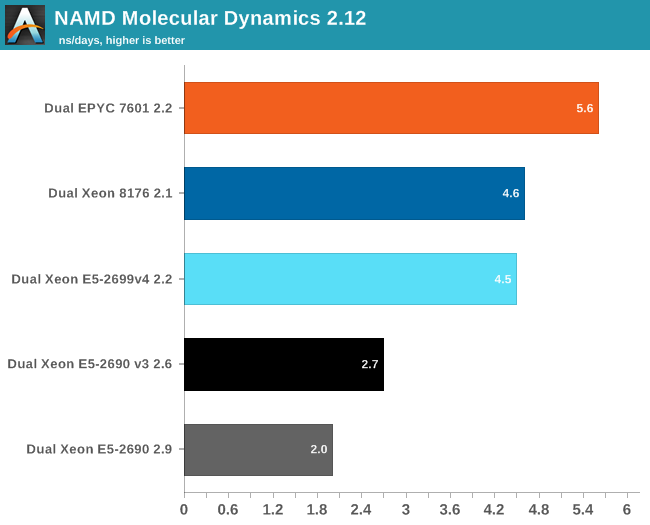
The older Xeons see a perforance boost of about 25%. The improvement on the new Xeons is a lot lower: about 13-15%. Remarkable is that the new binary is slower on the EPYC 7601: about 4%. That simply begs for more investigation: but the deadline was too close. Nevertheless, three different FP tests all point in the same direction: the Zen FP unit might not have the highest "peak FLOPs" in theory, there is lots of FP code out there that runs best on EPYC.








219 Comments
View All Comments
alpha754293 - Tuesday, July 11, 2017 - link
Pity that OpenFOAM failed to run on Ubuntu 16.04.2 LTS. I would have been very interested in those results.farmergann - Tuesday, July 11, 2017 - link
Are you trying to hide the fact that AMD's performance per watt absolutely dominates intel's, or have you simply overlooked one of, if not the, single most important aspects of server processors?Ryan Smith - Tuesday, July 11, 2017 - link
Neither. We just had very little time to look at power consumption. It's also the metric we're the least confident in right now, as we'd like to have a better understanding of the quirks of the platform (which again takes more time).Carl Bicknell - Wednesday, July 12, 2017 - link
Ryan / Ian,Just to let you know there are better chess benchmarks than the one you've chosen. Stockfish is an example of a newer program which better uses modern CPU architecture.
NixZero - Tuesday, July 11, 2017 - link
"AMD's MCM approach is much cheaper to manufacture. Peak memory bandwidth and capacity is quite a bit higher with 4 dies and 2 memory channels per die. However, there is no central last level cache that can perform low latency data coordination between the L2-caches of the different cores (except inside one CCX). The eight 8 MB L3-caches acts like - relatively low latency - spill over caches for the 32 L2-caches on one chip. "isnt skylake-x's l3 a victim cache too? and divided at 1.3mb for each core, not a monolytic one?
Ian Cutress - Tuesday, July 11, 2017 - link
That's what a 'spill-over' cache is - it accepts evicted cache lines.NixZero - Wednesday, July 12, 2017 - link
so why its put as an advantage for intel cache, which is spill over too?JonathanWoodruff - Wednesday, July 12, 2017 - link
Since the Intel one is all on one die, a miss to a "slice" of cache can be filled without DRAM-like latencies from another slice. Since AMD has it's last level caches spread across dies, going to another cache looks to be equivalent latency-wise to going to DRAM. It wouldn't necessarily have to be quite that bad, and I would expect some improvement here for Zen2.Martin_Schou - Tuesday, July 11, 2017 - link
This has to be wrong:CPU Two EPYC 7601 (2.2 GHz, 32c, 8x8MB L3, 180W)
RAM 512 GB (12x32 GB) Samsung DDR4-2666 @2400
12 x 32 GB is 384 GB, and 12 sticks doesn't fit nicely into 8 channels. In all likelihood that's supposed to be 16x32 GB, as we see in the E52690
Dr.Neale - Tuesday, July 11, 2017 - link
I find myself puzzled by the curious omission in this article of a key aspect of Server architecture: Data Security.AMD has a LOT; Intel, not so much.
I would think this aspect of Server "Performance" would be a major consideration in choosing which company's Architecture to deploy in a Secure Server scenario. Especially in light of Recent Revelations fuelling Hacking Headlines in the news, and Dominating Discussions on various social media websites.
How much is Data Security worth?
A topic of EPYC consequence!