Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Floating Point
Normally our HPC benchmarking is centered around OpenFoam, a CFD software we have used for a number of articles over the years. However, since we moved to Ubuntu 16.04, we could not get it to work anymore. So we decided to change our floating point intensive benchmark for now. For our latest article, we're testing with C-ray, POV-Ray, and NAMD.
The idea is to measure:
- A FP benchmark that is running out of the L1 (C-ray)
- A FP benchmark that is running out of the L2 (POV-Ray)
- And one that is using the memory subsytem quite often (NAMD)
Floating Point: C-ray
C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out of the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing.
We use the standard benchmarking resolution (3840x2160) and the "sphfract" file to measure performance. The binary was precompiled.
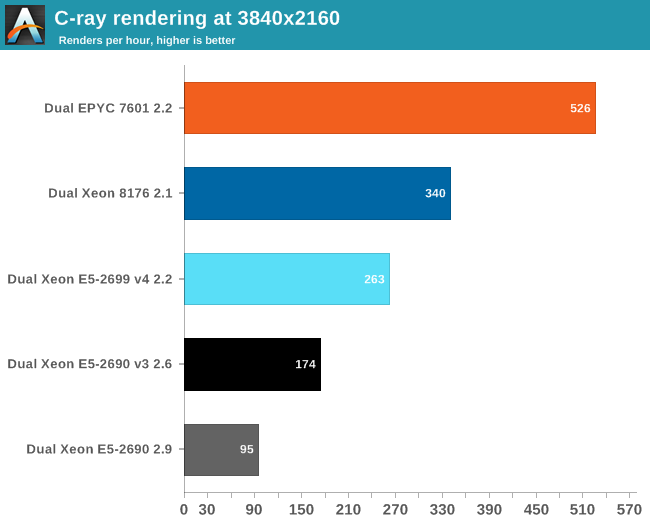
Wow. What just happened? It looks like a landslide victory for the raw power of the four FP pipes of Zen: the EPYC chip is no less than 50% faster than the competition. Of course, it is easy to feed FP units if everything resides in the L1. Next stop, POV-Ray.
Floating Point: POV-Ray 3.7
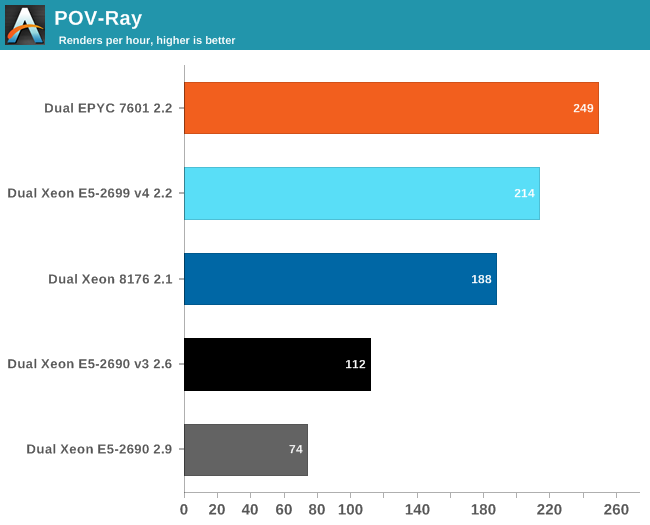
POV-Ray is known to run mostly out of the L2-cache, so the massive DRAM bandwidth of the EPYC CPU does not play a role here. Nevertheless, the EPYC CPU performance is pretty stunning: about 16% faster than Intel's Xeon 8176. But what if AVX and DRAM access come in to play? Let us check out NAMD.
Floating Point: NAMD
Developed by the Theoretical and Computational Biophysics Group at the University of Illinois Urbana-Champaign, NAMD is a set of parallel molecular dynamics codes for extreme parallelization on thousands of cores. NAMD is also part of SPEC CPU2006 FP. In contrast with previous FP benchmarks, the NAMD binary is compiled with Intel ICC and optimized for AVX.
First, we used the "NAMD_2.10_Linux-x86_64-multicore" binary. We used the most popular benchmark load, apoa1 (Apolipoprotein A1). The results are expressed in simulated nanoseconds per wall-clock day. We measure at 500 steps.
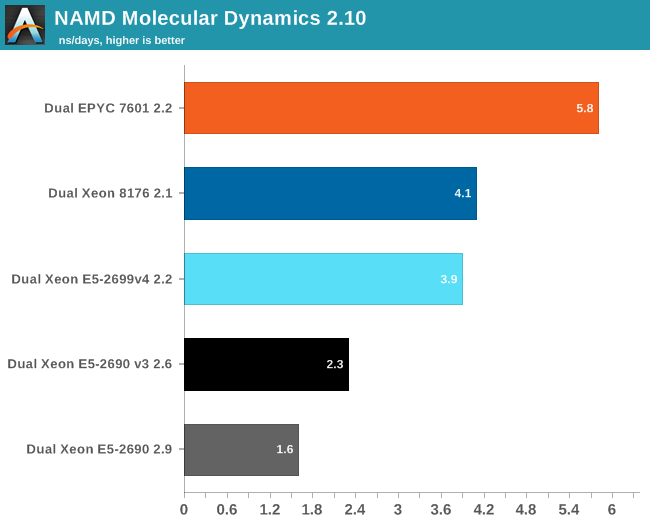
Again, the EPYC 7601 simply crushes the competition with 41% better performance than Intel's 28-core. Heavily vectorized code (like Linpack) might run much faster on Intel, but other FP code seems to run faster on AMD's newest FPU.
For our first shot with this benchmark, we used version 2.10 to be able to compare to our older data set. Version 2.12 seems to make better use of "Intel's compiler vectorization and auto-dispatch has improved performance for Intel processors supporting AVX instructions". So let's try again:
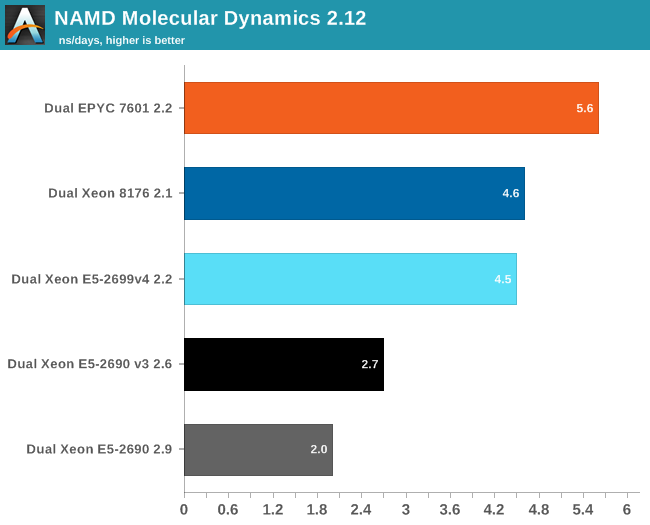
The older Xeons see a perforance boost of about 25%. The improvement on the new Xeons is a lot lower: about 13-15%. Remarkable is that the new binary is slower on the EPYC 7601: about 4%. That simply begs for more investigation: but the deadline was too close. Nevertheless, three different FP tests all point in the same direction: the Zen FP unit might not have the highest "peak FLOPs" in theory, there is lots of FP code out there that runs best on EPYC.








219 Comments
View All Comments
sharath.naik - Wednesday, July 12, 2017 - link
http://www.anandtech.com/show/10158/the-intel-xeon...Here is the link for you a single Xeon E5 v4 22 core does 5.3 (Dual at 5.9)jobs a day compared to dual Epyc 6.3. Ok they are 7% apart for dual socket but only 15% faster for dual epyc compared to single Xeon E5. Big Data does not do well in NUMA set up, same is the case with any regular large data applications. Try running EPYC without splitting spark into multiple processes, you will see how terrible a dual EPYC is going to be (the review mentions it but does not give a graph). Now this is terrible, to use EPYC first you need to change the way you build and run the applications and then expect 7-15% advantage vs a 2000$ CPU. It simple shows that EPYC is only use full for VMs and some synthetic tests. Any applications that deal with data can and should stay away from EPYC
warreo - Friday, July 14, 2017 - link
Why are you comparing Spark 1.5 benchmarks against 2.1.1? Johan pointed out in the article why they are not comparable and why he is using the new 2.1.1 benchmark.The exact Dual Xeon E5 2699 v4 you are referencing that did 5.9 jobs per day in Spark 1.5 only does 4.9 jobs per day on Spark 2.1.1. If we assume a similar % gap between dual and single as it was in Spark 1.5, then a single Xeon E5 2699 v4 would be capable of only 4.4 jobs per day in Spark 2.1.1, which is a 43% difference compared to dual Epycs.
Even leaving that aside, your exact arguments can be applied to the new Xeons as well, which are only 5% faster than the Epycs. Do you think the new Xeons suck as well?
Same thing for splitting Spark into multiple processes and needing to re-write applications -- you also run into the exact same issue with the new Xeons (which Johan also explictly points out).
Based on your arguments, I'm confused why you are taking aim only at Epyc and not the new Xeons. Please let me know if I'm missing something here.
AleXopf - Wednesday, July 12, 2017 - link
Username checks outdeltaFx2 - Wednesday, July 12, 2017 - link
"four 8core desktop dies" Oh, on the contrary. It's really a 4 die MCM server part, and each die is being sold as a desktop part. Nobody puts interconnect (fabric) on a desktop part. MCM is something intel has also done way back in the dual core era, and IBM continues to do. Don't float that canard re. desktop parts, it's just a design choice. AMD isn't trying to beat Intel in every market, just in some, and it does that. It might not win in HPC or big enterprise database (idk), but if you are a public cloud provider in the business of renting 4c8t or 8c16t VMs, AMD has a solid product. Now throw in the 128 PCIe lanes, which intel can't come close to. In fact, a 32c Naples in 1P is something that Intel has nothing to compete against for applications like storage, GPGPU, etc. The question isn't if it's good enough to run Intel out of business in the server space; that's not happening. It didn't when AMD had a superior product in Opteron. The question is, is it good enough for 5-10% market share in 2018-2019?"Intel cores are superior than AMD so a 28 core xeon is equal to ~40 cores if you compare again Ryzen core so this whole 28core vs 32core is a marketing trick". And yet all the numbers presented above point to the opposite. Ryzen != Epyc and i7700K != Syklake EP/SP, if that's where you're getting your numbers from. If not, present data.
Amiga500 - Wednesday, July 12, 2017 - link
No surprise that the Intel employee is descending to lies and deceit to try and plaster over the chasms! They've also reverted to bribing suppliers to offer Ryzen with only crippled memory speeds too (e.g. pcspecialist.co.uk - try and get a Ryzen system with >2133 MHz memory, yet the SKL-X has up top 3600 MHz memory --- the kicker is - they used to offer Ryzen at up to 3000 MHz memory!). It would seem old habits die hard.Hopefully the readers are wise enough to look at the performance data and make their decisions from that.
If OEMs are willing to bend to Intels dirty dollars, I trust customers will eventually choose to take their business elsewhere. We certainly won't be using pcspecialist again in the near future.
Shankar1962 - Wednesday, July 12, 2017 - link
Look at the picture in this article and see what the big players reported when they upgraded to SkylakeDon't hate a company for the sake of argument. The world we live today from a hardware technology standpoint is because of Intel and respect it
https://www.google.com/amp/s/seekingalpha.com/amp/...
Shankar1962 - Wednesday, July 12, 2017 - link
I agree. Intel has been a data center leader and pioneered for decades now. It has proven track record and overall platform stability consistency and strong portfolio and roadmap. With intel transforming to a data company i see that the best is yet to come as it did smart acquisitions and I believe products with IP from those aquired companies are still nnot fully integrated. Everyone loves an underdog and its clear that everyones excited as someone is getting 5% share and Intel won't be sitting....they did it in the past they will do it again:)0ldman79 - Wednesday, July 12, 2017 - link
I find the power consumption info quite interesting, especially considering the TDP ratings for the processors.The platform makes a difference, though I wonder what the actual difference is. Intel and AMD have been rating their TDP differently for years now.
Atom11 - Wednesday, July 12, 2017 - link
After all these tests we still know nothing about AVX512. According to the specs, the floating point should be about 2x faster on CPU with AVX512 in compare to CPU without AVX512. There should be a clear line between Gcc and Icc. Gcc compiler does not support AVX512 anyway and it otherwise also has a relatively limited vectorization support. Not using Icc means, not using the only compiler which actually supports the Intel hardware features. But it yes, it is a difficult comparison, because you need both Instructions and Software which uses those instructions optimized the best way possible and some users simply don't bother about using optimized software. It would be nice to see comparison between: GCC+ AMD and ICC+Intel. So that only compiler is changed, but also the code is written so that it is possible for it to be efficiently vectorized and threaded. What can I get on Intel, if I use best possible software stack and what can I get on AMD? The current article only answers the question: What can i get on AMD and Intel if I dont bother with software stack and optimization.yuhong - Wednesday, July 12, 2017 - link
Inphi has a press release about shipping 1 million DDR3 LR-DIMM buffers six months before the launch of Haswell-E: https://www.inphi.com/media-center/press-room/pres... I wonder how many they shipped total so far (and also Montage).