Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Introducing Skylake-SP: The Xeon Scalable Processor Family
The biggest news hitting the streets today comes from the Intel camp, where the company is launching their Skylake-SP based Xeon Scalable Processor family. As you have read in Ian's Skylake-X review, the new Skylake-SP core has been rather significantly altered and improved compared to it's little brother, the original Skylake-S. Three improvements are the most striking: Intel added 768 KB of per-core L2-cache, changed the way the L3-cache works while significantly shrinking its size, and added a second full-blown 512 bit AVX-512 unit.

On the defensive and not afraid to speak their mind about the competition, Intel likes to emphasize that AMD's Zen core has only two 128-bit FMACs, while Intel's Skylake-SP has two 256-bit FMACs and one 512-bit FMAC. The latter is only useable with AVX-512. On paper at least, it would look like AMD is at a massive disadvantage, as each 256-bit AVX 2.0 instruction can process twice as much data compared to AMD's 128-bit units. Once you use AVX-512 bit, Intel can potentially offer 32 Double Precision floating operations, or 4 times AMD's peak.
The reality, on the other hand, is that the complexity and novelty of the new AVX-512 ISA means that it will take a long time before most software will adopt it. The best results will be achieved on expensive HPC software. In that case, the vendor (like Ansys) will ask Intel engineers to do the heavy lifting: the software will get good AVX-512 support by the expensive process of manual optimization. Meanwhile, any software that heavily relies on Intel's well-optimized math kernel libraries should also see significant gains, as can be seen in the Linpack benchmark.
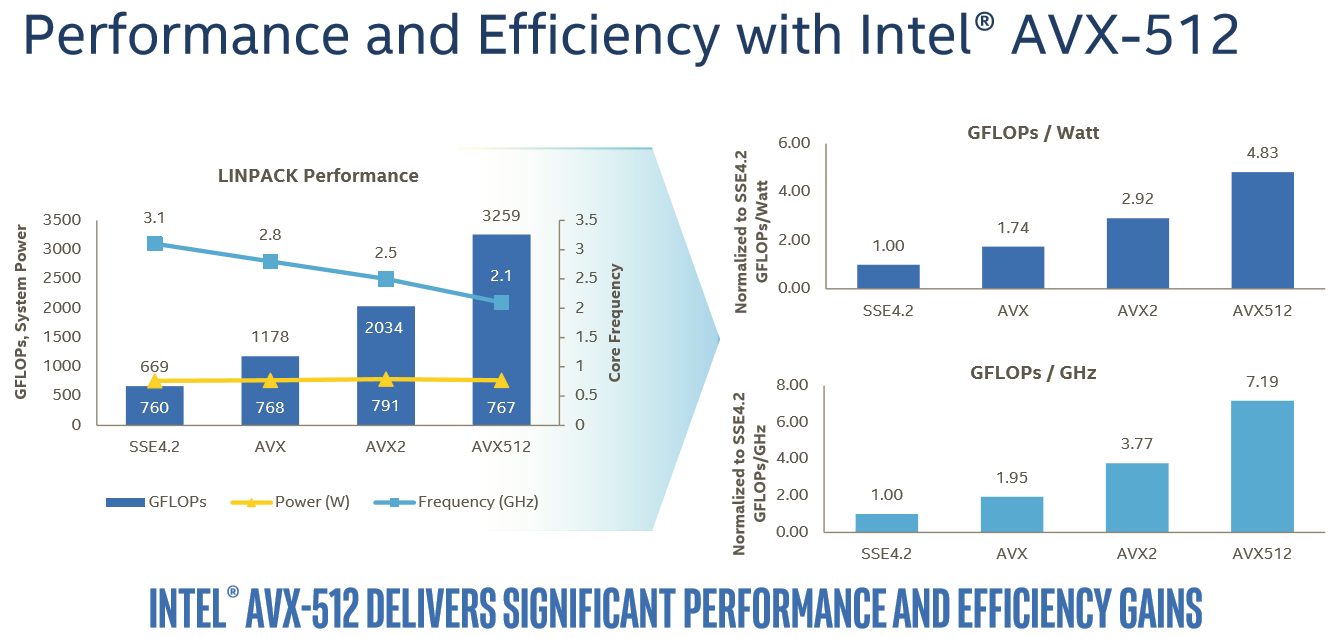
In this case, Intel is reporting 60% better performance with AVX-512 versus 256-bit AVX2.
For the rest of us mere mortals, it will take a while before compilers will be capable of producing AVX-512 code that is actually faster than the current AVX binaries. And when they do, the result will be probably be limited, as compilers still have trouble vectorizing code from scratch. Meanwhile it is important to note that even in the best-case scenario, some of the performance advantage will be negated by the significantly lower clock speeds (base and turbo) that Intel's AVX-512 units run at due to the sheer power demands of pushing so many FLOPS.

For example, the Xeon 8176 in this test can boost to 2.8 GHz when all cores are active. With AVX 2.0 this is reduced to 2.4 GHz (-14%), with AVX-512, the clock tumbles down to 1.9 GHz (another 20% lower). Assuming you can fill the full width of the AVX unit, each step still sees a significant performance improvement, but AVX2 to AVX-512 won't offer a full 2x performance improvement even with ideal code.
Lastly, about half of the major floating point intensive applications can be accelerated by GPUs. And many FP applications are (somewhat) limited by memory bandwidth. While those will still benefit from better AVX code, they will show diminishing returns as you move from 256-bit AVX to 512-bit AVX. So most FP applications will not achieve the kinds of gains we saw in the well-optimized Linpack binaries.








219 Comments
View All Comments
JohanAnandtech - Friday, July 21, 2017 - link
Thanks! It is was a challenge, and we will update this article later on, when better kernel support is available.serendip - Tuesday, July 11, 2017 - link
What idiot marketroid thought it was cool to have a huge list of SKUs and gimped "precious metals" branding? I'd like to see Epyc kicking Xeon butt simply because AMD has much more sensible product lists and there's not much gimping going on.ParanoidFactoid - Tuesday, July 11, 2017 - link
Reading through this, the takeaway seems thus. Epyc has latency concerns in communicating between CCX blocks, though this is true of all NUMA systems. If your application is latency sensitive, you either want a kernel that can dynamically migrate threads to keep them close to their memory channel - with an exposed API so applications can request migration. (Linux could easily do this, good luck convincing MS). OR, you take the hit. OR, you buy a monolithic die Intel solution for much more capital outlay. Further, the takeaway on Intel is, they have the better technology. But their market segmentation strategy is so confusing, and so limiting, it's near impossible to determine best cost/performance for your application. So you wind up spending more than expected anyway. AMD is much more open and clear about what they can and can't do. Intel expects to make their money by obfuscating as part of their marketing strategy. Finally, Intel can go 8 socket, so if you need that - say, high core low latency securities trading - they're the only game in town. Sun, Silicon Graphics, and IBM have all ceded that market.msroadkill612 - Wednesday, July 12, 2017 - link
"it's near impossible to determine best cost/performance for your application. So you wind up spending more than expected anyway. AMD is much more open and clear about what they can and can't do. Intel expects to make their money by obfuscating as part of their marketing strategy.Finally, Intel can go 8 socket, so if you need that - say, high core low latency securities trading - they're the only game in town. Sun, Silicon Graphics, and IBM have all ceded that market."
& given time is money, & intelwastes customers time, then intel is expensive.
Those guys will go intel anyway, but just sayin, there is already talk of a 48 core zen cpu, making 98 cores on a mere 2p mobo.
As i have posted b4, if wall street starts liking gpu compute for prompter answers, amdS monster apuS will be unanswerable.
nils_ - Wednesday, July 19, 2017 - link
98 cores on a 2p mobo isn't quite right if you keep in mind that the 32 core versions already constitute a 4 CPU system, unless AMD somehow manages to get more cores on a single die.nils_ - Wednesday, July 19, 2017 - link
Good analysis, although Sun and IBM are still coming out with new CPUs and at least with IBM there is renewed interest in the POWER ecosystem.eek2121 - Wednesday, July 12, 2017 - link
, but rather AMD's spanking new EPYC server CPU. Both CPUs are without a doubt very different: micro architecture, ISA extentions, <snip>Should be extensions.
intelemployee2012 - Wednesday, July 12, 2017 - link
After looking at the number of people who really do not fully understand the entire architecture and workloads and thinking that AMD Naples is superior because it has more cores, pci lanes etc is surprising.AMD made a 32 core server by gluing four 8core desktop dies whereas Intel has a single die balanced datacenter specific architecture which offers more perf if you make the entire Rack comparison. It's not the no of cores its the entire Rack which matters.
Intel cores are superior than AMD so a 28 core xeon is equal to ~40 cores if you compare again Ryzen core so this whole 28core vs 32core is a marketing trick. Everyone thinks Intel is expensive but if you go by performance per dollar Intel has a cheaper option at every price point to match Naples without compromising perf/dollar.
To be honest with so many Fabs, don't you think Intel is capable of gluing desktop dies to create a 32core,64core or evn 128core server (if it wants to) if thats the implementation style it needs to adopt like AMD?
The problem these days is layman looks at just numbers but that's not how you compare.
sharath.naik - Wednesday, July 12, 2017 - link
Agree, Most who look at these numbers will walk away thinking AMD is doing well with EPYC. The article points out the approach to testing and also states the performance challenges with EPYC, which can be missed who reading this review without the prior review on the older Xeons. For example the Big data test, I bet the newbies will walk away thinking EPYC beats the older XEONS E5 v4, as thats what the graphs show,without ever looking back at the numbers for a single 22 core Xeon e5 v4. So yes, a few back links in the article will be helpful.warreo - Wednesday, July 12, 2017 - link
Not a fanboi of either company, but care to elaborate more? I checked the original Xeon E5 v4 review. It shows that a single Xeon E5 v4 performs about 10% slower than a dual setup. Extrapolating that here, that means the single Xeon E5 v4 setup would be right around 4.5 jobs per day, which would make it roughly 50% slower than the dual Epyc and Xeon 8176.Sure, you could argue perf/dollar is better against a dual Epyc setup...but one could make the same argument against Intel's Skylake Xeons? I also wouldn't expect the performance to scale linearly anyway. Please let me know what I'm missing.