Launching the #CPUOverload Project: Testing Every x86 Desktop Processor since 2010
by Dr. Ian Cutress on July 20, 2020 1:30 PM ESTCPU Tests: Microbenchmarks
There is a class of synthetic tests which are valid - these tests are designed to probe the system underneath to find out how it works, rather than focusing on performance. As part of our test suite, these benchmarks are run for the sake of us having insights into the data, however this data isn’t in a form that we can transcribe into Bench, but it will certainly be part of reviews into how each different microarchitecture is evolving. Sometimes these tests are called ‘Microbenchmarks’, however some of our tests are more than that.
Full x86 Instruction Throughput/Latency Analysis
The full version of one of the software packages we use has a tool in order to be able to test every single x86 and x64 instruction that is in the official documentation, along with variants of those instructions. Our full instruction test goes through all of them, including x87 and the latest AVX-512, to see what works and how performant they are.
For this benchmark, we acquired a command line version. There is a secondary caveat, and that it requires turbo to be disabled – luckily we can do that on the command line as well.
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
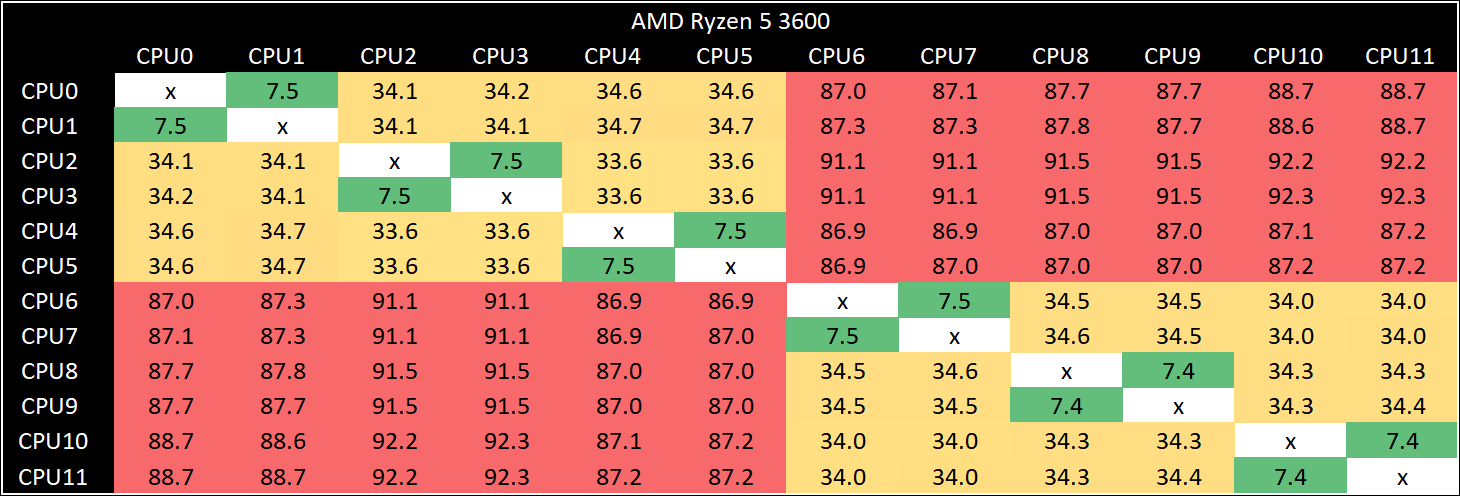
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
There is one caveat, and that’s the danger of putting too much emphasis on the comparative values. These are latency values, and in terms of performance, only particularly relevant if a workload is core-to-core latency sensitive. There are always plenty of other elements in play, such as prefetchers and buffers, which likely matter more to performance.
Cache-to-DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
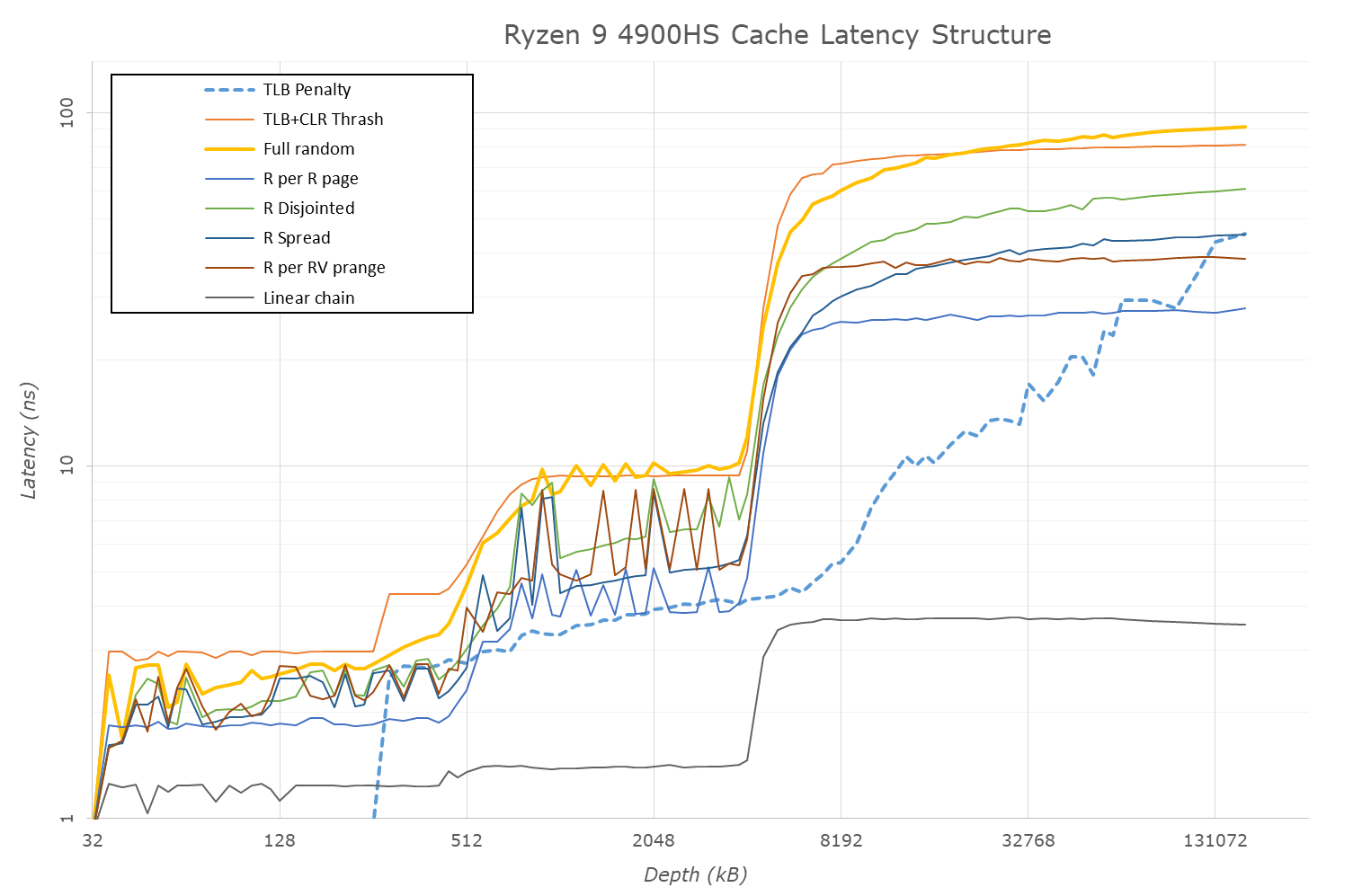
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test should prove to be very valuable.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, while AMD has CPPC2.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue, again due to another fabulous Andrei tool, by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies.
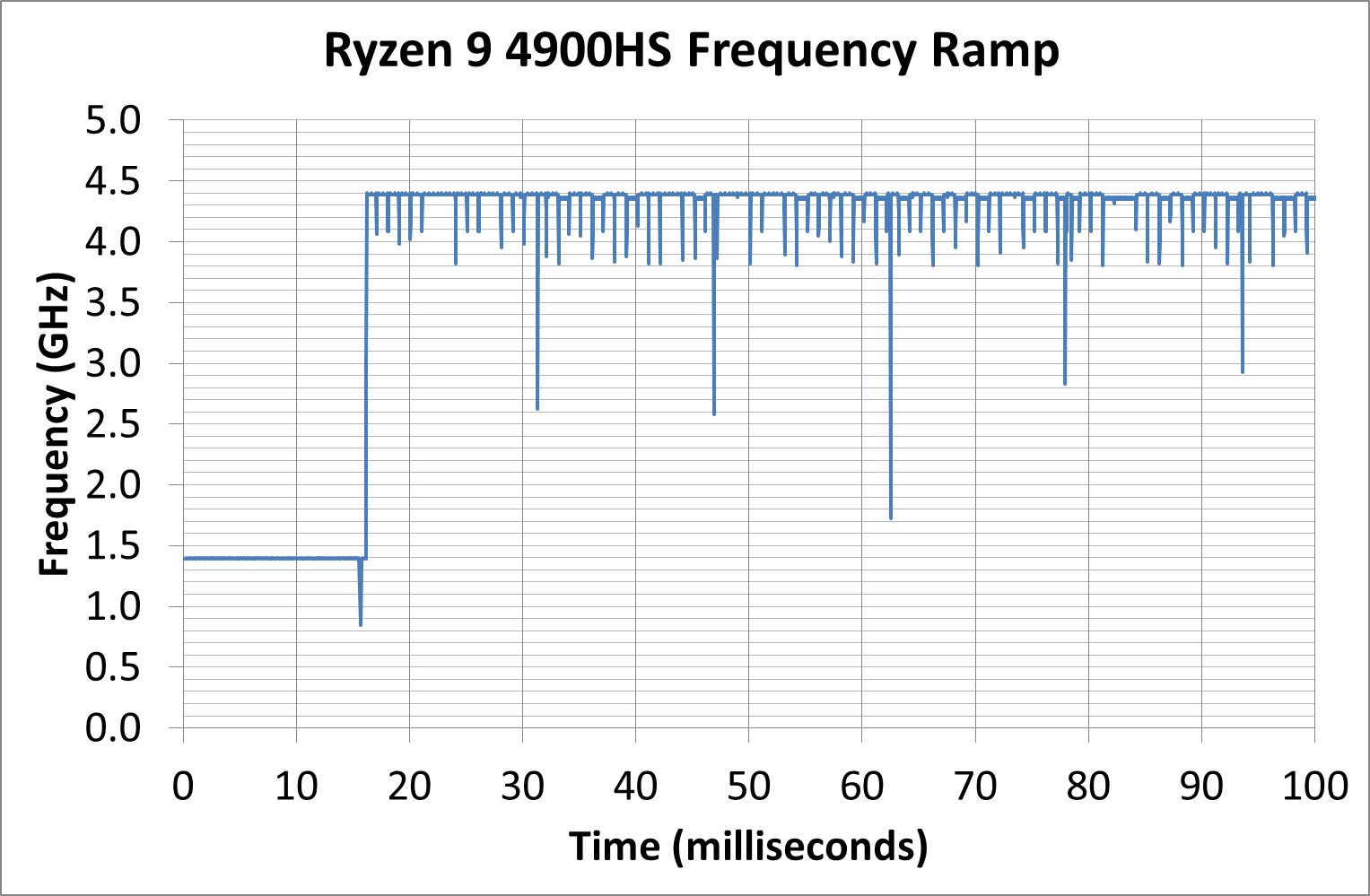
Our Frequency Ramp tool has already been in use in a number of reviews. Currently we’re seeing most Intel and AMD CPUs aim for a 16.6 ms idle-to-turbo scale, which equates to a single frame on a 60 Hz display – this is often enough for most user interaction situations.
A y-Cruncher Sprint
This last test is somewhat for my own edification. The y-cruncher website has a large about of benchmark data showing how different CPUs perform to calculate specific values of pi. Below these there are a few CPUs where it shows the time to compute moving from 25 million digits to 50 million, 100 million, 250 million, and all the way up to 10 billion, to showcase how the performance scales with digits (assuming everything is in memory).
This range of results, from 25 million to 250 billion, is something I’ve dubbed a ‘sprint’.
You might notice that not all of the cells are filled, and that is because as we move into the billions, the systems have to have 16/32/64 of memory or more in order to even attempt the task. Moreover, there is no element of consistency in the data – it’s all from a variety of places using different memory.
In order to get a complete set of data, I have written some code in order to perform a sprint on every CPU we test. It detects the DRAM, works out the biggest value that can be calculated with that amount of memory, and works up from 25 million digits. For the tests that go up to the ~25 billion digits, it only adds an extra 15 minutes to the suite for an 8-core Ryzen CPU.








110 Comments
View All Comments
PeachNCream - Tuesday, July 21, 2020 - link
You don't get what it means to perform a controlled test do you?Aspernari - Wednesday, July 22, 2020 - link
It's important to note that the environment is not actually well-controlled.https://twitter.com/IanCutress/status/128480609693...
We don't know temperature for the operating conditions for these tests, which matters more and more for boost behavior for CPUs and GPUs. He says 36c when he got into the office, we'll never know what the temperature peaked at, nor how often similar conditions were reached.
A standard platform is a good choice, but a controlled environment is also important. Unfortunately, the results aren't as reliable as they otherwise might have been.
PeterCollier - Wednesday, July 22, 2020 - link
And that's why this entire test is a complete waste of time. Something like Geekbench or especially Userbench is much, much better because it gives you a range of scores. Instead of trying to create false precision by saying that a AMD 4700U scored, say, a "979" on a benchmark, Userbench will say that all the 4700U's tested scored from 899 to 1008, and break it down into percentiles. This way, you have a range of expected performance in mind instead of being fixated on that "979" number, which could have been obtained in an unrealistic scenario.Rudde - Saturday, July 25, 2020 - link
Isn't userbench a synthetic together with geekbench? What exactly are they testing? Instead of knowing which of Intel i7 10700k and AMD ryzen 7 3800X is better at rendering, video encoding, number crunching or whatever your use case is, you'll get a distribution based on a largely unknown test. The Intel and AMD processors might end up being within error margins of each other in your use case, but that in itself tells something too. All benchmarks are inherently bad; there is not a single benchmark that captures every use case while not being affected by its environment (ram speeds, temperatures, etc). I prefer tests that I understand, over tests that I do not understand.bananaforscale - Wednesday, July 22, 2020 - link
One could ask what the point of Userbenchmark is in these days of quadcores being basically entry level while the benchmark has DECREASED its multicore weighting.A5 - Monday, July 20, 2020 - link
For my own personal test, getting an i7-4770K in the list would be a big help.Once you have a compile test, a Xeon E5-1680v3 would be nice to see so that I can sell my corp on newer workstations...
Shmee - Wednesday, July 22, 2020 - link
Those are great Haswell EP CPUs, and they OC too! I have an E5-1660v3 in my X99 rig.Mockingtruth - Monday, July 20, 2020 - link
I have a 3570k and a E8600 spare with respective motherboards and ram if useful?CampGareth - Monday, July 20, 2020 - link
Personally I'd like to see a Xeon E5-2670 v1 benchmarked. I'm still running a pair of them as my workstation but these days AMD can beat the performance on a single socket and halve the power consumption.Samus - Tuesday, July 21, 2020 - link
Do you run them in an HP Z620? I ran the same system with the same CPU’s for years at one of my clients. What a beast.