NVIDIA Volta Unveiled: GV100 GPU and Tesla V100 Accelerator Announced
by Ryan Smith on May 10, 2017 5:00 PM EST
Today at their annual GPU Technology Conference keynote, NVIDIA's CEO Jen-Hsun Huang announced the company's first Volta GPU and Volta products. Taking aim at the very high end of the compute market with their first products, NVIDIA has laid out a very aggressive technology delivery schedule in order to bring about another major leap in GPU deep learning performance.
As a quick history lesson, NVIDIA first unveiled the Volta architecture name all the way back in 2013. What eventually happened with their architectures wasn’t what was originally announced – Maxwell and Volta became Maxwell, Pascal, and Volta – but Volta is the last GPU architecture on NVIDIA’s current public roadmap. Until now, all we’ve known about Volta is that it existed; NVIDIA has opted to focus on what’s directly in front of them (e.g. Pascal), one generation at a time.
So let’s talk Volta. For their first Volta products, NVIDIA is following a very similar path as they did with Pascal last year. Which is to say that they are kicking off their public campaign and product stack with a focus on business, HPC, and deep learning, rather than consumer GPUs. Volta is a full GPU architecture for both compute and graphics, but today’s announcements are all about the former. So the features unveiled today and as part of the first Volta GPU are all compute-centric.
NVIDIA’s first Volta GPU then is the aptly named GV100. The successor to the Pascal GP100, this is NVIDIA’s flagship GPU for compute, designed to drive the next generation of Tesla products.
| NVIDIA GPU Specification Comparison | |||||
| GV100 | GP100 | GK110 | |||
| CUDA Cores | 5376 | 3840 | 2880 | ||
| Tensor Cores | 672 | N/A | N/A | ||
| SMs | 84 | 60 | 15 | ||
| CUDA Cores/SM | 64 | 64 | 192 | ||
| Tensor Cores/SM | 8 | N/A | N/A | ||
| Texture Units | 336 | 240 | 240 | ||
| Memory | HBM2 | HBM2 | GDDR5 | ||
| Memory Bus Width | 4096-bit | 4096-bit | 384-bit | ||
| Shared Memory | 128KB, Configurable | 24KB L1, 64KB Shared | 48KB | ||
| L2 Cache | 6MB | 4MB | 1.5MB | ||
| Half Precision | 2:1 (Vec2) | 2:1 (Vec2) | 1:1 | ||
| Double Precision | 1:2 | 1:2 | 1:3 | ||
| Die Size | 815mm2 | 610mm2 | 552mm2 | ||
| Transistor Count | 21.1B | 15.3B | 7.1B | ||
| TDP | 300W | 300W | 235W | ||
| Manufacturing Process | TSMC 12nm FFN | TSMC 16nm FinFET | TSMC 28nm | ||
| Architecture | Volta | Pascal | Kepler | ||
Before we kick things off, one thing to make clear here - and this is something that I'll get into much greater detail when NVIDIA releases enough material for a proper deep dive - is that Volta is a brand new architecture for NVIDIA in almost every sense of the word. While the internal organization is the same much of the time, it's not Pascal at 12nm with new cores (Tensor Cores). Rather it's a significantly different architecture in terms of thread execution, thread scheduling, core layout, memory controllers, ISA, and more. And these are just the things NVIDIA is willing to talk about, never mind the ample secrets they still keep. So while I can only scratch the surface for today's reveal and will be focusing on basic throughput, Volta has a great deal going on under the hood to get to in the coming weeks.
But starting with the raw specficiations, the GV100 is something I can honestly say is a audacious GPU, an adjective I’ve never had a need to attach to any other GPU in the last 10 years. In terms of die size and transistor count, NVIDIA is genuinely building the biggest GPU they can get away with: 21.1 billion transistors, at a massive 815mm2, built on TSMC’s still green 12nm “FFN” process (the ‘n’ stands for NVIDIA; it’s a customized higher perf version of 12nm for NVIDIA).
To put this in perspective, NVIDIA’s previous record holder for GPU size was GP100 at 610mm2. So GV100, besides being on a newer generation process, is a full 33% larger. In fact NVIDIA has gone right to the reticle size of TSMC’s process; GV100 is as big a GPU as the fab can build. Now NVIDIA is not a stranger with reticle sizes, as GM200 happened to do the same thing with TSMC’s 28nm process, but at only 601mm2, GV100 is much larger still.
Now why the focus on die size first and foremost? At a high level, die size correlates well with performance. But more significantly, this is a very visible flag about how NVIDIA is pushing the envelope. The company is not discussing chip yields at this time, but such a large chip is going to yield very poorly, especially on the new 12nm FFN process. NVIDIA is going to be sacrificing a lot of silicon for a relatively small number of good chips, just so that they can sell them to eager customers who are going to pay better than $15K/chip. This is how badly NVIDIA’s customers want more powerful GPUs, and how hard NVIDIA is going to push the limits of modern fab technology to deliver it.
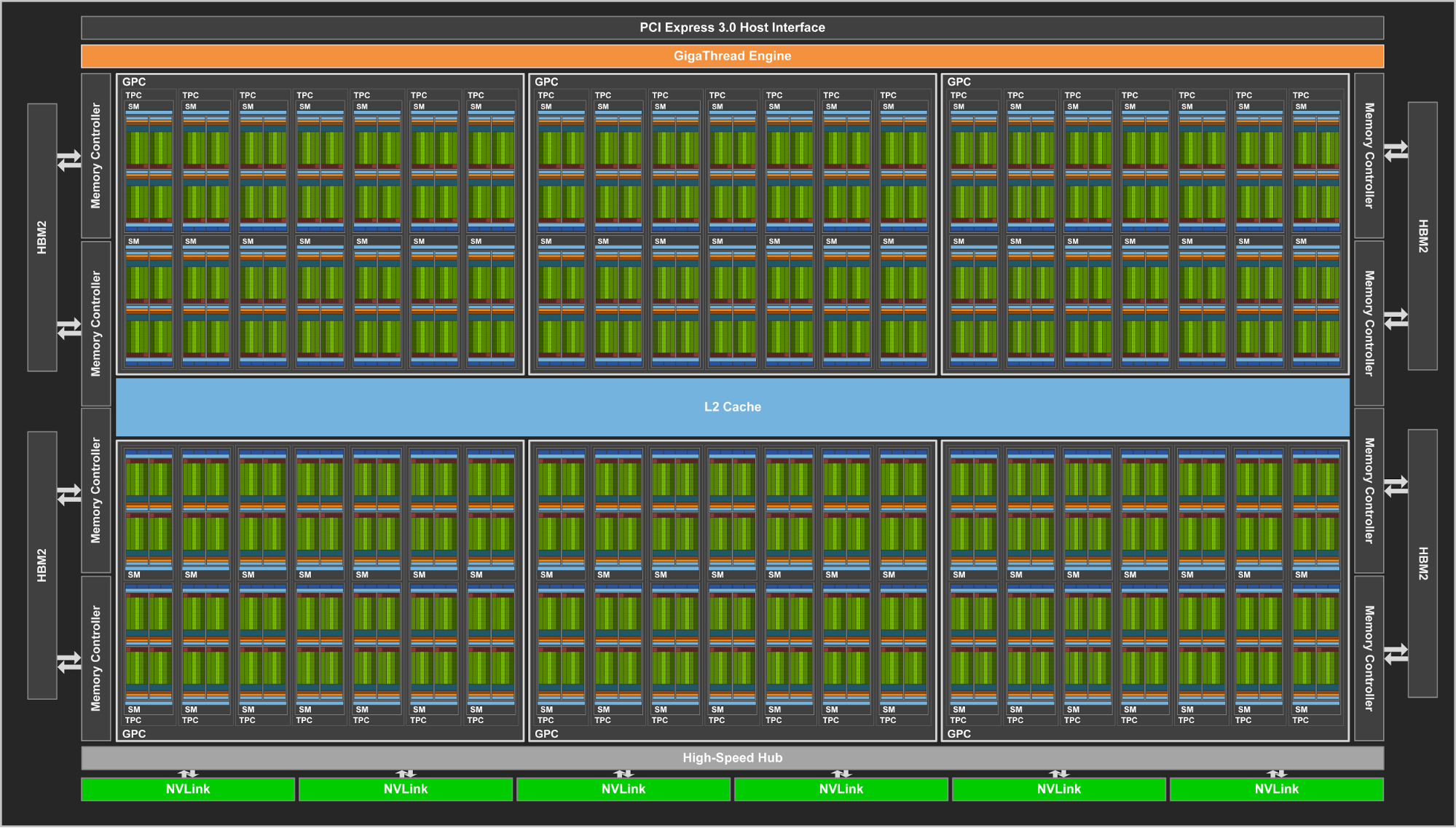
The chip’s absurd size aside, GV100 promises to be powerful. The chip contains 84 SMs – as this is a compute product, each SM is 64 CUDA cores in size – making for a total of 5376 FP32 CUDA cores. Joining those FP32 cores are 2688 FP64 CUDA cores (meaning NV is maintaining their 1:2 FP64 ratio), but also a new core that NVIDIA is calling the Tensor Core.
Tensor Cores are a new type of core for Volta that can, at a high level, be thought of as a more rigid, less flexible (but still programmable) core geared specifically for Tensor deep learning operations. These cores are essentially a mass collection of ALUs for performing 4x4 Matrix operations; specifically a fused multiply add (A*B+C), multiplying two 4x4 FP16 matrices together, and then adding that result to an FP16 or FP32 4x4 matrix to generate a final 4x4 FP32 matrix.
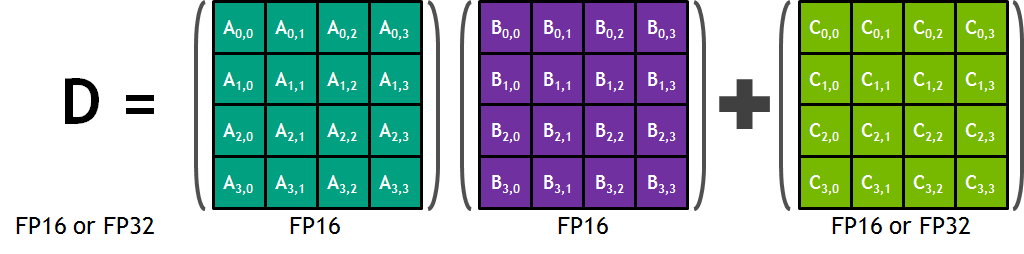
The significance of these cores are that by performing a massive matrix-matrix multiplication operation in one unit, NVIDIA can achieve a much higher number of FLOPS for this one operation. A single Tensor Core performs the equivalent of 64 FMA operations per clock (for 128 FLOPS total), and with 8 such cores per SM, 1024 FLOPS per clock per SM. By comparison, even with pure FP16 operations, the standard CUDA cores in an SM only generate 256 FLOPS per clock. So in scenarios where these cores can be used, NV is slated to be able to deliver 4x the performance versus Pascal.
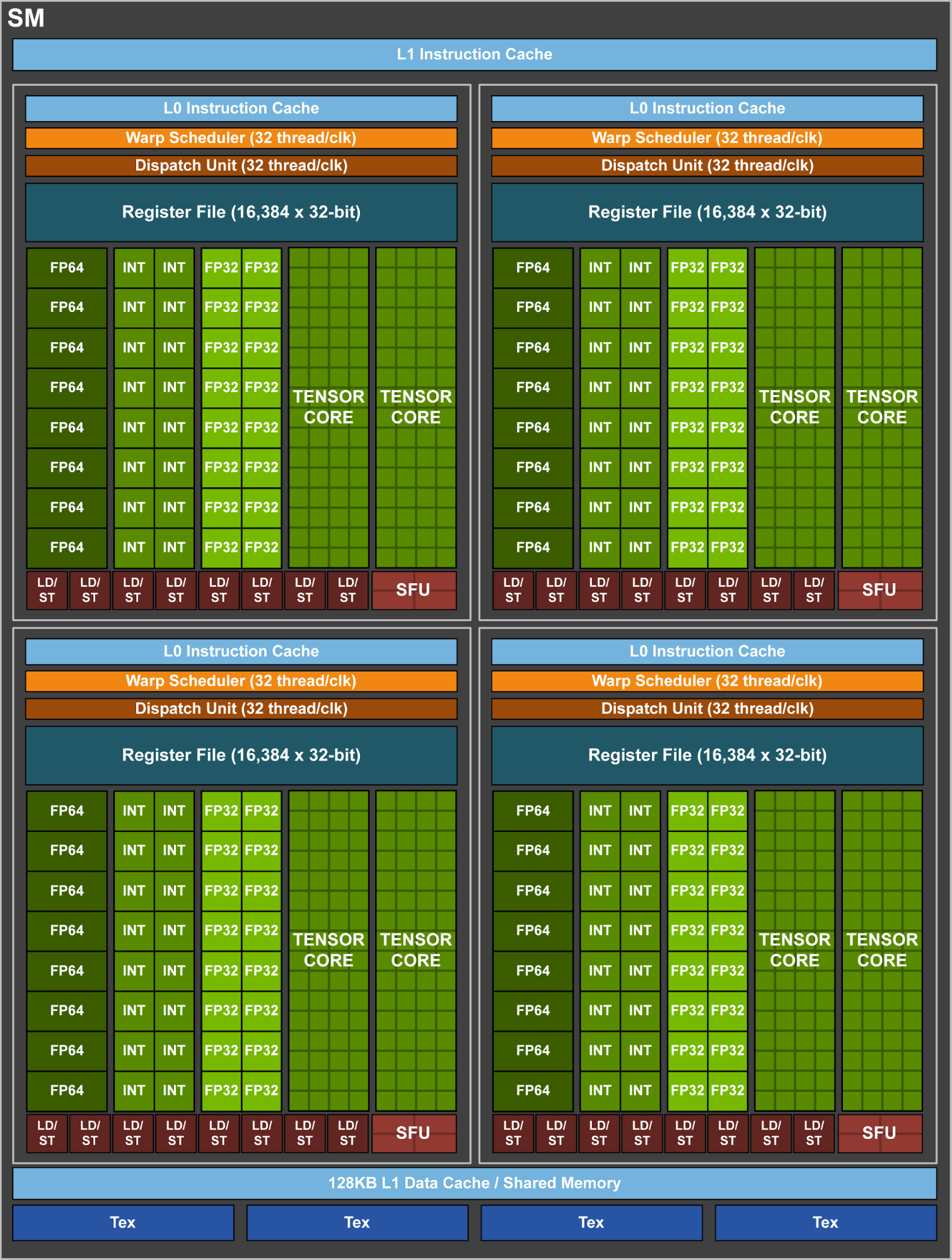
Now there are a bunch of unknowns here, including how flexible these cores are, and how much die space that they take up versus FP32 CUDA cores. But at a high level, this is looking like a relatively rigid core, which would make it very die-space efficient. By lumping together so many ALUs within a single core and without duplicating their control logic or other supporting hardware, the percentage of transistors in a core dedicated to ALUs is higher than on a standard CUDA core. The cost is flexibility, as the hardware to enable flexibility takes up space. So this is a very conscious tradeoff on NVIDIA’s part between flexibility and total throughput.
Continuing down the spec list, each SM contains 4 texture units, the same number as with the GP100. Joining those texture units is yet another rework of NVIDIA’s L1 cache/shared memory architecture. Whereas GP100 had a 24KB L1/Texture cache and 64KB shared memory per SM, on GV100 it’s now a 128KB of L1 data cache/shared memory per SM, with the precise L1/shared memory split being configurable. Besides unifying these caches, this means there’s more cache/memory overall, 40KB more per SM. On the other hand, the register file remains unchanged at 256KB of registers (4x16K 32-bit registers) per SM.
At a higher level, the 84 SMs are organized 2 to a TPC, just as with GP100, giving us a 42 TPC count. These TPCs are in turn organized 7 to a GPC, and then 6 GPCs. Feeding the beast is once again HBM2, with NVIDIA using 4 stacks of it like GP100. It’s interesting to note here that while memory clocks have only increased by 25% for the respective Tesla SKUs, NVIDIA is claiming a 50% increase in effective memory bandwidth due to a combination of that and better memory efficiency. Meanwhile the L2 cache system between the memory and GPCs has also been enhanced; there’s now 768KB of L2 cache per ROP/memory partition, versus 512KB on GP100. This means L2 cache for the whole chip now stands at 6MB.
Going to a higher level still, Volta also implements a newer version of NVLink. This is the previously announced NVLink 2, and along with greater link bandwidth – up from 20GB/sec bidirectional to 25GB/sec bidirectional – there are now 6 NVLinks per GPU for GV100, 2 more than on GP100. Critically, NVLInk 2 also introduces cache coherency allowing the GPUs to be cache coherent with CPUs. Expect to see this play a big part in the eventual Power 9 + Volta systems.
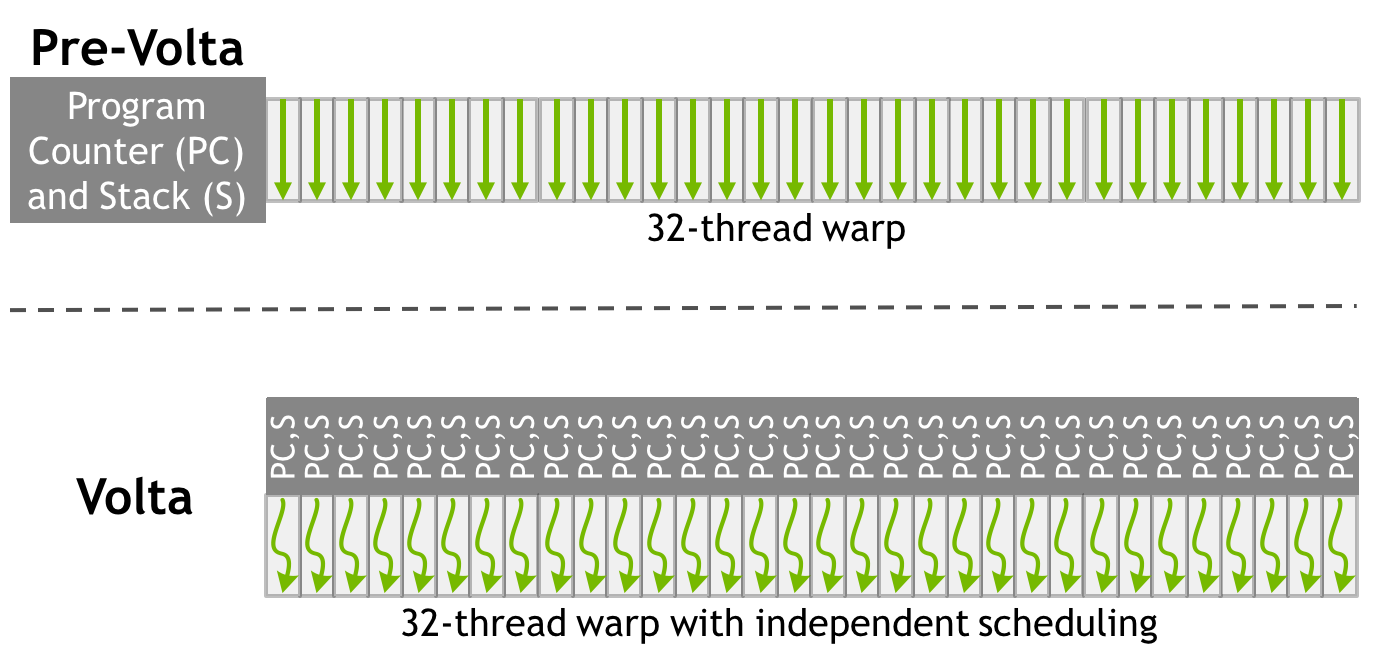
Finally, while the full details on this will have to wait until later, NVIDIA has also unveiled that they’ve made a pretty significant change to how SIMT works for Volta. The individual CUDA cores within a 32-thread warp now have a limited degree of autonomy; threads can now be synchronized at a fine-grain level, and while the SIMT paradigm is still alive and well, it means greater overall efficiency. Importantly, individual threads can now yield, and then be rescheduled together. This also means that a limited amount of scheduling hardware is back in NV’s GPUs.
Overall, GV100 is a 3 billion dollar R&D project for NVIDIA, their largest project to date for their largest GPU to date. NV is expecting the first GV100 products to start shipping in Q3 of this year and they won’t be cheap – on the order of $18K per GPU for a DGX system – however for those customers with deep pockets and who will essentially pay NVIDIA to eat the risk of producing such a large GPU, this will be the most powerful GPU released yet.
Tesla V100
The first product to use the GV100 GPU is in turn the aptly named Tesla V100. Like its P100 predecessor, this is a not-quite-fully-enabled GV100 configuration. Overall, only 80 of 84 SMs are enabled for yield reasons.
| NVIDIA Tesla Family Specification Comparison | ||||||
| Tesla V100 | Tesla P100 | Tesla K40 | Tesla M40 | |||
| Stream Processors | 5120 | 3584 | 2880 | 3072 | ||
| Core Clock | ? | 1328MHz | 745MHz | 948MHz | ||
| Boost Clock(s) | 1455MHz | 1480MHz | 810MHz, 875MHz | 1114MHz | ||
| Memory Clock | 1.75Gbps HBM2 | 1.4Gbps HBM2 | 6Gbps GDDR5 | 6Gbps GDDR5 | ||
| Memory Bus Width | 4096-bit | 4096-bit | 384-bit | 384-bit | ||
| Memory Bandwidth | 900GB/sec | 720GB/sec | 288GB/sec | 288GB/sec | ||
| VRAM | 16GB | 16GB | 12GB | 12GB | ||
| Half Precision | 30 TFLOPS | 21.2 TFLOPS | 4.29 TFLOPS | 6.8 TFLOPS | ||
| Single Precision | 15 TFLOPS | 10.6 TFLOPS | 4.29 TFLOPS | 6.8 TFLOPS | ||
| Double Precision | 7.5 TFLOPS (1/2 rate) |
5.3 TFLOPS (1/2 rate) |
1.43 TFLOPS (1/3 rate) |
213 GFLOPS (1/32 rate) |
||
| GPU | GV100 (815mm2) |
GP100 (610mm2) |
GK110B | GM200 | ||
| Transistor Count | 21B | 15.3B | 7.1B | 8B | ||
| TDP | 300W | 300W | 235W | 250W | ||
| Cooling | N/A | N/A | Active/Passive | Passive | ||
| Manufacturing Process | TSMC 12nm FFN | TSMC 16nm FinFET | TSMC 28nm | TSMC 28nm | ||
| Architecture | Volta | Pascal | Kepler | Maxwell 2 | ||
By the numbers, Tesla V100 is slated to provide 15 TFLOPS of FP32 performance, 30 TFLOPS FP16, 7.5 TFLOPS FP64, and a whopping 120 TFLOPS of dedicated Tensor operations. With a peak clockspeed of 1455MHz, this marks a 42% increase in theoretical FLOPS for the CUDA cores at all size. Whereas coming from Pascal, for Tensor operations the gains will be closer to 6-12x, depending on the operation precision.
The Tesla V100 will be paired with 16GB of HBM2. At this time no one is producing an 8-Hi HBM2 stack, so NVIDIA cannot expand their memory capacity at 4 stacks. However the memory clockspeed has improved by 25% over Tesla P100, from 1.4Gbps to 1.75Gbps.
Also like the Tesla P100, NVIDIA is using a mezzanine card. They have not shown the new connector – expect it to have more pins to account for the additional NVLinks – but the overall size is similar. NVIDIA calls this the SXM2 form factor.
In terms of power consumption, Tesla V100 will have a TDP of 300W, like its predecessor. NVIDIA notes that power efficiency of V100 is higher than P100, though it will be interesting to see just where this stands, and how often the card actually power throttles.
The first product to ship with Tesla V100 will be the NVIDIA DGX-1V, the Volta version of their DGX server. Similar to their Pascal launch, starting with DGX sales allows NVIDIA to sell 8 GPUs in one go, and for a premium at that. A DGX-1V will set you back a cool $149,000. The payoff? It ships in Q3, whereas OEM P100 designs won’t be available until Q4.

Finally, along with the mezzanine version, NVIDIA has also announced two PCIe versions of the V100. The first is a full size 250W card, analogous to the PCIe Tesla P100. The second is a smaller full height half length PCIe card, which for now is being dubbed the “Tesla V100 for Hyperscale Inference”. This is a 150W card, and is specifically meant for dense configurations in datacenter inference servers. The specifications have not been published yet, but given that it has half the TDP of the mezzanine card, it’s a safe bet that it’s clocked lower and features more disabled SMs than the full fat version.








179 Comments
View All Comments
CiccioB - Thursday, May 11, 2017 - link
This 12nm process does not increment density but energy saving and most of all production cost as it uses less masks and allow for much bigger die sizes like this monstrous one.peevee - Monday, May 15, 2017 - link
That is true. The "nodes" were BS after 32nm. Even Intel's 10nm is BS too.medi02 - Thursday, May 11, 2017 - link
MI25 promised 12.5 TFlops vs 15Tlops in this thing.Not that big of a difference.
PS
Oh, and market is rather small so far.
theuglyman0war - Sunday, May 14, 2017 - link
I love how Nvidia has gone large on the die to own. If moore's law is dead the performance limit is still only limited by the size of the universe.Since the power consumption complaints of GTX480 I have always felt that power cost has always been exaggerated for desktop use ( after I actually added up 16 hours a day 7 days a week on that tri -sli and laffed at the trivial ( relatively compared to enthusiast expense ) cost! )
hanssonrickard - Thursday, May 18, 2017 - link
http://www.anandtech.com/show/11403/amd-unveils-th...zepi - Wednesday, May 10, 2017 - link
When Nvidia can make about $15k from each 800mm2 die manufacturing V100's, it really has no good reason to do 400mm2 GV104's it can at maximum sell for $600 each...And as long as the price discrepancy keeps being this huge, they'll rather sell 4x GV100 "workstations" for $69k and 8x GV100 DGX-1 rack-servers for $149k.
vladx - Wednesday, May 10, 2017 - link
Yes but these high compute GPUs pay for keeping all the consumer parts that much cheaperjjj - Wednesday, May 10, 2017 - link
Quite the opposite nowadays really.Consumer parts are funding the development of these monsters.
AMD gave Nvidia the opportunity to keep prices high above 300$ and they did that just when high FPS, high res and VR pushed the consumer's needs up.
vladx - Thursday, May 11, 2017 - link
Not the point, if these high domain cards weren't in play, Nvidia would've had to ramp their prices even higher for their consumer line. Just selling a few thousand of these monsters is good enough.Eliadbu - Wednesday, May 10, 2017 - link
you are totally wrong, those cards Nvidia wont sell them as near as much of consumer grade cards, and the consumers cards eventually will produce much higher earnings then those compute cards since they sell so much more units. remember that big part of the costs of the cards is not the fabrication of the die and manufacturing of the card , but R&D, 3 billions $ were put for this card development, and if you want to counter it, you need to sell more units since each unit would take less of the costs of R&D.