AMD Zen Microarchiture Part 2: Extracting Instruction-Level Parallelism
by Ian Cutress on August 23, 2016 8:45 PM EST- Posted in
- CPUs
- AMD
- x86
- Zen
- Microarchitecture
Some Final Thoughts and Comparisons
With the Hot Chips presentation we’ve been given more information on the Zen core microarchitecture than we expected to have at this point in the Zen design/launch cycle. AMD has already stated that general availability for Zen will be in Q1, and Zen might not be the final product launch name/brand when it comes to market. However, there are still plenty of gaps in our knowledge for the hardware, and AMD has promised to reveal this information as we get closer to launch.
We discussed in our earlier piece on the Zen performance metrics given mid-week that it can be hard to interpret any anecdotal benchmark data at this point when there is so much we don’t know (or can’t confirm). With the data in this talk at Hot Chips, we can fill out a lot of information for a direct comparison chart to AMD’s last product and Intel’s current offerings.
| CPU uArch Comparison | ||||
| AMD | Intel | |||
| Zen 8C/16T 2017 |
Bulldozer 4M / 8T 2010 |
Skylake 4C / 8T 2015 |
Broadwell 8C / 16T 2014 |
|
| L1-I Size | 64KB/core | 64KB/module | 32KB/core | 32KB/core |
| L1-I Assoc | 4-way | 2-way | 8-way | 8-way |
| L1-D Size | 32KB/core | 16KB/thread | 32KB/core | 32KB/core |
| L1-D Assoc | 8-way | 4-way | 8-way | 8-way |
| L2 Size | 512KB/core | 1MB/thread | 256KB/core | 256KB/core |
| L2 Assoc | 8-way | 16-way | 4-way | 8-way |
| L3 Size | 2MB/core | 1MB/thread | >2MB/cire | 1.5-3MB/core |
| L3 Assoc | 16-way | 64-way | 16-way | 16/20-way |
| L3 Type | Victim | Victim | Write-back | Write-back |
| L0 ITLB Entry | 8 | - | - | - |
| L0 ITLB Assoc | ? | - | - | - |
| L1 ITLB Entry | 64 | 72 | 128 | 128 |
| L1 ITLB Assoc | ? | Full | 8-way | 4-way |
| L2 ITLB Entry | 512 | 512 | 1536 | 1536 |
| L2 ITLB Assoc | ? | 4-way | 12-way | 4-way |
| L1 DTLB Entry | 64 | 32 | 64 | 64 |
| L1 DTLB Assoc | ? | Full | 4-way | 4-way |
| L2 DTLB Entry | 1536 | 1024 | - | - |
| L2 DTLB Assoc | ? | 8-way | - | - |
| Decode | 4 uops/cycle | 4 Mops/cycle | 5 uops/cycle | 4 uops/cycle |
| uOp Cache Size | ? | - | 1536 | 1536 |
| uOp Cache Assoc | ? | - | 8-way | 8-way |
| uOp Queue Size | ? | - | 128 | 64 |
| Dispatch / cycle | 6 uops/cycle | 4 Mops/cycle | 6 uops/cycle | 4 uops/cycle |
| INT Registers | 168 | 160 | 180 | 168 |
| FP Registers | 160 | 96 | 168 | 168 |
| Retire Queue | 192 | 128 | 224 | 192 |
| Retire Rate | 8/cycle | 4/cycle | 8/cycle | 4/cycle |
| Load Queue | 72 | 40 | 72 | 72 |
| Store Queue | 44 | 24 | 56 | 42 |
| ALU | 4 | 2 | 4 | 4 |
| AGU | 2 | 2 | 2+2 | 2+2 |
| FMAC | 2x128-bit | 2x128-bit 2x MMX 128-bit |
2x256-bit | 2x256-bit |
Bulldozer uses AMD-coined macro-ops, or Mops, which are internal fixed length instructions and can account for 3 smaller ops. These AMD Mops are different to Intel's 'macro-ops', which are variable length and different to Intel's 'micro-ops', which are simpler and fixed-length.
Excavator has a number of improvements over Bulldozer, such as a larger L1-D cache and a 768-entry L1 BTB size, however we were never given a full run-down of the core in a similar fashion and no high-end desktop version of Excavator will be made.
This isn’t an exhaustive list of all features (thanks to CPU World, Real World Tech and WikiChip for filling in some blanks) by any means, and doesn’t paint the whole story. For example, on the power side of the equation, AMD is stating that it has the ability to clock gate parts of the core and CCX that are not required to save power, and the L3 runs on its own clock domain shared across the cores. Or the latency to run certain operations, which is critical for workflow if a MUL operation takes 3, 4 or 5 cycles to complete. We have been told that the FPU load is two cycles quicker, which is something. The latency in the caches is also going to feature heavily in performance, and all we are told at this point is that L2 and L3 are lower latency than previous designs.
A number of these features we’ve already seen on Intel x86 CPUs, such as move elimination to reduce power, or the micro-op cache. The micro-op cache is a piece of the puzzle we want to know more about, especially the rate at which we get cache hits for a given workload. Also, the use of new instructions will adjust a number of workloads that rely on them. Some users will lament the lack of true single-instruction AVX-2 support, however I suspect AMD would argue that the die area cost might be excessive at this time. That’s not to say AMD won’t support it in the future – we were told quite clearly that there were a number of features originally listed internally for Zen which didn’t make it, either due to time constraints or a lack of transistors.
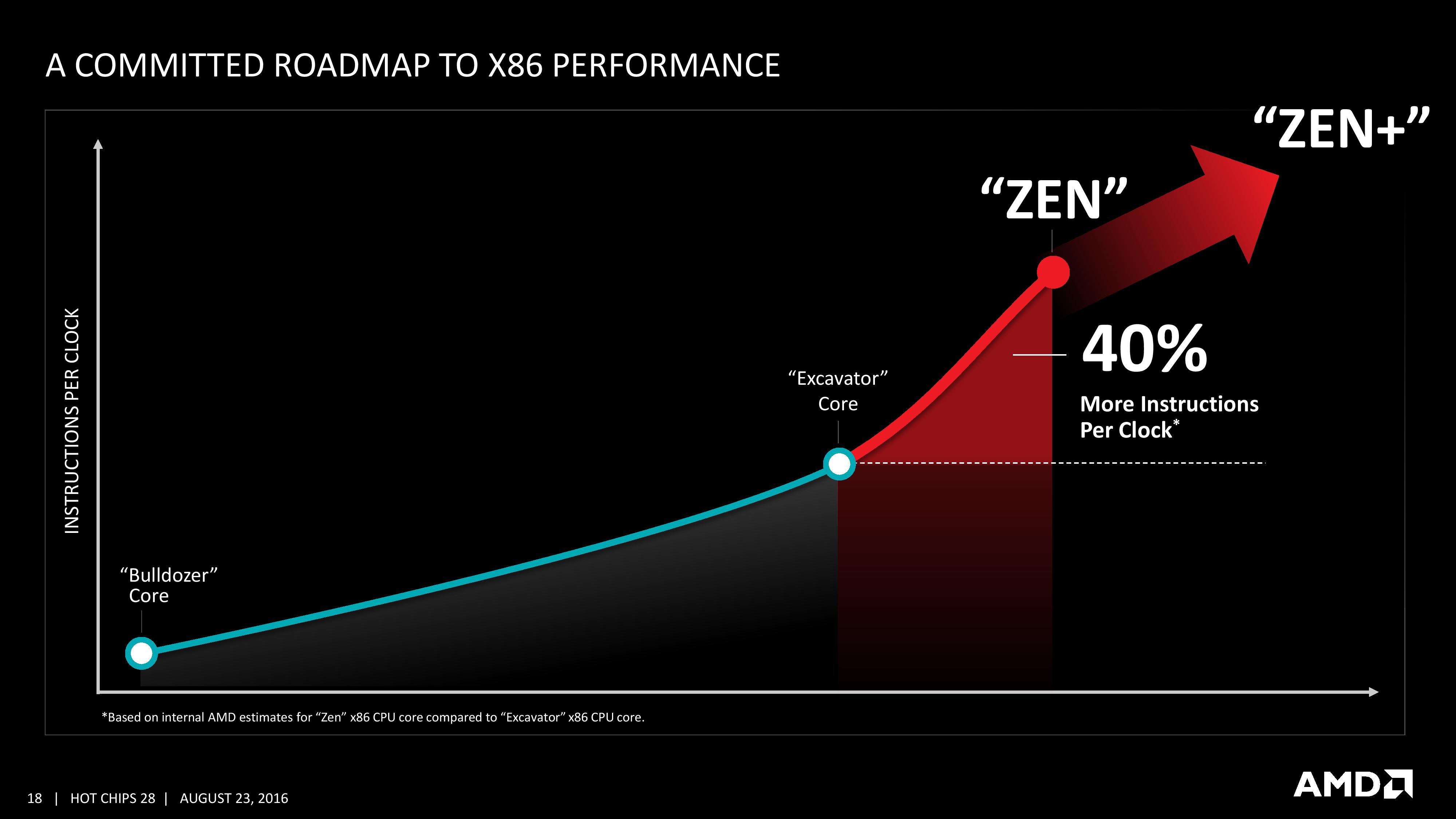
We are told that AMD has a clear internal roadmap for CPU microarchitecture design over the next few generations. As long as we don’t stay for so long on 14nm similar to what we did at 28/32nm, with IO updates over the coming years, a competitive clock-for-clock product (even to Broadwell) with good efficiency will be a welcome return.








106 Comments
View All Comments
Bulat Ziganshin - Wednesday, August 24, 2016 - link
I think it's obvious from number of ALUs that 40% improvement is for scalar single-thread code that greartly bemnefits from access to all 4 integer ALUs. Of course, it will get the same benefit fro any code running up to 8 threads (for 8-core Zen). But anyway it should be slower than KabyLake since Intel spent much more time optimizng their CPUsFor m/t execution, improvements will be much smaller, 10-20%, i think. Plus, 8-core CPU will probably run at smaller frequency than 4-core Buldozers or 4-core KabyLake. AFAIK, even Intel 8c-ore CPUs run at 3.2 GHz only, and it's after many years of power optimization. We also know that *selected* Zen cpus run at 3.2 GHz in benchamrks. So, i expect either < 3 GHz frequency, or 200 Wt power budget
atomsymbol - Wednesday, August 24, 2016 - link
"For m/t execution, improvements will be much smaller, 10-20%, i think."There are bottlenecks in Bulldozer-family when a module is running two threads. An improvement of 40% for m/t Zen execution in respect to Bulldozer m/t execution is possible. It is a question of what the baseline of measurement is.
Bulat Ziganshin - Wednesday, August 24, 2016 - link
M/t execution in Bulldozer already can use all 4 INT alus, so i think that 40% IPC improvement is impossible. In other words, if s/t IPC improved by 40% by moving from 2 alu to 4 alu arrangement, m/t performance that keeps the same 4 alu arrangement, hardly can be improved by more than 20%looncraz - Wednesday, August 24, 2016 - link
IPC is NOT MT, it is ST only.IPC is per-core, per-thread, per-clock, instruction retire rate... which generally equates to performance per clock per core per thread.
Bulat Ziganshin - Thursday, August 25, 2016 - link
you can measure instruction per cycles for a thread, 3 threads, core, cpu or anything else. what's a problem??My point is that s/t speed on Zen is improved much more than m/t speed, compared to last in Bulldozer family. So, they advertized improvement in s/t speed, that is 40%. And m/t improvement is much less since it still the same 4 alus (although many other parts become wider).
atomsymbol - Thursday, August 25, 2016 - link
AMD presentation was comparing Zen to Broadwell in a m/t workload with all CPU cores utilized.From
http://www.cpu-world.com/Compare/528/AMD_A10-Serie...
you can compute that the Blender-specific speedup of Zen over a previous AMD design is about 100/38.8=2.57
Bulat Ziganshin - Thursday, August 25, 2016 - link
Can you compute IPC improvement, that we are discussing here?looncraz - Thursday, August 25, 2016 - link
Except you're absolutely wrong, the performance increases will be much higher for MT than ST.Bulldozer was hindered by the module design, so you had poor MT scaling - not an issue with Zen. On top of that, Zen has SMT, which should add another 20% or so more MT performance for the same number of cores.
A 40% ST improvement for Zen could easily mean a 100% performance improvement for MT.
Bulat Ziganshin - Saturday, August 27, 2016 - link
It's not "on top of that". Zen is pretty simple Bulldozer modification that fianlly allowed to use all 4 scalar ALUs in the module for the single thread. It's why scalar s/t perfroamnce should be 40% faster. OTOH, two threads in the module still share those 4 scalar ALUs as before, so m/t perfromance cannot improve much. On top of that, module was renamed to core. So, there are 2x more cores now and of course m/t performance of entire CPU will be 2x higherNenad - Thursday, September 8, 2016 - link
It is possible that AMD already count SMT (hyperthreading) into those 40%.Their slide which states "40% IPC Performance Uplift" also lists all things that AMD used to achieve those 40%...and first among those listed things is "Two threads per core". So if AMD already counted that into their 40% IPC uplift, then 'real' IPC improvement (for single thread) would be much lower.