Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
Soft Machines
To put it succinctly, having a thread take resources from multiple cores - when the performance can be extracted - sounds like the long-desired solution to the problem making multi-core designs more useful in lightly-threaded scenarios. Having multiple threads use resources on a single core on the same clock cycle is an even bigger leap in the same direction. Now obviously Soft Machines didn’t come up with this overnight.

Soft Machines came out of stealth mode at the 2014 Linley Conference. Their main goal was to increase performance-per-watt using better IPC designs, which is often one of the better ways if you can keep a design fed with data. One big challenge to this is that IPC has been somewhat flat these past few years - we're seeing small sub-10% yearly increases from the big players using standard designs. Soft Machines were already six years old at the time, with $150M+ raised from investors that include Samsung Ventures, GlobalFoundries, AMD, Mubadala and others (with another $25M since). If those names all seem interlinked, it’s because they all have historic business or investment dealings with each other (AMD/GloFo, Samsung/GloFo, AMD/Mubadala etc.). The team at Soft Machines is 250+ strong, with ex Intel, ex Qualcomm, ex AMD engineers on staff from processor design to platform architects. Half the staff is currently located in California.
At the 2014 conference, aside from explaining what they were doing, Soft Machines also exhibited working silicon of their design. The first generation proof of concept was fabbed at 28nm at TSMC and running at 500 MHz.

It seems odd to say that it was done at TSMC, especially with Samsung and Global Foundries as investors. We were told that this was due to timing and positioning with IP more than anything else, and the same is true for the next generation at 16nm FF+, rather than 14nm.
VISC and Roadmaps
The first generation chip wasn’t perfect – there were some design flaws in silicon that required specific workarounds relating to cache flushing and various methods, but at the time it was compared to a single thread Cortex A15 running at a similar frequency in a Samsung processor. The results with SPEC2000, SPEC2006, Denbench and Kraken gave a corresponding IPC relative to A15 of 1.5x to 7x, or as Soft Machines likes to put it: 3-4x "on average." It was estimated that access to a second physical core improves performance by an average of 50-60%, or an average IPC of 1.3 per core compared to 0.71 for Cortex A15, which explains the 3-4x average.
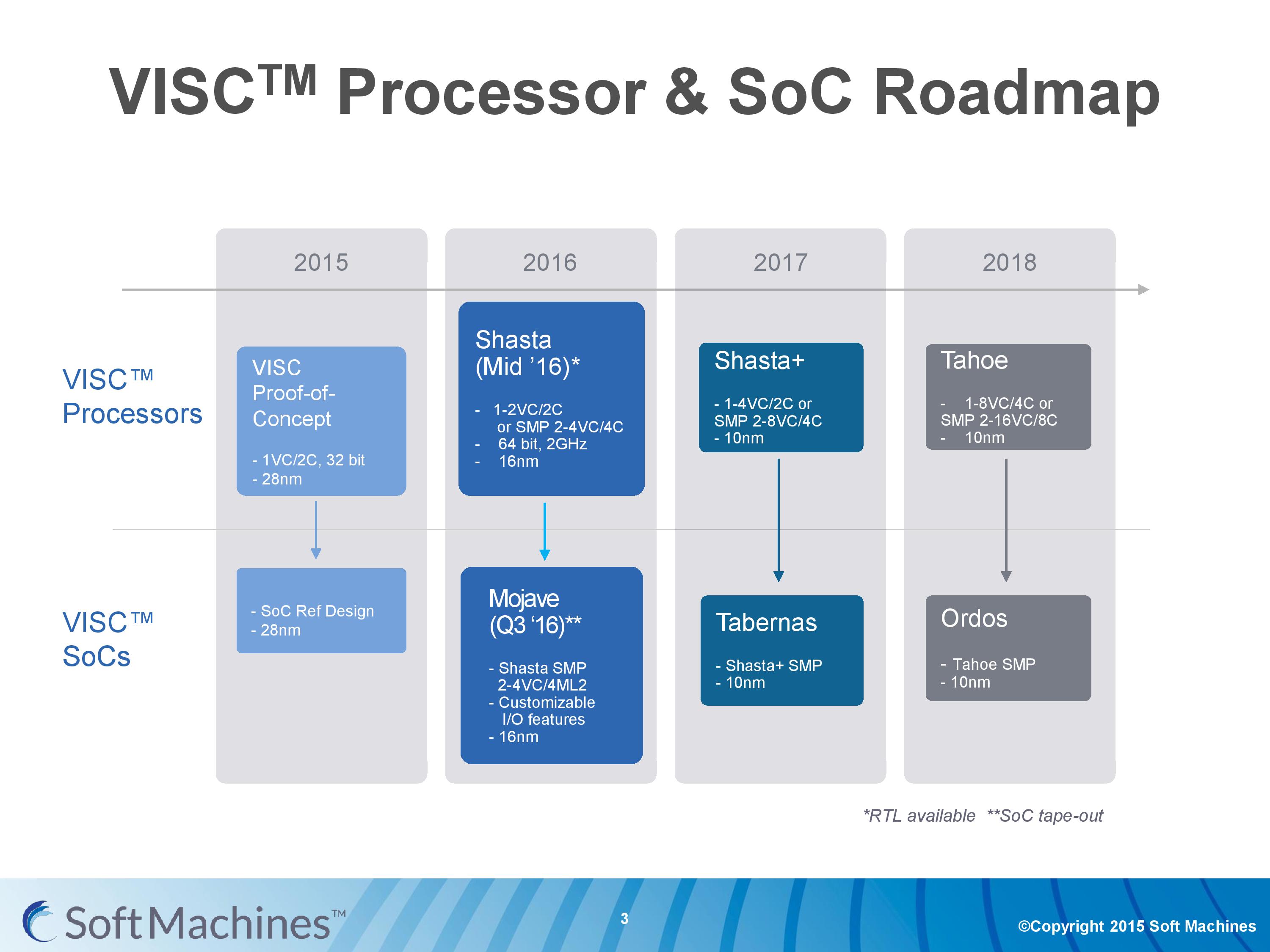
The roadmap for Soft Machines put their second generation VISC core, Shasta, in line for 2016. It was formally announced at the 2015 Linley Conference, with this month’s announcement being more about availability for licensing on 16FF+. The Shasta core on this node is designed as a 2C/2VC design, or two of these can be put together using a custom protocol interconnect to form a dual 2C/2VC design.
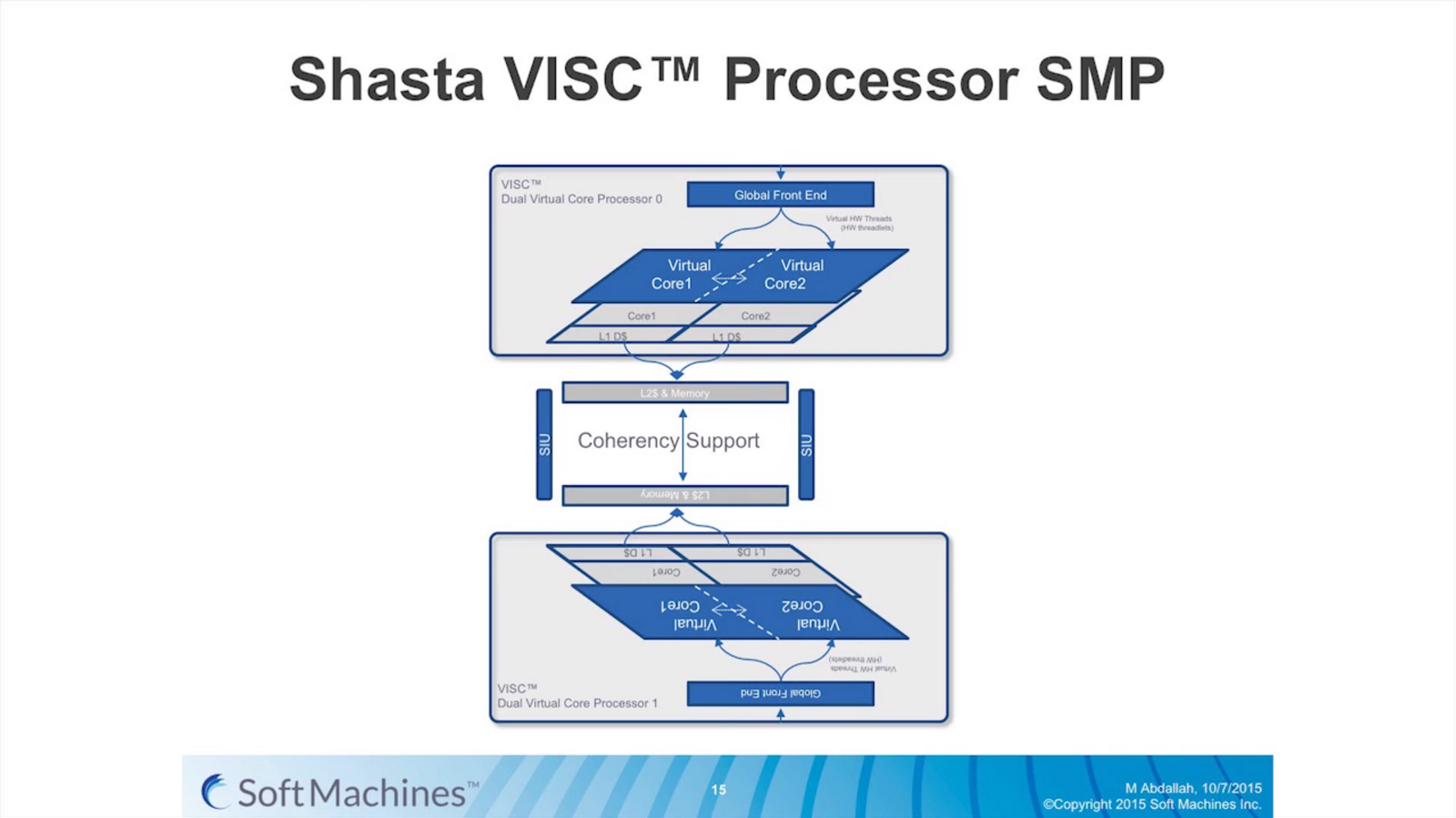
The custom interconnect fabric here is capable of over 200 GB/s, although in current designs only a single interface is present, allowing only two chips to be connected.
The dual processor design is going to be part of the Mojave IP as a fully integrated SoC.
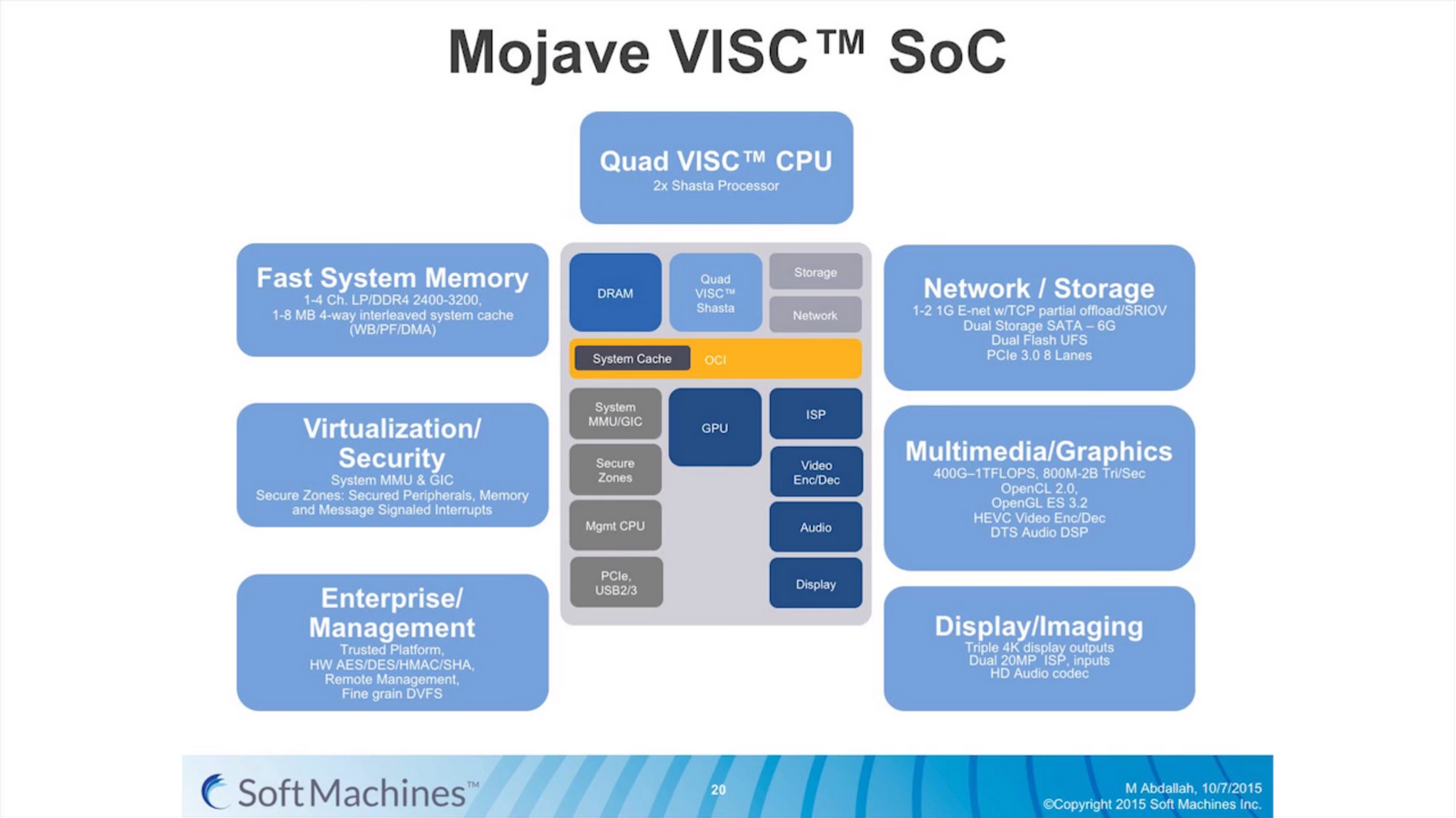
Along with the requisite VISC cores, the Mojave SoC includes PowerVR graphics, a DDR4 memory controller, virtualization management, a PCIe root complex capable of eight lanes of PCIe 3.0, USB ports, support for SATA, UFS, OpenCL 2.0 and other standards.
Looking forward, Soft Machines would like to see production move to 10nm in 2017 to take advantage of further power and area scaling. Meanwhile along that same timeframe they also want to expand the Shasta design to allow for four virtual cores per two physical cores, essentially allowing more threads to be in flight at one time and fully use the resources better. 2018 sees the move to four physical cores and eight virtual cores per design, while still supporting SMP and SoC designs as well.








97 Comments
View All Comments
ddriver - Saturday, February 13, 2016 - link
All abbreviations are capitalized, not just acronyms, idiot. Whether it is an acronym or not depends on how it is pronounced.erple2 - Saturday, March 12, 2016 - link
Enough people confuse initialisms and acronym that it probably doesn't matter anymore.FunBunny2 - Friday, February 12, 2016 - link
If SMI wants this to be believed, then just publish a paper (in a peer reviewed journal) showing how VISC invalidates Amdahl's Law. This is, after all, what they're really claiming.willis936 - Friday, February 12, 2016 - link
Could you explain how they're claiming to invalidate Amdahl's law ?FunBunny2 - Friday, February 12, 2016 - link
as I read the piece, SMI is implying/claiming performance improvement in running serial code in a parallel fashion, and Amdahl says you can't do that. if, OTOH, the claim is that VISC is able to suss out parallel execution in superficially serial code, then that process has to be proven to exist algorithmically. as the piece goes to some length to describe, based on what's been provided by SMI, it much like smoke and mirrors.Arnulf - Friday, February 12, 2016 - link
I read their claims as an expansion of superscalar design. Nothing new here and certainly nothing breaking any "laws". It still cannot magically make non-parallelizable code run faster than it normally would.Samus - Monday, February 15, 2016 - link
If their decoder can break up serial code and run it through different cores optimized to do different things better, this would theoretically complete the code faster because their will be no pipeline penalty.Personally. I think we have better odds of seeing a quantum processor before this type of thing taking off, though. That is to say, no time soon.
gamerk2 - Friday, February 12, 2016 - link
Kinda. There will still be a limited performance simply because some operations can not be made parallel under any circumstances, but Soft Machines is really taking ILP to the extreme here.xthetenth - Friday, February 12, 2016 - link
No it really isn't and you're profoundly misunderstanding Amdahl's law. All that says is how much an improvement to a portion of a workload's execution speed will affect the workload as a whole's execution speed. Meanwhile what they're doing is trying to extract parallelism from single threads, which means that they're speeding up a greater fraction of the code. Funnily enough, you can use Amdahl's law to predict when this method (shrinking the non-improved section to allow higher maximum speed) is more effective than things like clocking higher.I suspect what you're doing is confusing the law with an explanation/common use of the law because it is very popular to use it to show there's a limit on the gains that can be made by parallel processors.
Drumsticks - Friday, February 12, 2016 - link
It doesn't really invalidate Amdahl's Law. Serial code still can't be run on multiple cores. As I understand it, it only allows extracting more ILP using an ultra ultra wide design when possible.