Exploring DirectX 12: 3DMark API Overhead Feature Test
by Ryan Smith & Ian Cutress on March 27, 2015 8:00 AM EST- Posted in
- GPUs
- Radeon
- Futuremark
- GeForce
- 3DMark
- DirectX 12
Discrete GPU Testing
We’ll kick things off with our discrete GPUs, which should present us with a best case scenario for DirectX 12 from a hardware standpoint. With the most powerful CPUs powering the most powerful GPUs, the ability to generate a massive number of draw calls and to have them consumed in equally large number, this is where DirectX 12 will be at its best.
We’ll start with a look a CPU scaling on our discrete GPUs. How much benefit do we see going from 2 to 4 and finally 6 CPU cores?
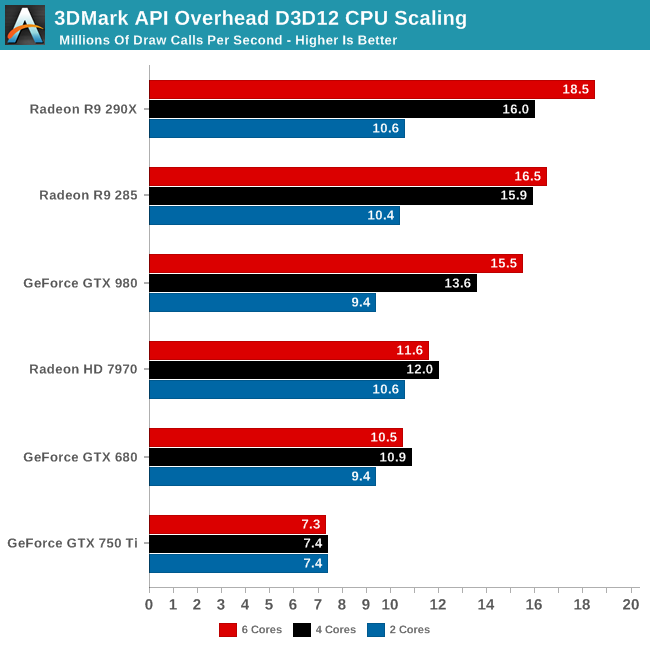
The answer on the CPU side is quite a lot. Whereas Star Swarm generally topped out at 4 cores – after which it was often GPU limited – we see gains all the way up to 6 cores on our most powerful cards. This is a simple but important reminder of the fact that the AOFT is a synthetic test designed specifically to push draw calls and avoid all other bottlenecks as much as possible, leading to increased CPU scalability.
With that said, it’s clear that we’re reaching the limits of our GPUs with 6 cores. While the gains from 2 to 4 cores are rather significant, increasing from 4 to 6 (and with a slight bump in clockspeed) is much more muted, even with our most powerful cards. Meanwhile anything slower than a Radeon R9 285X is showing no real scaling from 4 to 6 cores, indicating a rough cutoff right now of how powerful a card needs to be to take advantage of more than 4 cores.
Moving on, let’s take a look at the actual API performance scaling characteristics at 6, 4, and 2 cores.
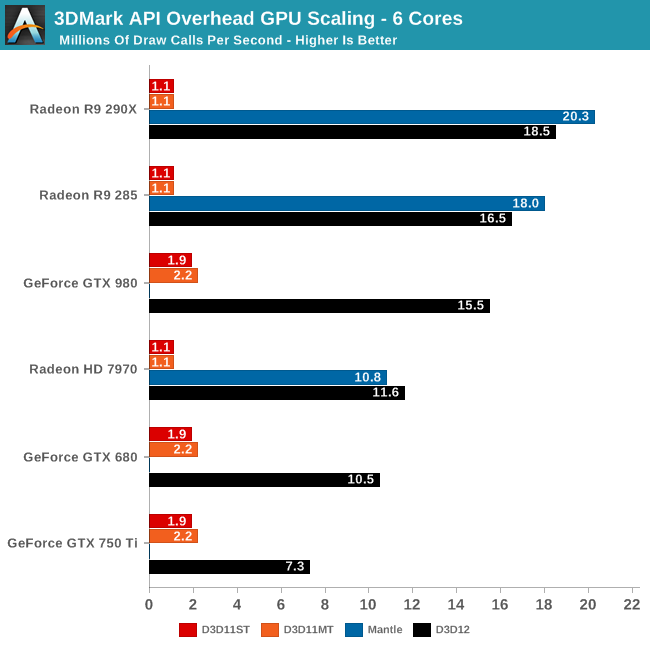
6 cores of course is a best case scenario for DirectX 12 – it’s the least likely to be CPU-bound – and we see first-hand the incredible increase in draw call throughput by switching from DirectX 11 to DirectX 12 or Mantle.
Somewhat unexpectedly, the greatest gains and the highest absolute performnace are achieved by AMD’s Radeon R9 290X. As we saw in Star Swarm and continue to see here, AMD’s DirectX 11 throughput is relatively poor, topping out at 1.1 draw calls for both DX11ST and DX11MT. AMD simply isn’t able to push much more than that many calls through their drivers, and without real support for DX11 multi-threading (e.g. DX11 Dirver Command Lists), they gain nothing from the DX11MT test.
But on the opposite side of the coin, this means they have the most to gain from DirectX 12. The R9 290X sees a 16.8x increase in draw call throughput switching from DX11 to DX12. At 18.5 million draw calls per second this is the highest draw call rate out of any of our cards, and we have good reason to suspect that we’re GPU command processor limited at this point. Which is to say that our CPU could push yet more draw calls if only a GPU existed that could consumer that many calls. On a side note, 18.5M calls would break down to just over 300K calls per frame at 60fps, which is a similarly insane number compared to today’s standards where draw calls per frame in most games is rarely over 10K.
Meanwhile we see a reduction in gains going from the 290X to the 285 and finally to the 7970. As we mentioned earlier we appear to be command processor limited, and each one of these progressively weaker GPUs appears to contain a similarly weaker command processor. Still, even the “lowly” 7970 can push 11.6M draw calls per second, which is a 10.5x (order of magnitude) increase in draw call performance over DirectX 11.
Mantle on the other hand presents an interesting aside. As AMD’s in-house API (and forerunner to Vulkan), the AMD cards do even better on Mantle than they do DirectX 12. At this point the difference is somewhat academic – what are you going to do with 20.3M draw calls over 18.5M – but it goes to show that Mantle can still squeeze out a bit more at times. It will be interesting to see whether this holds as Windows 10 and the drivers are finalized, and even longer term whether these benefits are retained by Vulkan.
As for the NVIDIA cards, NVIDIA sees neither quite the awesome relative performance gains from DirectX 12 nor enough absolute performance to top the charts, but here too we see the benefits of DirectX 12 in full force. At 1.9M draw calls per second in DX11ST and 2.2M draw calls per second in DX11MT, NVIDIA starts out in a much better position than AMD does; in the latter they essentially can double AMD’s DX11MT throughput (or alternatively have half the API overhead).
Once DX12 comes into play though, NVIDIA’s throughput rockets through the roof as well. The GTX 980 sees an 8.2x increase over DX11ST, and a 7x increase over DX11MT. On an absolute basis the GTX 980 is consuming 15.5M draw calls per second (or about 250K per frame at 60fps), showing that even the best DX11 implementation can’t hold a candle to this early DirectX 12 implementation. The benefits of DirectX 12 really are that great for draw call performance.
Like AMD, NVIDIA seems to be command processor limited here. GPU-Z reports 100% GPU usage in the DX12 test, indicating that by NVIDIA’s internal metrics the card is working as hard as it can. Meanwhile though not charted, I also tested a GTX Titan X here, which achieved virtually the exact same results as the GTX 980. In lieu of more evidence to support being CPU bound, I have to assume that the GM200 GPU uses a similar command processor as the GM204 based GTX 980, leading to a similar bottleneck. Which would make some sense, as the GM200 is by all practical measurements a supersized version of GM204.
Moving down the NVIDIA lineup, we see performance decrease as we work towards the GTX 680 and GTX 750 Ti. The latter is a newer product, based on the GM107 GPU, but ultimately it is a smaller and lower performing GPU than the GTX 680. Regardless, we are hitting the lower command processor throughput limits of these cards, and seeing the maximum DX12 throughput decrease accordingly. This means that the relative gains are smaller – DX11 performance is virtually the same as GTX 980 since the CPU is the limit there – but even GTX 750 Ti sees a 3.8x increase in throughput over DX11ST.
Finally, it’s here where we’re seeing a distinct case of the DX11 test producing variable results. For the NVIDIA cards we have seen our results fluctuate between 1.4M and 1.9M. Of all of our runs 1.9M is more common – not to mention it’s close to the score we get on NVIDIA’s public WDDM 1.3 drivers – so it’s what we’re publishing here. However for whatever reason, 1.4M will become more common with fewer cores even though the bottleneck was (and remains) single-core performance.
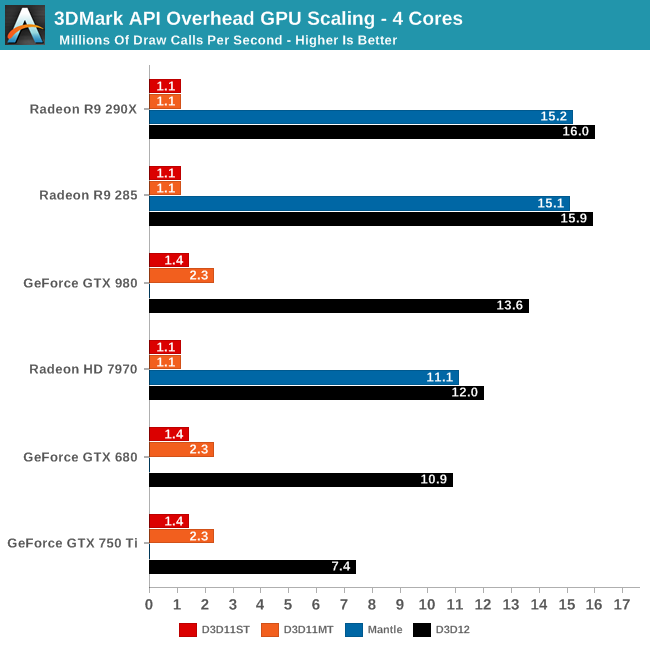
As for performance scaling with 4 cores, it’s very similar to what we saw with 6 cores. As we noted in our CPU-centric look at our data, only the fastest cards benefit from 6 cores, so the performance we see with 4 cores is quite similar to what we saw before. AMD of course still sees the greatest gains, while overall the gap between AMD and NVIDIA is compressed some.
Interestingly Mantle’s performance advantage melts away here. DirectX 12 is now the fastest API for all AMD cards, indicating that DX12 scales out better to 4 cores than Mantle, but perhaps not as well to 6 cores.
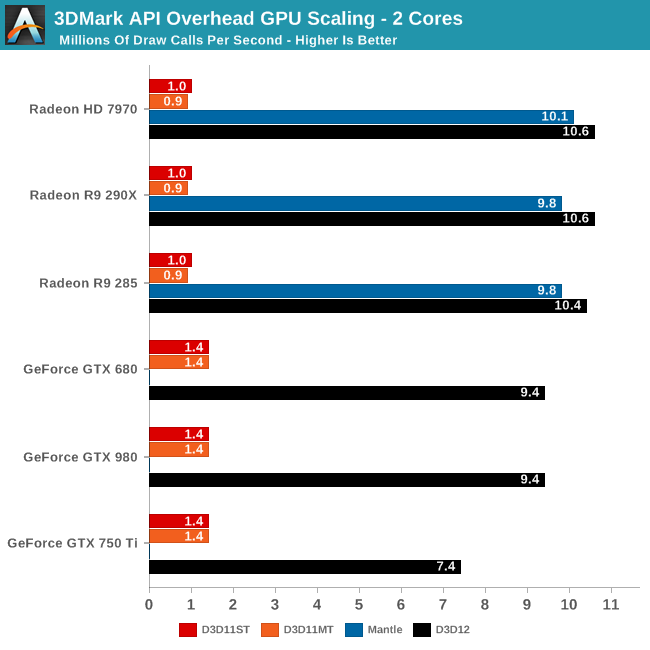
Finally with 2 cores many of our configurations are CPU limited. The baseline changes a bit – DX11MT ceases to be effective since 1 core must be reserved for the display driver – and the fastest cards have lost quite a bit of performance here. None the less, the AMD cards can still hit 10M+ draw calls per second with just 2 cores, and the GTX 980/680 are close behind at 9.4M draw calls per second. Which is again a minimum 6.7x increase in draw call throughput versus DirectX 11, showing that even on relatively low performance CPUs the draw call gains from DirectX 12 are substantial.
Overall then, with 6 CPU cores in play AMD appears to have an edge in command processor performance, allowing them to sustain a higher draw call throughput than NVIDIA. That said, as we know the real world performance of the GTX 980 easily surpasses the R9 290X, which is why it’s important to remember that this is a synthetic benchmark. Meanwhile at 2 cores where we become distinctly CPU limited, AMD appears to still have an edge in DirectX 12 throughput, an interesting role reversal from their poorer DirectX 11 performance.








113 Comments
View All Comments
nrexz - Friday, March 27, 2015 - link
How much can they do with it really? Games will still be developed to the limits of the consoles not pc's.Also, I'm not sure if I should be impressed or sad that Forbes published this yesterday.
nathanddrews - Friday, March 27, 2015 - link
That might be an oversimplification. If anything, this could result in console ports NOT running like crap. What's the biggest complaint about ports? That the game is tailored "to the metal" of a console, making port to such a variety of PCs more difficult to develop.Think about it - when designing games around the Xbone/PS4, they tailor the games for eight cores and are not restricted by DX11 call limits or RAM - only the GPU power, but then when they port to PC, those optimized engines have to sludge through the DX11 pipeline before tapping into the GPU. With that restrictive pipeline removed (and GPUs shipping more RAM), those game engines can operate more efficiently in multicore PCs.
It's not a cure-all (low-res textures), but I think this could be the start of a revolution in which ports stop sucking.
Flunk - Friday, March 27, 2015 - link
The current consoles both have 8GB of RAM, all of which is GPU-addressable, so texture resolution shouldn't really be a problem.Also, the Xbox One is built around DX11 so this will be helpful for that. Frankly DirectX 12 will be helpful because it will make Xbox One -> PC ports easier so hopefully we'll either see more of them or see better ports.
It's not really a big worry anyway, this is quite likely the last console generation anyway.
happycamperjack - Friday, March 27, 2015 - link
Only about 5 to 5.5GB of RAM is consoles are usable. The rest are reserved by OS.Laststop311 - Saturday, March 28, 2015 - link
I think its actually 3-3.5GB reserved for the system so 4.5-5GB available to the GPUnathanddrews - Friday, March 27, 2015 - link
My comment about low-res textures has to do with the fact that Xbone/PS4 don't always use the same high-res texture packs available to PC users and that DX12 won't help with that in either scenario.The API Xbone runs is far removed from its PC counterpart. It's a heavily modified "Direct3D 11.X" that is built exclusively for Xbone, which removes the overhead that Windows DX11 has to deal with. In PC terms, it's effectively a superset of DX11.2 features running with DX12 efficiency.
"Microsoft, though, claims that the Direct3D 11.X for Xbox One features significant enhancements in the area of runtime overhead, which results in a very streamlined, 'close to metal' level of runtime performance."
DERSS - Saturday, March 28, 2015 - link
"Close to metal"?Maybe they meant "Close to silicon"? Or they meant to compare with Apple's Metal for iOS?
deruberhanyok - Saturday, March 28, 2015 - link
It's just an expression.Way back before Apple had "Metal", ATI had "Close to Metal" (http://en.wikipedia.org/wiki/Close_to_Metal), and even earlier than that, S3 had their own API, also called Metal.
It just means being able to code with as little overhead as possible. The idea is to have very little between the application and the hardware running it, to get as close to the maximum possible performance as you can.
Navvie - Tuesday, March 31, 2015 - link
The term goes back to the C64 and Amiga demo scenes. Programming in assembler without an API and literally "hitting the metal".Silicon is a metalloid element, so "hitting the metal" doesn't really need correcting.
Kidster3001 - Wednesday, April 1, 2015 - link
The 'metal' comes from an old saying: 'bare metal'. It's still used in the compute industry when referring to special testing that bypasses OS and driver layers, talking to the silicon directly.