GeForce GTX 970: Correcting The Specs & Exploring Memory Allocation
by Ryan Smith on January 26, 2015 1:00 PM ESTSegmented Memory Allocation in Software
So far we’ve talked about the hardware, and having finally explained the hardware basis of segmented memory we can begin to understand the role software plays, and how software allocates memory among the two segments.
From a low-level perspective, video memory management under Windows is the domain of the combination of the operating system and the video drivers. Strictly speaking Windows controls video memory management – this being one of the big changes of Windows Vista and the Windows Display Driver Model – while the video drivers get a significant amount of input in hinting at how things should be laid out.
Meanwhile from an application’s perspective all video memory and its address space is virtual. This means that applications are writing to their own private space, blissfully unaware of what else is in video memory and where it may be, or for that matter where in memory (or even which memory) they are writing. As a result of this memory virtualization it falls to the OS and video drivers to decide where in physical VRAM to allocate memory requests, and for the GTX 970 in particular, whether to put a request in the 3.5GB segment, the 512MB segment, or in the worst case scenario system memory over PCIe.
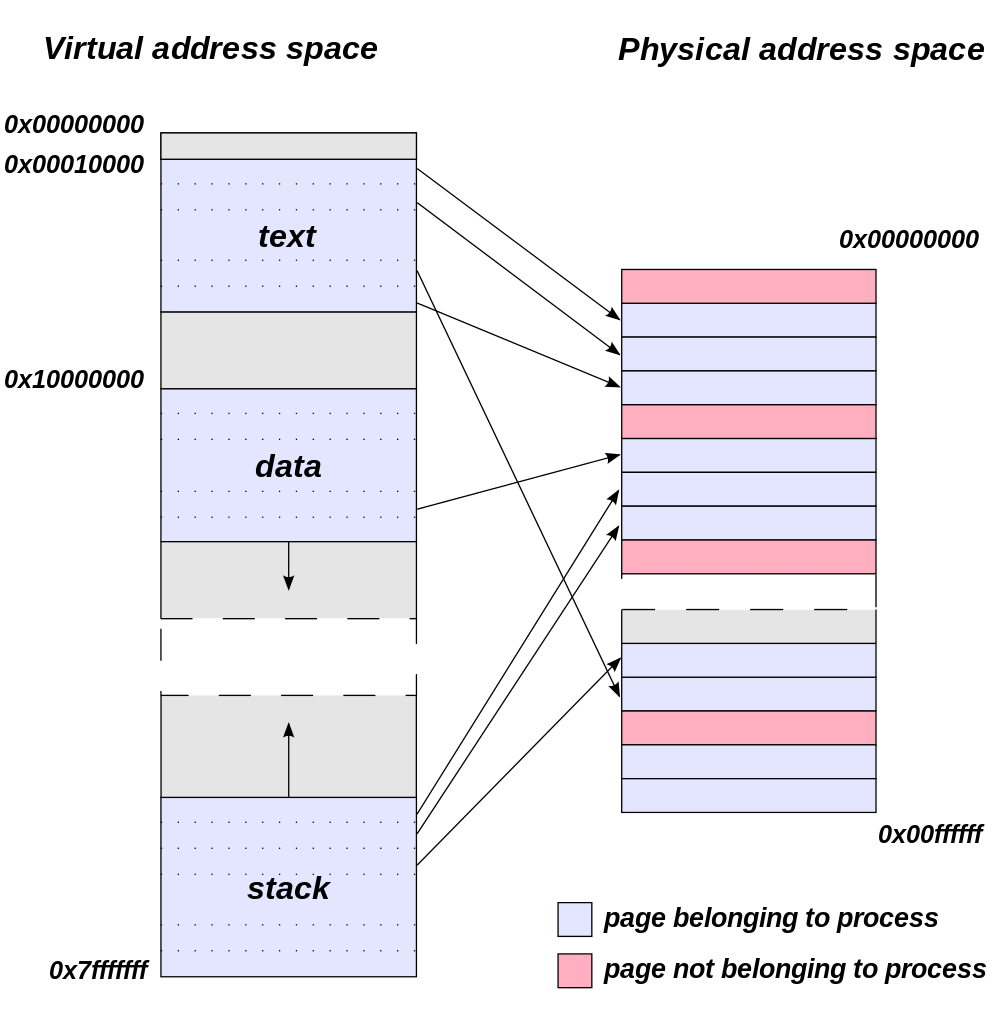
Virtual Address Space (Image Courtesy Dysprosia)
Without going quite so far to rehash the entire theory of memory management and caching, the goal of memory management in the case of the GTX 970 is to allocate resources over the entire 4GB of VRAM such that high-priority items end up in the fast segment and low-priority items end up in the slow segment. To do this NVIDIA focuses up to the first 3.5GB of memory allocations on the faster 3.5GB segment, and then finally for memory allocations beyond 3.5GB they turn to the 512MB segment, as there’s no benefit to using the slower segment so long as there’s available space in the faster segment.
The complex part of this process occurs once both memory segments are in use, at which point NVIDIA’s heuristics come into play to try to best determine which resources to allocate to which segments. How NVIDIA does this is very much a “secret sauce” scenario for the company, but from a high level identifying the type of resource and when it was last used are good ways to figure out where to send a resource. Frame buffers, render targets, UAVs, and other intermediate buffers for example are the last thing you want to send to the slow segment; meanwhile textures, resources not in active use (e.g. cached), and resources belonging to inactive applications would be great candidates to send off to the slower segment. The way NVIDIA describes the process we suspect there are even per-application optimizations in use, though NVIDIA can clearly handle generic cases as well.
From an API perspective this is applicable towards both graphics and compute, though it’s a safe bet that graphics is the more easily and accurately handled of the two thanks to the rigid nature of graphics rendering. Direct3D, OpenGL, CUDA, and OpenCL all see and have access to the full 4GB of memory available on the GTX 970, and from the perspective of the applications using these APIs the 4GB of memory is identical, the segments being abstracted. This is also why applications attempting to benchmark the memory in a piecemeal fashion will not find slow memory areas until the end of their run, as their earlier allocations will be in the fast segment and only finally spill over to the slow segment once the fast segment is full.
| GeForce GTX 970 Addressable VRAM | |||
| API | Memory | ||
| Direct3D | 4GB | ||
| OpenGL | 4GB | ||
| CUDA | 4GB | ||
| OpenCL | 4GB | ||
The one remaining unknown element here (and something NVIDIA is still investigating) is why some users have been seeing total VRAM allocation top out at 3.5GB on a GTX 970, but go to 4GB on a GTX 980. Again from a high-level perspective all of this segmentation is abstracted, so games should not be aware of what’s going on under the hood.
Overall then the role of software in memory allocation is relatively straightforward since it’s layered on top of the segments. Applications have access to the full 4GB, and due to the fact that application memory space is virtualized the existence and usage of the memory segments is abstracted from the application, with the physical memory allocation handled by the OS and driver. Only after 3.5GB is requested – enough to fill the entire 3.5GB segment – does the 512MB segment get used, at which point NVIDIA attempts to place the least sensitive/important data in the slower segment.








{kind=link}
398 Comments
View All Comments
Jon Tseng - Monday, January 26, 2015 - link
Storm in a teacup.The benchmarks everyone ran at launch which showed its a screaming card at a great price still stand.
Very happy with my 970. It's a screaming card which I got for a great place. Move along now.
Inteli - Monday, January 26, 2015 - link
Agreed. Especially at 1080p, I haven't noticed any noticeable drops in frame rate attributed to a lack of VRAM. I think the people hurting the most will be those who bought 2 for SLI at 1440p or higher. I do feel bad for them, but not bad enough that I'm going to stop buying Nvidia.nutmeg2000 - Monday, January 26, 2015 - link
Looks as if nvidia had some shills jump into the comments section right quick.It's great that sites are starting to investigate this major issue now and it will reveal more on the deception nvidia has engaged into with their gtx 970 marketing. We will begin to learn more soon and see what sort of legal trouble nvidia has created with their illegal marketing.
Major issue for nvidia and not surprising to see nvidia shills in commet areas like this trying to downplay what is going to be a huge issue for them going forward.
Letitbewilder - Monday, January 26, 2015 - link
Some paranoia there but yes nvidia is in hot water and will be trying to lessen the impact this has on their business. Major trouble here and surely a lawsuit is coming for them as in the past with the bunpgate situation. I welcome the test work sites are in the midst of now and hope nvidia makes.good on this significant issue with the gtx 970.Taneli - Monday, January 26, 2015 - link
A clear case for a class action suit hereThepotisleaking - Monday, January 26, 2015 - link
The coming weeks are sure to be.....
Interesting!
FlushedBubblyJock - Friday, January 30, 2015 - link
I recall not that long ago here, AMD was embarrassed and in a similar situation, I believe it was the Bulldozer core, that was said to have like 2 billion transistors for 6 months or more after release, then right here Anand posted as part of another article, the updated chart with the only 1.5B transistors, and said AMD gave him the new much lower number with no explanation as to why, and then it was immediately dropped, as if no harm no foul.LOL
It was amazing at the time, AMD got a big fat free pass on a giant spec lie.
Overmind - Wednesday, February 4, 2015 - link
They didn't disable millions of transistors. It was just a wrong number written somewhere.FlushedBubblyJock - Friday, January 30, 2015 - link
Well, it was 2billion transistors for AMD's bullldozer that dropped not to just 1.5, but lower, to 1.2 -http://www.anandtech.com/show/5176/amd-revises-bul...
" The actual transistor count for Bulldozer is apparently 1.2 billion transistors. I don't have an explanation as to why the original number was wrong.."
So when AMD does it, it's ok, no explanation necessary... and...the next line is ridiculous praise..
"Despite the downward revision in Bulldozer's transistor count by 800M, AMD's first high-end 32nm processor still boasts a higher transistor density than any of its 45nm predecessors "
LOL - it's okay, AMD does it and gets a total pass, so don't worry about it.
"
mrloadingscreen - Friday, January 30, 2015 - link
It's okay because no one who actually cares about technology much less transistor count bought a bulldozer.