AMD Radeon R9 285 Review: Feat. Sapphire R9 285 Dual-X OC
by Ryan Smith on September 10, 2014 2:00 PM ESTCompute
Jumping into compute, our expectations regarding compute performance are going to be a mixed bag. On the one hand as part of the newer GCN 1.2 architecture AMD has been doing some tweaking under the hood, but on the other hand the most important aspects of the architecture – the memory model and thread execution – are not fundamentally different from the GCN 1.0 R9 280. As a result we’re not necessarily expecting to find any performance leaps here but there is the possibility that we will find some along the way.
As always we’ll start with LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
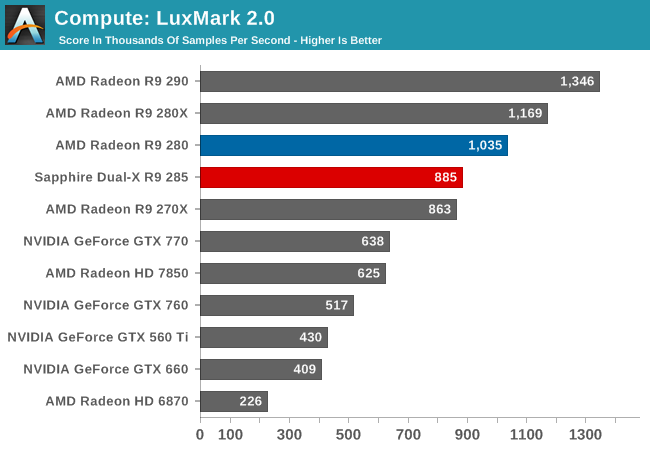
Right off the bat we find an unexpected regression in performance with LuxMark. All things considered we would expect the R9 285 to score similarly to the R9 280 given their nearly identical theoretical FP32 throughput, similar to what we’ve seen in our gaming benchmarks. Instead we have the R9 285 trailing its predecessor by 15%, and coming very close to tying the otherwise much slower R9 270X. Given that this is a new architecture there are a few possibilities here including a lack of OpenCL driver optimizations on AMD’s part, though we can’t entirely rule out bandwidth either since ray tracing can burn up bandwidth at times. Tonga is after all first and foremost a graphics product, and AMD’s memory bandwidth saving compression technology is similarly designed for graphics and not compute, meaning the R9 285 doesn’t have much to make up for the loss of bandwidth in compute tasks versus the R9 280.
In any case, even with R9 285 lagging the R9 280, it’s otherwise a strong showing for AMD. AMD cards overall perform very well on this benchmark compared to NVIDIA’s offerings, so the R9 285 has no trouble shooting well past the GTX 760.
Our 2nd compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
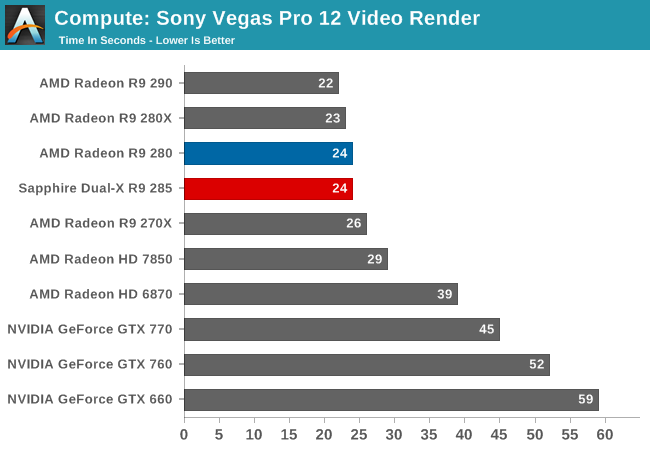
Unlike LuxMark, we aren’t seeing a performance gain nor a regression here. The R9 285 is every bit as fast as the R9 280. Meanwhile as has consistently been the case in this benchmark, all of AMD’s cards are well ahead of our NVIDIA cards.
Our 3rd benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; for our standard benchmark suite we focus on the most practical of them, the computer vision test and the fluid simulation test. The former is a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.


Depending on which subtest we’re looking at, the R9 285 either outperforms or trails the R9 280. The fluid simulation subtest finds the R9 285 performing just shy of the more powerful R9 280X, while the R9 285 comes up short of the R9 280 in computer vision. Computer vision is the more bandwidth sensitive benchmark of the two, so it follows that it’s the benchmark more likely to be influenced by the loss of raw memory bandwidth. Otherwise the R9 285’s strong showing in the fluid simulation is unexpected, and given what we know we’re at a bit of a loss to explain it.
Looking at the broader picture, this is yet another test where AMD’s cards do well against NVIDIA’s non-compute cards. Overall the R9 285 is 2-3x faster than the GTX 760 here.
Moving on, our fourth compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, utilizing the OpenCL path for FAHCore 17.


When it comes to single precision the R9 285 edges out the R9 280, though not significantly so. R9 285 still seemingly benefits from some of the GCN 1.2 architectural optimizations, but not to the same extent we’ve seen in other benchmarks.
Overall AMD’s GCN cards are a strong performer in this benchmark and the R9 285 is no exception. GTX 760 trails R9 285 when it comes to implicit single precision, and is blown away in the explicit single precision benchmark.

Meanwhile for double precision the R9 285 falls well behind the R9 280. Since Tonga is not designed to pull double-duty as a graphics and high performance compute GPU like Tahiti was, Tonga is configured for 1/16 rate double precision performance, 1/4 the rate of the more powerful Tahiti. As a result it can never keep up with the R9 280 in a double precision workload. Consequently AMD and the R9 285 still have a lead in F@H with double precision, but not to the degree we’ve seen elsewhere. The R9 285 is only about 30% faster than the GTX 760 here.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
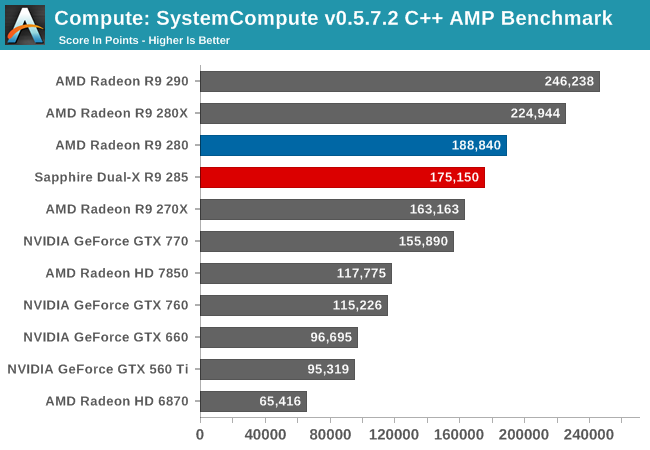
SystemCompute exposes another case where the R9 285 comes up short compared to the R9 280, though only slightly. AMD’s latest card can deliver 93% of the performance of an R9 280, and most likely it’s suffering just a bit from the reduction in memory bandwidth. Otherwise it’s still more than 50% ahead of the GTX 760 and still comfortably ahead of the more powerful GTX 770.








86 Comments
View All Comments
CrazyElf - Wednesday, September 10, 2014 - link
All in all, this doesn't really change the market all that much.I still very firmly feel that the R9 290 right now (Q3 2014) remains the best price:performance of the mid to high end cards. That and the 4GB VRAM which may make it more future proof.
What really is interesting at this point is what AMD has to respond on Nvidia's Maxwell.
MrSpadge - Wednesday, September 10, 2014 - link
I Agree - Tonga is not bad, but on the other hand it does not change anything substantially compared to Tahiti. This would have been a nice result 1 - 1.5 years after the introduction of Tahiti. But that's almost been 3 years ago! The last time a GPU company showed no real progress after 3 years they went out of business shortly afterwards...And seing how AMD brags to beat GTX760 almost makes cry. That's the double cut-down version of a 2.5 years old chip which is significantly smaller than Tonga! This is only a comparison because nVidia kept this card at a far too high price because there was no competitive pressure from AMD.
If this is all they have their next generation will get stomped by Maxwell.
iLovefloss - Wednesday, September 10, 2014 - link
So all you got from this review is that Tonga is a cut down version of Tahiti? After reading this review, this is the impression you were left with?MrSpadge - Thursday, September 11, 2014 - link
Nope. But in the end the result performs just the same at even almost the same power consumption. Sure, there are some new features.. but so far and I expect for the foreseeable future they don't matter.Demiurge - Wednesday, September 10, 2014 - link
This is the first mid-range card to have all the value add features of the high-end cards. I wish AMD would leverage TrueAudio better, but the other features and the nice TDP drop.The color compression enhancement is a very interesting feature. I think that in itself deserves a little applause because of its significance in the design and comparing to the 280's. I think this is more significant, not as a performance feature, but similar to what Maxwell represented for NV in terms of efficiency. Both are respectable design improvements, in different areas. It's a shame they don't cross-license... seems like such as waste.
MrSpadge - Thursday, September 11, 2014 - link
Well, the TDP-drop is real, but mostly saves virtual power. By this I mean that 280 / 7950 never come close to using 250 W, and hence the savings from Tonga are far less than the TDP difference makes it seem. The average between different articles seems to be ~20 W saving at the wall and establishes about a power-efficiency parity with cards like GTX670.The color compression could be Tongas best feature. But I still wonder: if Pitcairn on 270X comes so close to 285 and 280 performance with 256 bit memory bus and without color compression.. how much does it really matter (for 285)? To me it seems that Tahiti most often didn't need that large bus rather than color compression working wonders for Tonga. Besides, GTX770 and GTX680 also hold up fine at that performance level with a 256 bit bus.
Demiurge - Thursday, September 11, 2014 - link
The TDP drop is something I did not think about being a paper launch value. You make a good point about the color compression too. It will be interesting how both fair. That may be an interesting topic to follow up during the driver refresh.As an owner of GTX 260 with a 448-bit bus, I can tell you that with anti-aliasing, it matters quite a bit as that becomes the limiter. The shader count is definitely not the limiter usually in the low-end and mid-range displays that these cards will typically be paired with. My GTX 260 and 1280x1024 monitor kind of illustrate that with 216 Shaders/896MB. :-)
It isn't pretty, but I don't see anything that forces me to upgrade yet. Think I've got two more generations or so to wait on before performance is significant enough, or a groundbreaking feature would do it. I'm actually considering upgrading out of boredom and interest in gimmicky features more than anything else at this point.
TiGr1982 - Thursday, September 11, 2014 - link
GTX 260 is like 6 years old now. It's lacking DX11, having less than 1 GB of (relatively slow) GDDR3 VRAM, and overall should be 3-4 times slower than R9 285 or R9 290, I guess.I really didn't think anybody still uses these old gen cards (e.g. I have HD 7950 Boost Dual-X which is essentially identical to R9 280).
P39Airacobra - Friday, January 9, 2015 - link
Because they would loose money! LOL. And they are both about the same anyway, Except AMD goes for brute force to get performance,(like using aV8) And Nvidia uses efficency with power. (Like a turbo charged 4cyl or 6cyl)bwat47 - Thursday, September 11, 2014 - link
"And seing how AMD brags to beat GTX760 almost makes cry. That's the double cut-down version of a 2.5 years old chip which is significantly smaller than Tonga! This is only a comparison because nVidia kept this card at a far too high price because there was no competitive pressure from AMD."You are being pretty silly here. Both AMD and Nvidia were rebranding a lot of cards these last few gens. You can'y go after AMD for rebranding a 2-3 year old chip, and then say its fine if nvidia does it and blame AMD's 'lack of competitive pressure'. If lack of competitive pressure was the reason for rebranding, then there was lack of competitive pressure on both sides.
And I highly doubt the 285 is 'all amd has'. this was just a small update to their product line, to bring some missing features (freesync, true audio etc...), and reduced power consumption to the 28x series. I'm sure there is a 3xx series coming down the road (or whatever they will call it). Both AMD and nvidia have been working been squeezing all they can out of older architecture for the past few years, you can't really put the blame on one of the other without being hypocritical.