LINPACK: Nehalem vs Shanghai part 2
by Johan De Gelas on December 1, 2008 12:00 AM EST- Posted in
- IT Computing general
The last post generated some very interesting comments and questions, which I wanted to address. Unfortunately, some people misinterpreted the post as a "the best scores Nehalem and Shanghai can get in Linpack" review.
So let me make this very clear: this and the previous blogpost are not meant to be a "buyer's guide". The Nehalem desktop system and AMD "Shanghai" server are completely different machines, targeted at totally different markets. Normally, we should wait for the Xeon 5500 to run these kind of benchmarks, but consider this a preview out of curiosity.
Secondly, we were not trying to get the highest possible LINPACK scores on both architectures. We wanted to use one binary which has good optimizations for both AMD's and Intel CPU's. Fully optimized binaries won't even run on the other CPU.
Our only goal is to get an idea how the Nehalem and Shanghai architectures compare when running a "LINPACK" alike binary which is optimized to run on all machines.
Thirdly, this is not our review of course. This is a blogpost which talks about some of the tests we are doing for the review.
MKL on AMD?
Using the Intel Math Kernel Libraries on an AMD CPU is of course a good way to start some heavy debates. As I pointed out in the last blogpost however, in some cases, the slightly older MKL versions still do a very good job on AMD CPUs when you benchmark with low matrix sizes.
You don't have to take my word for it of course.
Compare the Intel Linpack 9.0 (available mid 2007) with the binary that AMD produced at the end of 2007. AMD made a K10 only version using the ACML version 4.0.0, and compiling Linpack with the PGI 7.0.7 compiler (with following flags: pgcc
-O3 -fast -tp=barcelona-64).
All the benchmarks below are done on one CPU with 4 GB (AMD, Intel Xeon) or 3 GB (Intel Core i7). Speedstep, Powernow! and Turbo mode were disabled.
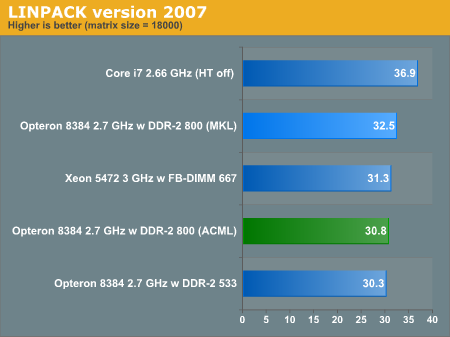
As predicted, the ACML binary which was compiled with 2007 compiler is slower than the MKL "2007" version also compiled in 2007. The MKL version runs on any CPU that has support for (S)SSE-3, so it continues to be a very interesting one for us to test. As you can clearly see from the Xeon 5472 (3 GHz) score, it is not fully optimized for the latest 45 nm Intel CPUs with SSE-4. It is a good "not too optimized" version which can be used on both Intel and AMD CPUs. You can clearly see this as the 3 GHz Xeon 5472 is behind the AMD Opteron 8384. If this Intel Binary was giving the AMD CPUs a badly optimized code path, this would not be possible.
As we move forward to 2008, we have to create a new binary as both AMD and Intel's fully optimized Linpack versions will not run on the competitor's CPU. Intel released the Linpack benchmark version 10.1, which is not fully optimized for the "Nehalem" architecture, but for 45 nm "Harpertown" family.
AMD has created a new Linpack binary using ACML 4.2 and the PGI 7.2-4 compiler. Below you see how the two CPUs compare.
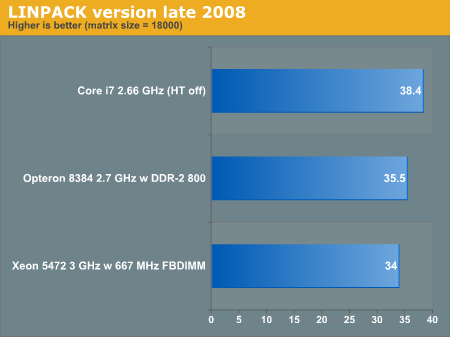
Bottom line is that these LINPACK benchmarks are moving targets like the SPEC CPU benchmarks, as the compilers and libraries used are just as important as the CPUs.When the Xeon 5500 will materialize, LINPACK performance will probably be higher as the binary is built for the "Penryn/Harpertown" family.
While it is useful for the HPC people to see which CPU + compiler can offer the best performance, it is also interesting to understand what kind of performance you get when you compile binaries that have to run on all current CPUs. It is pretty hard to compare CPU architectures if you are using totally different binaries.
In the next post we'll delve a bit deeper on what is happening with Hyperthreading, Linpack and the new architectures.








31 Comments
View All Comments
piesquared - Saturday, December 13, 2008 - link
Johan, an honest question seeking an honest answer. I know you've said in the past that virualization articles are complicated and time consuming. It's been almost a month now. As you know, virtualization is THE feature the industry is begging for going forward, and is one of, if not the strongest feature of Shanghai. I'm just wondering why you didn't make this a top priority in your testing, and if we shouldn't expect to see any articles or reviews in this regard, until Intel has something that competes. It is really starting to look that way, but I hope i'm wrong as i've had alot of respect for you in the past. I doubt Core i7 will be all that competitive for VM, but even so, i'll be extremely dissapointed if it miraculously makes an appearance. Especially given the time to market between the two server parts.Anyway, i'll continue to wait.................................
twilkens - Monday, December 8, 2008 - link
Johan,Long time since we talked. I spoke with Joshua in TX and he informed me that he sent you some data on how to run and a binary with the latest ACML. You used that in your update, right? ACML 4.2 is quite a bit faster than 4.1 and uses a new algorithm which will be pushed out to all of ACML in the next year.
Another question I had, did you run HPL? There's a hpl.dat file there which needs to be tuned. Like you said in the review.. the chip's important, but so is the software (aka library but also that hpl.dat file). In the hpl.dat file there's an NB parameter. For ACML 4.2 that parameter is best set to 168. For MKL, ATLAS and GOTO they have their favorites so fyi if you switch libraries you also need to tune that parameter. Don't know if you knew about this but .. there it is.
Stay in touch.. I'm sure you have the email address.. and best regards Johan.
Tim Wilkens
IdaGno - Tuesday, December 9, 2008 - link
sheeshe! picky, picky, picky!bottom line: OPTIMIZED CODE IS CRITICAL
this should surprize no one
lighten up, people
befair - Monday, December 8, 2008 - link
And I doubt Johan can even do a decent run of HPL without saying "Intel wins" before he even starts the runoctop - Wednesday, December 3, 2008 - link
The raw performance of a processor does not just rely on Architecture. The manufacturing process technology play an important part. Intel win in this area. AMD as well as readers here knew that too. In my view, in order for AMD to survive, he has to beat Intel in a more creative way, which is manifested in their CPU design. Look, Nahelem takes a lot of similar concepts as AMD Agena. I think Intel is copying the ideas from AMD K9 processor in term of bus technology, the importance of embedding mem. controller into the processor etc.I never think that AMD loss, both in design & sometimes performance. Pls note that, software has also making the equation more complex. Some benchmark only calc raw speeds which doesn't really implement in real life, AND the API used for benchmark software also depends on OS. Is OS not biased? If I'm Microsoft, how could I create a kernel that take the best from both world with a fixed resources, AT the time my R&D team is working on the Kernel? I'd tune my compiler base for the most popular CPU with their latest optimised insttruction set AT that time. All in all, it'd be base your benachmark on intended application rather than raw performance or architecture. You'll never find a fair answer.
So, there's really no point to argue on the results. But argument on the details will benefit all of us.
By the way, how much you used to pay AMD CPU for similar/equivalent preformance compare to Intel. And how would Intel CPU cost us without AMD pressure. I think cost should be also factored in the benchmark for general highlevel comparison. Intel selling Penryn in affordable manner is b'cse they have achieve economic of scale in manufacturing and also competition from AMD. All the bucks you pay are mostly for manufacturing technology, the silicon doesn't cost much.
That's just my 2 cents. Hope you guys don dispute each other anymore.
jmurbank - Monday, December 8, 2008 - link
I agree AMD still have not lost the processor game. Gamers think AMD did lose because benchmarks shows Phenom and Athlon64 does not equal or over come the performance of Core 2 Duo. Gamers do not understand is that AMD is very strong in the server market. From what I have seen with benchmarks in the past comparing Core 2 Duo and AMD processors, they have not done a a very heavy load test. I am seeing a little glimpse with heavy loads that AMD Shanghai has a higher performance per watt ratio compared to Intel Harpertown processors.I disagree that a smaller fabrication process improves performance. Sure it can provide higher clocks and more area to include more transistors. There are other ways to make a processor efficient. Turning a RISC processor to act like a VLIW processor which Intel have done with their Core 2 Duo processor. A silicon disk does cost a lot of money. Making pure silicon is not easy and the manufacturing process is very expensive.
From the results that I am seeing with LINPACK for both AMD Shanghai processor and Intel Nehalem processor, they are both equal in performance. I can not tell if the Intel processor is using non-ECC memory and if the AMD processor is using ECC memory. If one is using non-ECC and the other is using ECC memory, no wonder there is a 5 percent performance boost. Also both setups should hold about 6 GiB (6 of 1 GiB memory modules) of RAM to do a good comparison. Intel fans celebrating over a 5 percent of performance gain should look at it closer.
AMD has a better cost advantage. Their on-board motherboard chipsets are better and are cheaper compared to Intel motherboard chipsets. Also AMD systems have some flexibility to use 3rd-party motherboard chipsets with out having any problems. Using 3rd-party motherboard chipsets for Intel systems does have problems and history have stated this.
I call myself an AMD fan, but again this LINPACK review just shows that AMD Shanghai has equal performance to Intel Nehalem because the controls are vague and there are too many variables.
bonesdmz - Wednesday, December 3, 2008 - link
Does Nehalem still performs worse with SMT enabled when using newer Linpack binaries?Shmak - Wednesday, December 3, 2008 - link
Those looking for a real review of the Shanghai can find it tucked away in the IT section here: http://www.anandtech.com/showdoc.aspx?i=3456&p...">http://www.anandtech.com/showdoc.aspx?i=3456&p...shin0bi272 - Tuesday, December 2, 2008 - link
Just to shut up the AMD people. I havent bought an AMD since the k6III series and dont plan to go back now. But still Id like to see more benchmarks with games and such in them so that we can see if/how much the intel beats the amd (again).Spoelie - Tuesday, December 2, 2008 - link
reading through those responses, don't you miss the level of conversation held at aceshardware articles?ah well different readership ;)