AMD Threadripper Pro Review: An Upgrade Over Regular Threadripper?
by Dr. Ian Cutress on July 14, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- ThreadRipper
- Threadripper Pro
- 3995WX
CPU Tests: Synthetic
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 results in published reviews.


AMD has had a sha256 accelerator in its processors for many years, whereas Intel only enabled SHA acceleration in Rocket Lake. That's why we see RKL matching TR in 1T mode, but when the cores get fired up, TR and TR Pro streak ahead with the available performance and memory bandwidth. This is all about threads here, and 128 threads really matters.
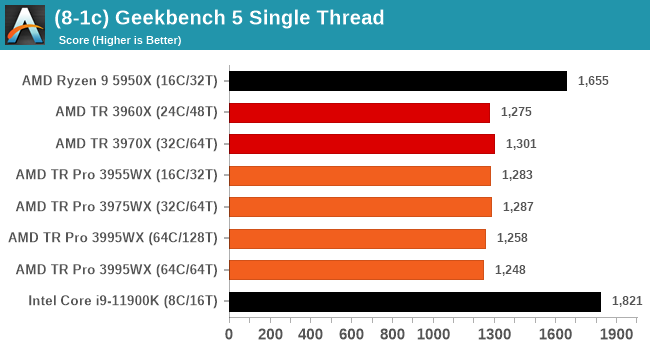
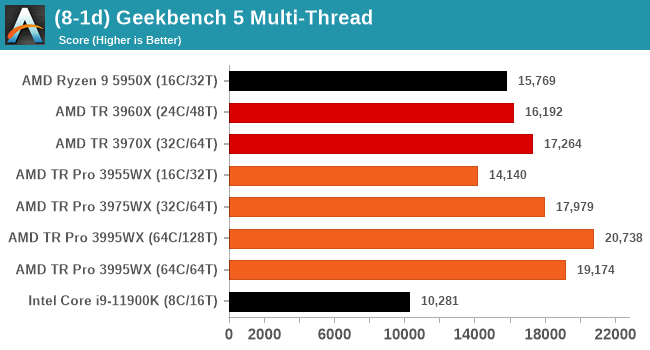
GeekBench 5: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic.
DRAM Bandwidth
As we're moving from 2 channel memory on Ryzen to 4 channel memory on Threadripper then 8 channel memory on Threadripper Pro, these all have associated theoretical bandwidth maximums but there is a case for testing to see if those maximums can be reached. In this test, we do a simple memory write for peak bandwidth.
For 2-channel DDR4-3200, the theoretical maximum is 51.2 GB/s.
For 4-channel DDR4-3200, the theoretical maximum is 102.4 GB/s.
For 8-channel DDR4-3200, the theoretical maximum is 204.8 GB/s.
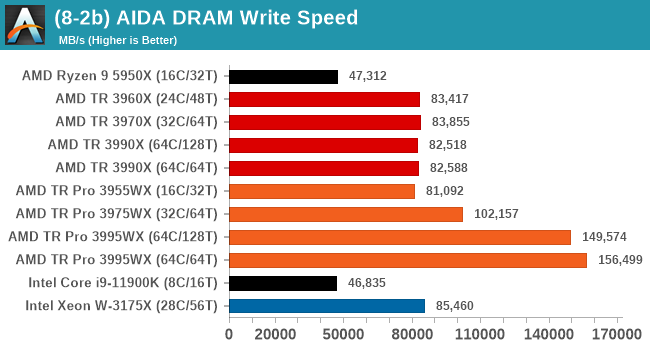
Here we see all the 4-channel Threadripper processors getting around 83 GB/s, but the Threadripper Pro can only achieve closer to its maximums when there are more cores present. Along with the memory controller bandwidth, AMD has to manage internal infinity fabric bandwidth and power to get the most out of the system. The fact that the 64C/64T achieves better than the 64C/128T might suggest that in 128T there is some congestion.








98 Comments
View All Comments
Mikewind Dale - Wednesday, July 14, 2021 - link
I have a ThreadRipper Pro 3955WX, and I discovered something interesting about the memory bandwidth.Originally, I bought 4x64 GB ECC RDIMM because I thought 256 GB might be enough, and I wanted to leave some empty RAM slots to populate with 128 GB RDIMMs if those ever became cost-effective. (Right now, 128 GB RDIMMs are about triple the price of 64 GB.)
CPU-Z and AIDA64 reported "quad" channel memory, and AIDA64's memory benchmarks showed reasonable memory performance.
But I discovered that 256 GB wasn't enough for my application, so I bought 2 more 64 GB RDIMMs.
At this point, I had 6 DIMMs populated. CPU-Z and AIDA64 both reported "hexa" channel memory, but AIDA64's memory benchmarks showed that my memory performance was about 2/3 that of a Ryzen.
So I bought 2 more RDIMMs again, for a total of 8. Now, my memory benchmark in AIDA64 is much closer to expected.
So the moral of the story is: you can populate 4 DIMMs, or you can populate 8, but don't dare populate 6. Populating precisely 6 DIMMs will absolutely cripple your memory performance, whereas 4 DIMMs still have acceptable performance.
kobblestown - Wednesday, July 14, 2021 - link
The 3955 probably has only 2 CCDs and is therefore limited to 4 DDR channels throughput. It seems that each IF link has the throughput of 2 DDR channels and this makes sense.You should keep in mind that the IO die has in effect 4 dual channel controllers and you may have populated them suboptimally. If you have two dual channel controllers fully populated and two half populated (instead of a third fully populated and the fourth one staying empty) you'll have skewed results. Also, there was some noise about Milan working better with 6 channel configurations so it may be something specific to Rome chips.
Rudde - Wednesday, July 14, 2021 - link
Server providers had requested for 6 channel memory support for server processors and that was implemented in Milan.McFig - Wednesday, July 14, 2021 - link
What kobblestown is suggesting is that maybe Mikewind Dale could have gotten the 6 RDIMMs working by moving one of them so that each pair is fully populated.Mikewind Dale - Wednesday, July 14, 2021 - link
McFig, there are only 8 slots, so I'm not sure how I could have moved the 6 DIMMs among the 8 slots to ensure that each pair is populated.1_rick - Wednesday, July 14, 2021 - link
He probably means "each of 3 pairs fully populated".DougMcC - Wednesday, July 14, 2021 - link
I think the question is whether 3/3 is better than 4/2kobblestown - Friday, July 16, 2021 - link
Heya! Sorry for the nebulous formulation. In terms of the number of DIMMS per memory controller, I suggest having 2+2+2+0 instead of 2+1+2+1. One needs to figure out what this means for any particular MB. But as DougMcC suggests, that would probably mean having 4 DIMMs on one side of the CPU and 2 on the other, rather than having 3 DIMMs on each side. The latter is bound to be suboptimal. Whether the former offers an improvement is something that I would be very interested to know but could be that Rome has some shortcoming in this area which is addressed in Milan.Again, dual CCD configurations are limited to 4 channel bandwidth but it's still worth it to have all channels populated so you don't get bitten by badly handled assymetry and the IO does not fight (too much) with the cores for the bandwidth.
kobblestown - Friday, July 16, 2021 - link
BTW, one should also check the memory interleaving options in the UEFI. Maybe the way the IO die aggregates the memory channels can be tweaked to achive the expected performance even with 6 DIMMs. Or maybe that's only achievable with Milan.Mikewind Dale - Friday, July 16, 2021 - link
Ahhh, I see what you mean. Thanks. Well, I have 8 DIMMs now, and I don't want to mess with my system any more. Maybe Anandtech can test this.