AMD Threadripper Pro Review: An Upgrade Over Regular Threadripper?
by Dr. Ian Cutress on July 14, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- ThreadRipper
- Threadripper Pro
- 3995WX
CPU Tests: Legacy and Web
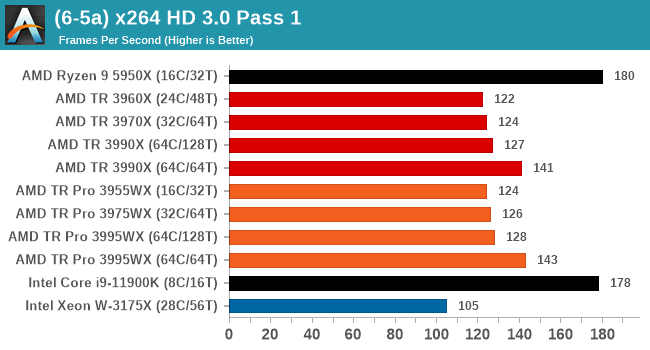
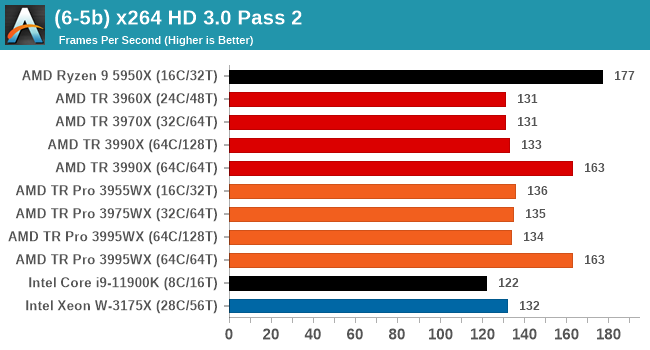
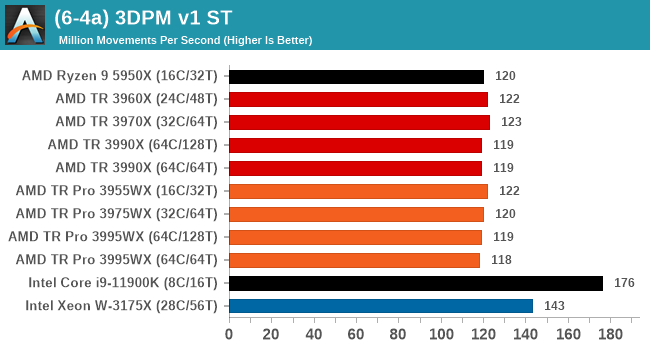
In order to gather data to compare with older benchmarks, we are still keeping a number of tests under our ‘legacy’ section. This includes all the former major versions of CineBench (R15, R11.5, R10) as well as x264 HD 3.0 and the first very naïve version of 3DPM v2.1. We won’t be transferring the data over from the old testing into Bench, otherwise it would be populated with 200 CPUs with only one data point, so it will fill up as we test more CPUs like the others.
The other section here is our web tests.
Web Tests: Kraken, Octane, and Speedometer
Benchmarking using web tools is always a bit difficult. Browsers change almost daily, and the way the web is used changes even quicker. While there is some scope for advanced computational based benchmarks, most users care about responsiveness, which requires a strong back-end to work quickly to provide on the front-end. The benchmarks we chose for our web tests are essentially industry standards – at least once upon a time.
It should be noted that for each test, the browser is closed and re-opened a new with a fresh cache. We use a fixed Chromium version for our tests with the update capabilities removed to ensure consistency.
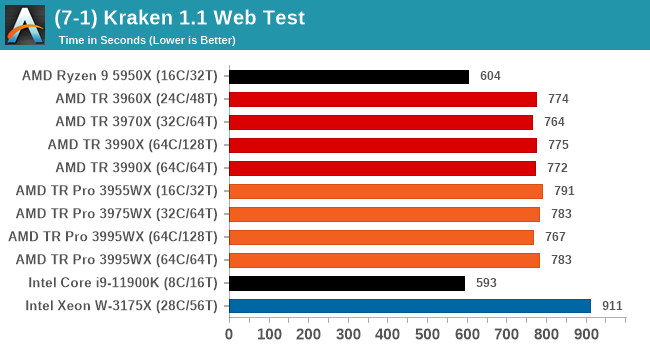
Mozilla Kraken 1.1
Kraken is a 2010 benchmark from Mozilla and does a series of JavaScript tests. These tests are a little more involved than previous tests, looking at artificial intelligence, audio manipulation, image manipulation, json parsing, and cryptographic functions. The benchmark starts with an initial download of data for the audio and imaging, and then runs through 10 times giving a timed result.

We loop through the 10-run test four times (so that’s a total of 40 runs), and average the four end-results. The result is given as time to complete the test, and we’re reaching a slow asymptotic limit with regards the highest IPC processors.
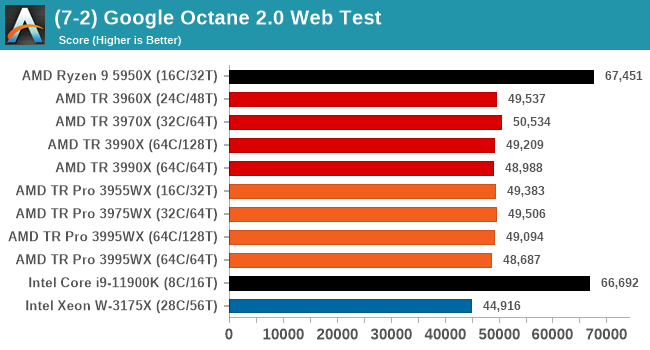
Google Octane 2.0
Our second test is also JavaScript based, but uses a lot more variation of newer JS techniques, such as object-oriented programming, kernel simulation, object creation/destruction, garbage collection, array manipulations, compiler latency and code execution.
Octane was developed after the discontinuation of other tests, with the goal of being more web-like than previous tests. It has been a popular benchmark, making it an obvious target for optimizations in the JavaScript engines. Ultimately it was retired in early 2017 due to this, although it is still widely used as a tool to determine general CPU performance in a number of web tasks.
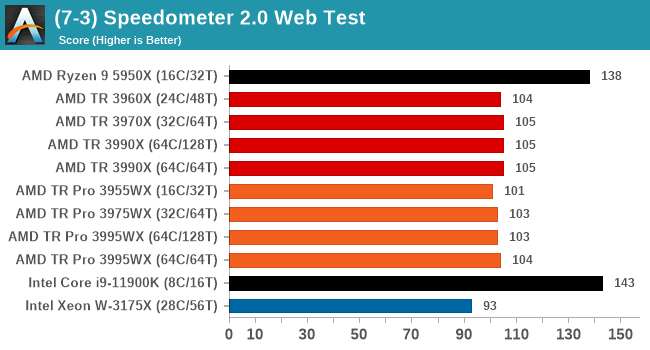
Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a test over a series of JavaScript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics.
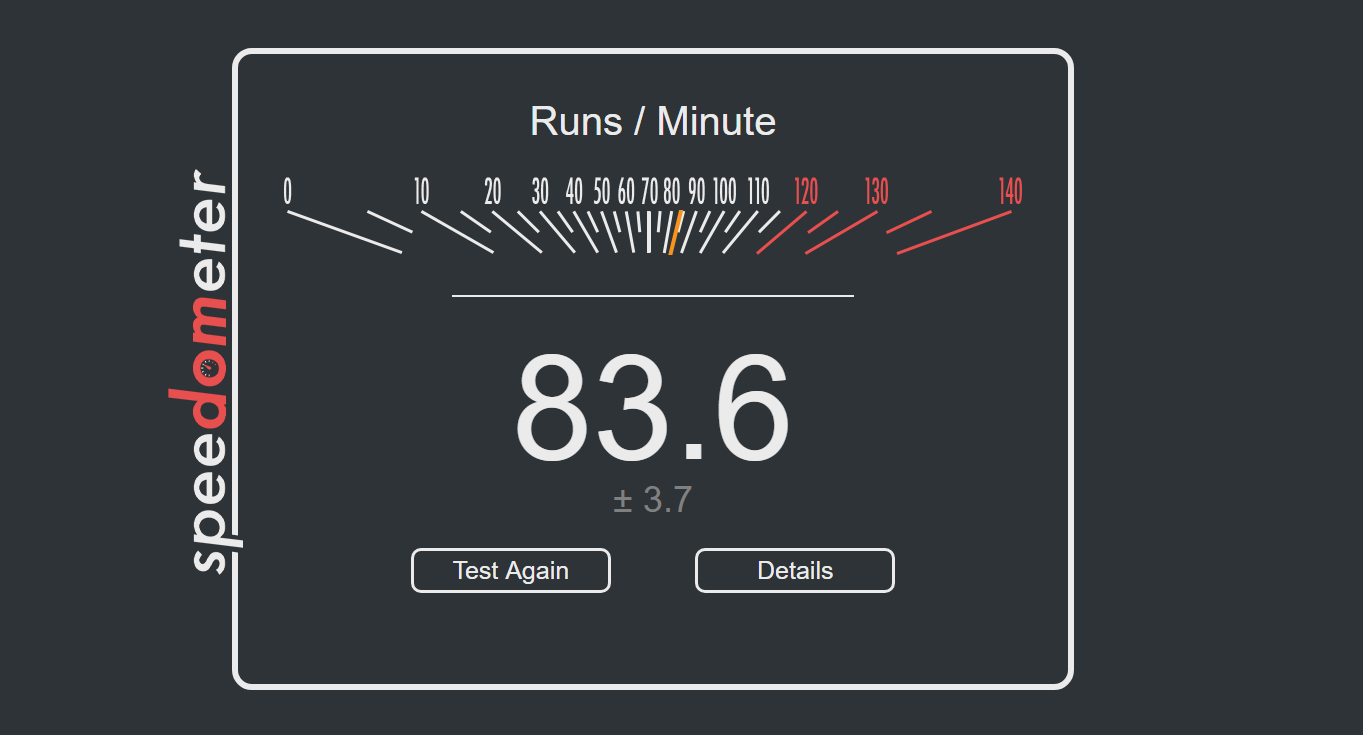
We repeat over the benchmark for a dozen loops, taking the average of the last five.
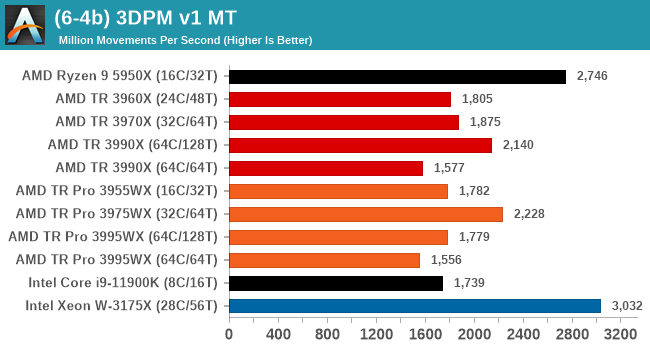
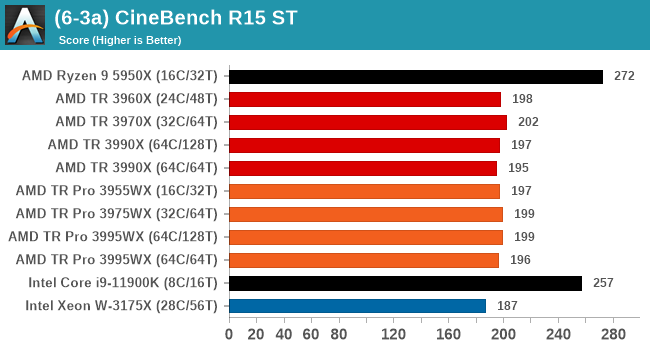
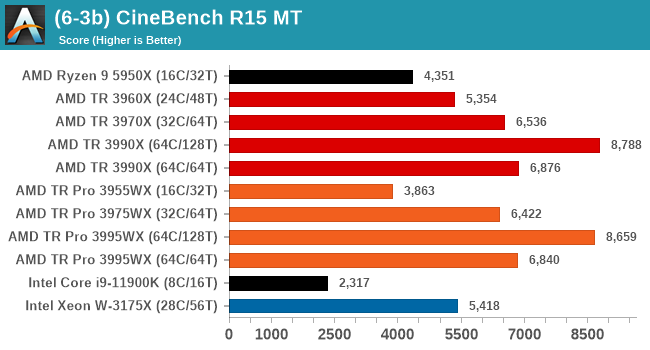
Legacy Tests








98 Comments
View All Comments
Mikewind Dale - Wednesday, July 14, 2021 - link
I have a ThreadRipper Pro 3955WX, and I discovered something interesting about the memory bandwidth.Originally, I bought 4x64 GB ECC RDIMM because I thought 256 GB might be enough, and I wanted to leave some empty RAM slots to populate with 128 GB RDIMMs if those ever became cost-effective. (Right now, 128 GB RDIMMs are about triple the price of 64 GB.)
CPU-Z and AIDA64 reported "quad" channel memory, and AIDA64's memory benchmarks showed reasonable memory performance.
But I discovered that 256 GB wasn't enough for my application, so I bought 2 more 64 GB RDIMMs.
At this point, I had 6 DIMMs populated. CPU-Z and AIDA64 both reported "hexa" channel memory, but AIDA64's memory benchmarks showed that my memory performance was about 2/3 that of a Ryzen.
So I bought 2 more RDIMMs again, for a total of 8. Now, my memory benchmark in AIDA64 is much closer to expected.
So the moral of the story is: you can populate 4 DIMMs, or you can populate 8, but don't dare populate 6. Populating precisely 6 DIMMs will absolutely cripple your memory performance, whereas 4 DIMMs still have acceptable performance.
kobblestown - Wednesday, July 14, 2021 - link
The 3955 probably has only 2 CCDs and is therefore limited to 4 DDR channels throughput. It seems that each IF link has the throughput of 2 DDR channels and this makes sense.You should keep in mind that the IO die has in effect 4 dual channel controllers and you may have populated them suboptimally. If you have two dual channel controllers fully populated and two half populated (instead of a third fully populated and the fourth one staying empty) you'll have skewed results. Also, there was some noise about Milan working better with 6 channel configurations so it may be something specific to Rome chips.
Rudde - Wednesday, July 14, 2021 - link
Server providers had requested for 6 channel memory support for server processors and that was implemented in Milan.McFig - Wednesday, July 14, 2021 - link
What kobblestown is suggesting is that maybe Mikewind Dale could have gotten the 6 RDIMMs working by moving one of them so that each pair is fully populated.Mikewind Dale - Wednesday, July 14, 2021 - link
McFig, there are only 8 slots, so I'm not sure how I could have moved the 6 DIMMs among the 8 slots to ensure that each pair is populated.1_rick - Wednesday, July 14, 2021 - link
He probably means "each of 3 pairs fully populated".DougMcC - Wednesday, July 14, 2021 - link
I think the question is whether 3/3 is better than 4/2kobblestown - Friday, July 16, 2021 - link
Heya! Sorry for the nebulous formulation. In terms of the number of DIMMS per memory controller, I suggest having 2+2+2+0 instead of 2+1+2+1. One needs to figure out what this means for any particular MB. But as DougMcC suggests, that would probably mean having 4 DIMMs on one side of the CPU and 2 on the other, rather than having 3 DIMMs on each side. The latter is bound to be suboptimal. Whether the former offers an improvement is something that I would be very interested to know but could be that Rome has some shortcoming in this area which is addressed in Milan.Again, dual CCD configurations are limited to 4 channel bandwidth but it's still worth it to have all channels populated so you don't get bitten by badly handled assymetry and the IO does not fight (too much) with the cores for the bandwidth.
kobblestown - Friday, July 16, 2021 - link
BTW, one should also check the memory interleaving options in the UEFI. Maybe the way the IO die aggregates the memory channels can be tweaked to achive the expected performance even with 6 DIMMs. Or maybe that's only achievable with Milan.Mikewind Dale - Friday, July 16, 2021 - link
Ahhh, I see what you mean. Thanks. Well, I have 8 DIMMs now, and I don't want to mess with my system any more. Maybe Anandtech can test this.