AMD Threadripper Pro Review: An Upgrade Over Regular Threadripper?
by Dr. Ian Cutress on July 14, 2021 9:00 AM EST- Posted in
- CPUs
- AMD
- ThreadRipper
- Threadripper Pro
- 3995WX
CPU Tests: SPEC
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0-svn350067-1~exp1+0~20181226174230.701~1.gbp6019f2 (trunk)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark. All of the major vendors, AMD, Intel, and Arm, all support the way in which we are testing SPEC.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
For each of the SPEC targets we are doing, SPEC2006 rate-1, SPEC2017 rate-1, and SPEC2017 rate-N, rather than publish all the separate test data in our reviews, we are going to condense it down into a few interesting data points. The full per-test values are in our benchmark database.
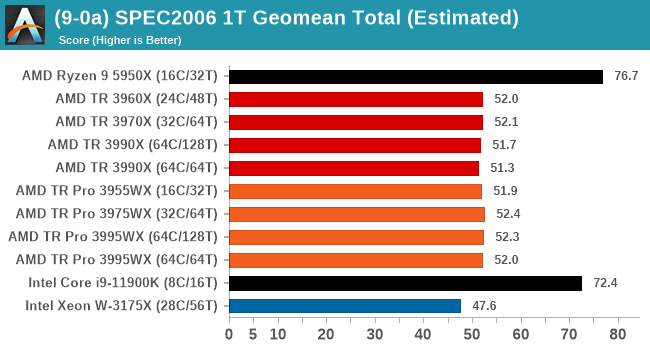
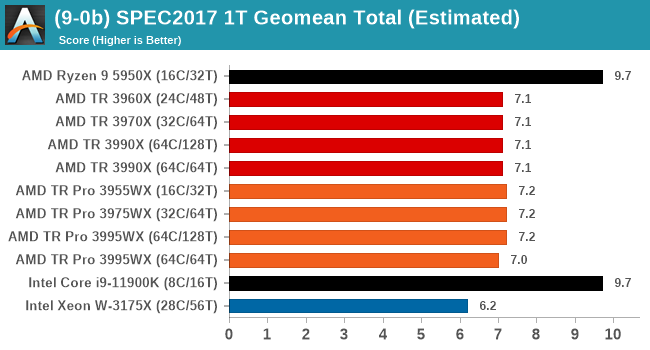
Single thread is very much what we expected, with the consumer processors out in the lead and no real major differences between TR and TR Pro.
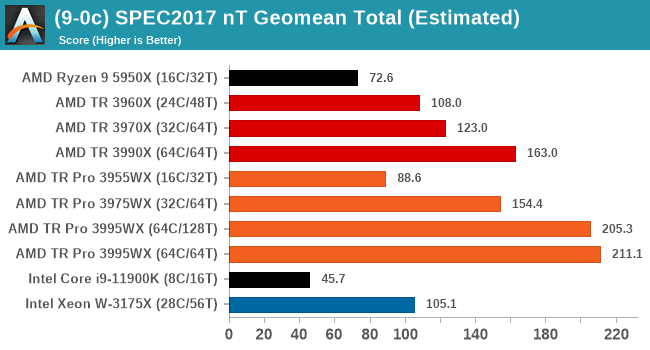
That changes when we move into full thread mode. The extra bandwidth of TR Pro is clear to see, even in the 32C/64T model. In this test we're using 128 GB of memory for all TR and TR Pro processors, and we're seeing a small bump when in 64C/64T mode, perhaps due to the increased memory cap/thread and memory bandwidth/thread as well. The 3990X 64C/128T run kept failing for an odd reason, so we do not have a score for that test.








98 Comments
View All Comments
Mikewind Dale - Wednesday, July 14, 2021 - link
I have a ThreadRipper Pro 3955WX, and I discovered something interesting about the memory bandwidth.Originally, I bought 4x64 GB ECC RDIMM because I thought 256 GB might be enough, and I wanted to leave some empty RAM slots to populate with 128 GB RDIMMs if those ever became cost-effective. (Right now, 128 GB RDIMMs are about triple the price of 64 GB.)
CPU-Z and AIDA64 reported "quad" channel memory, and AIDA64's memory benchmarks showed reasonable memory performance.
But I discovered that 256 GB wasn't enough for my application, so I bought 2 more 64 GB RDIMMs.
At this point, I had 6 DIMMs populated. CPU-Z and AIDA64 both reported "hexa" channel memory, but AIDA64's memory benchmarks showed that my memory performance was about 2/3 that of a Ryzen.
So I bought 2 more RDIMMs again, for a total of 8. Now, my memory benchmark in AIDA64 is much closer to expected.
So the moral of the story is: you can populate 4 DIMMs, or you can populate 8, but don't dare populate 6. Populating precisely 6 DIMMs will absolutely cripple your memory performance, whereas 4 DIMMs still have acceptable performance.
kobblestown - Wednesday, July 14, 2021 - link
The 3955 probably has only 2 CCDs and is therefore limited to 4 DDR channels throughput. It seems that each IF link has the throughput of 2 DDR channels and this makes sense.You should keep in mind that the IO die has in effect 4 dual channel controllers and you may have populated them suboptimally. If you have two dual channel controllers fully populated and two half populated (instead of a third fully populated and the fourth one staying empty) you'll have skewed results. Also, there was some noise about Milan working better with 6 channel configurations so it may be something specific to Rome chips.
Rudde - Wednesday, July 14, 2021 - link
Server providers had requested for 6 channel memory support for server processors and that was implemented in Milan.McFig - Wednesday, July 14, 2021 - link
What kobblestown is suggesting is that maybe Mikewind Dale could have gotten the 6 RDIMMs working by moving one of them so that each pair is fully populated.Mikewind Dale - Wednesday, July 14, 2021 - link
McFig, there are only 8 slots, so I'm not sure how I could have moved the 6 DIMMs among the 8 slots to ensure that each pair is populated.1_rick - Wednesday, July 14, 2021 - link
He probably means "each of 3 pairs fully populated".DougMcC - Wednesday, July 14, 2021 - link
I think the question is whether 3/3 is better than 4/2kobblestown - Friday, July 16, 2021 - link
Heya! Sorry for the nebulous formulation. In terms of the number of DIMMS per memory controller, I suggest having 2+2+2+0 instead of 2+1+2+1. One needs to figure out what this means for any particular MB. But as DougMcC suggests, that would probably mean having 4 DIMMs on one side of the CPU and 2 on the other, rather than having 3 DIMMs on each side. The latter is bound to be suboptimal. Whether the former offers an improvement is something that I would be very interested to know but could be that Rome has some shortcoming in this area which is addressed in Milan.Again, dual CCD configurations are limited to 4 channel bandwidth but it's still worth it to have all channels populated so you don't get bitten by badly handled assymetry and the IO does not fight (too much) with the cores for the bandwidth.
kobblestown - Friday, July 16, 2021 - link
BTW, one should also check the memory interleaving options in the UEFI. Maybe the way the IO die aggregates the memory channels can be tweaked to achive the expected performance even with 6 DIMMs. Or maybe that's only achievable with Milan.Mikewind Dale - Friday, July 16, 2021 - link
Ahhh, I see what you mean. Thanks. Well, I have 8 DIMMs now, and I don't want to mess with my system any more. Maybe Anandtech can test this.