A Broadwell Retrospective Review in 2020: Is eDRAM Still Worth It?
by Dr. Ian Cutress on November 2, 2020 11:00 AM ESTCPU Tests: Synthetic
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
Linux OpenSSL Speed: SHA256
One of our readers reached out in early 2020 and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode. All the graphs are in our benchmark database, Bench, and we use the sha256 results in published reviews.

AMD's processors, and Intel AVX512, have sha256 acceleration, however this doesn't help Broadwell.
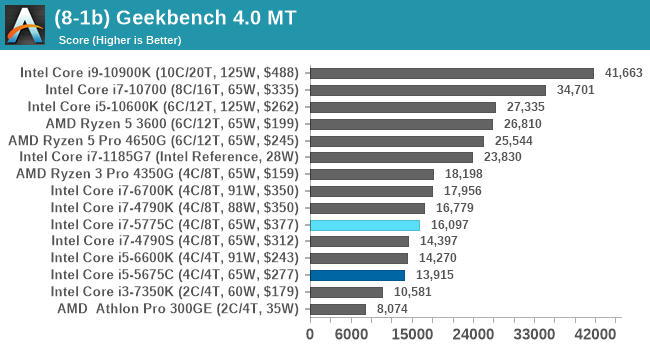
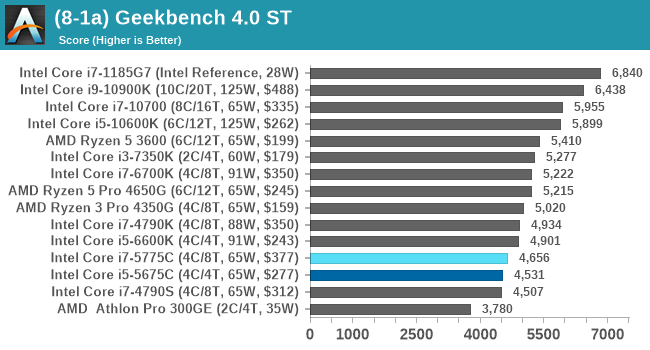
GeekBench: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers).
We have both GB5 and GB4 results in our benchmark database. GB5 was introduced to our test suite after already having tested ~25 CPUs, and so the results are a little sporadic by comparison. These spots will be filled in when we retest any of the CPUs.
LinX 0.9.5 LINPACK
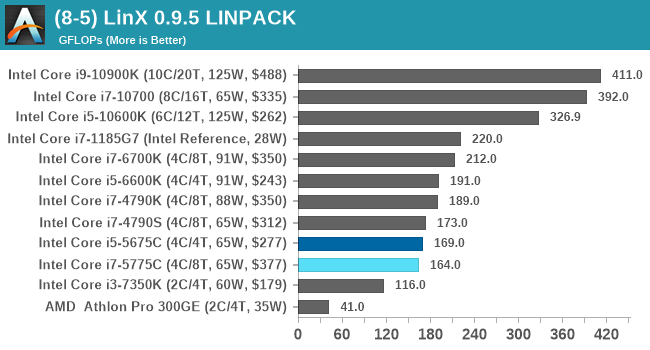
One of the benchmarks I’ve been after for a while is just something that outputs a very simple GFLOPs FP64 number, or in the case of AI I’d like to get a value for TOPs at a given level of quantization (FP32/FP16/INT8 etc). The most popular tool for doing this on supercomputers is a form of LINPACK, however for consumer systems it’s a case of making sure that the software is optimized for each CPU.
LinX has been a popular interface for LINPACK on Windows for a number of years. However the last official version was 0.6.5, launched in 2015, before the latest Ryzen hardware came into being. HWTips in Korea has been updating LinX and has separated out into two versions, one for Intel and one for AMD, and both have reached version 0.9.5. Unfortunately the AMD version is still a work in progress, as it doesn’t work on Zen 2.
There does exist a program called Linpack Extreme 1.1.3, which claims to be updated to use the latest version of the Intel Math Kernel Libraries. It works great, however the way the interface has been designed means that it can’t be automated for our uses, so we can’t use it.
For LinX 0.9.5, there also is a difficulty of what parameters to put into LINPACK. The two main parameters are problem size and time – choose a problem size too small, and you won’t get peak performance. Choose it too large, and the calculation can go on for hours. To that end, we use the following algorithms as a compromise:
- Memory Use = Floor(1000 + 20*sqrt(threads)) MB
- Time = Floor(10+sqrt(threads)) minutes
For a 4 thread system, we use 1040 MB and run for 12 minutes.
For a 128 thread system, we use 1226 MB and run for 21 minutes.








120 Comments
View All Comments
realbabilu - Monday, November 2, 2020 - link
That Larger cache maybe need specified optimized BLAS.Kurosaki - Monday, November 2, 2020 - link
Did you mean BIAS?ballsystemlord - Tuesday, November 3, 2020 - link
BLAS == Basic Linear Algebra System.Kamen Rider Blade - Monday, November 2, 2020 - link
I think there is merit to having Off-Die L4 cache.Imagine the low latency and high bandwidth you can get with shoving some stacks of HBM2 or DDR-5, whichever is more affordable and can better use the bandwidth over whatever link you're providing.
nandnandnand - Monday, November 2, 2020 - link
I'm assuming that Zen 4 will add at least 2-4 GB of L4 cache stacked on the I/O die.ichaya - Monday, November 2, 2020 - link
Waiting for this to happen... have been since TR1.nandnandnand - Monday, November 2, 2020 - link
Throw in an RDNA 3 chiplet (in Ryzen 6950X/6900X/whatever) for iGPU and machine learning, and things will get really interesting.ichaya - Monday, November 2, 2020 - link
Yep.dotjaz - Saturday, November 7, 2020 - link
That's definitely not happening. You are delusional if you think RDNA3 will appear as iGPU first.At best we can hope the next I/O die to intergrate full VCN/DCN with a few RDNA2 CUs.
dotjaz - Saturday, November 7, 2020 - link
Also doubly delusional if think think RDNA3 is any good for ML. CDNA2 is designed for that.Adding powerful iGPU to Ryzen 9 servers literally no purpose. Nobody will be satisfied with that tiny performance. Guaranteed recipe for instant failure.
The only iGPU that would make sense is a mini iGPU in I/O die for desktop/video decoding OR iGPU coupled with low end CPU for an complete entry level gaming SOC aka APU. Chiplet design almost makes no sense for APU as long as GloFo is in play.