Intel Moving to Chiplets: ‘Client 2.0’ for 7nm
by Dr. Ian Cutress on August 21, 2020 5:00 PM EST- Posted in
- CPUs
- Intel
- GPUs
- Client
- Intel Arch Day 2020
- Client 2.0
One of the more esoteric elements of Intel’s Architecture Day 2020 came very near the end, where Intel spent a few minutes discussing what it believes is the future of some of its products. Brijesh Tripathi, VP and CTO of Intel’s Client Computing group, laid out a vision about the future of its client products in the 2024+ future timeframe. Centered around Intel’s 7+ manufacturing process, the goal was to enable ‘Client 2.0’ – a new way to deliver and enable immersive experiences through a more optimized silicon development strategy.
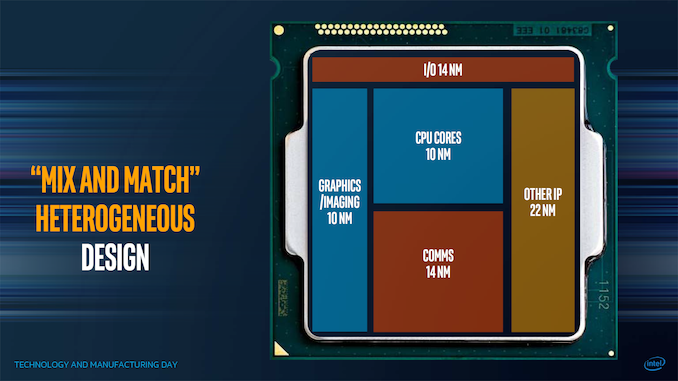
Chiplets aren’t new, especially with recent launches from Intel’s competitors, and as we move into more complex process node development, the era of chiplets enables faster time-to-market as well as better binning and yields for a given product. The key is enabling how those chiplets fit together, and at which points it makes sense to mix and match the relevant ones. Intel has spoken about this before in a more generalized context, at its Technology and Manufacturing Day 2017, as shown in the carousel image at the top.
The goal here is to mix and match which process nodes work best for different parts of the chip. Intel seems set to realize this vision starting with its 7nm platform. At Architecture Day 2020, Brijesh Tripathi showed this slide:

On the left is a typical chip design – monolithic with everything it requires. For Intel’s leading edge products, these take 3-4 years to develop, and bugs are found in silicon by both Intel initially and then later by Intel’s partners as they can ramp up the silicon-on time by a a few orders of magnitude.
In the middle is a basic chiplet layout, similar to that slide from 2017, where different functions of the die are split into their own modules. Assuming a consistent interconnect, there are some reuse of the silicon elements, such as AMD using the same core compute dies in client and server. For some semiconductor companies (except Intel), this is where we are.
On the right is where Intel sees its future. Instead of having a single digit number of chiplets in a product, it envisions a world where each IP can be split into multiple chiplets, enabling products to be built with different configurations of what works for the market. In this instance, a chiplet might be a PCIe 4.0 x16 link – if the product needs more, it simply adds in more of these chiplets. Same with memory channels, cores, media accelerators, AI accelerators, Ray Tracing engines, crypto accelerators, graphics, or even as far down as SRAM and caching blocks. The idea is that each IP can be split and then scaled. This means that the chiplets are tiny, can be built relatively quickly, and bugs should be ironed out very quickly.

In this diagram, we are treated to Intel’s long term vision for the client – a base interposer with an in-package memory (something like an L3 or L4) that can act as the main SRAM cache for the whole die, and then on top of this we get 24 different chiplets. Chiplets can be graphics, cores, AI, Media, IO, or anything else, but they can be mixed and matched based on what is needed. A content creator might want a balance between some good graphics acceleration and compute, while a gamer might want to focus purely on the graphics. A corporate client or workstation might need less graphics and more for compute and AI, whereas a mobile version of the chip will be heavily invested in IO.

As always, there is some trade-off between chiplet size and complexity of actually putting them together in a multi-die arrangement. Any communications between chiplets costs more power than a monolithic interpretation, and usually offer higher latency. Thermals have to be managed as well, and so sometimes those chiplets are limited by what thermal properties are available. Multi-die arrangements also cause headaches for mobile devices, where z-height is critical. However, the benefits afforded from using the right process at the right time for the right product are big, as it helps provide both performance and power at the best possible cost. It also gives the opportunity to bring in 3rd party IP quickly if something amazing hits the scene.
The only downside here is that Intel hasn’t spoken much about the glue that binds it all together. Chiplet strategies rely on complex high-speed interconnect protocols, custom or otherwise. Current uses of Intel’s die-to-die connectivity are either simply memory protocols or FPGA fabric extensions – the big ones for server CPUs like UPI aren’t necessarily up to the task. CXL could be the future here, however current CXL is built upon PCIe, which means a complex CXL/PCIe controller for every chiplet which will likely get power hungry fast.
Intel has stated that they are inventing new packaging technology and new levels of connectivity to act between the silicon - there is no disclosure on the protocols at this time, however Intel acknowledges that to get to this level of scale it will have to go beyond what the company has today, and that will require creating standards and innovation in this area. The goal is to create and support standards, and the first incarnation will have some standardization built in. Intel states that this is a method of extreme disaggregation, and to note that not everything that is connected has to be high bandwidth (such as USB) or a coherent interconnect - Intel sees the goal involving a handful of protocols throughout the spectrum.
There’s also the developer market, which might be used to a more homogeneous implementation of resources in any given product. Without careful planning, and relevant coding, there is the potential for certain chiplet configurations to fall over if the developer was expecting a certain ratio of compute to graphics, for example. This isn’t something that OneAPI could easily fix.
These are all issues that Intel will have to address, although they have a few years until this comes to fruition. We were told that the internal name is Client 2.0, although it will likely have more marketing dressing added as Intel starts talking about it in more detail.
Related Reading
- Intel's Interconnected Future: Combining Chiplets, EMIB, and Foveros
- Intel 7nm Delayed By 6 Months; Company to Take “Pragmatic” Approach in Using Third-Party Fabs
- The Intel Lakefield Deep Dive: Everything To Know About the First x86 Hybrid CPU
- Intel to use Nanowire/Nanoribbon Transistors in Volume ‘in Five Years’








67 Comments
View All Comments
CajunArson - Friday, August 21, 2020 - link
"The only downside here is that Intel hasn’t spoken much about the glue that binds it all together. "Uh... you apparently missed the last several years of EMIB and Foveros? Not to mention all the products that have already used these interconnects?
P.S. --> Calling Emib and Foveros "glue" compared to AMD's 1970's era copper traces in plastic "glue" is like calling the Space X Dragon 2 just another capsule like Mercury 1.
hetzbh - Friday, August 21, 2020 - link
You are mixing 2 different things: You are talking about glue in terms of vertical "binding" between layers.Ian is talking about chip to chip communication. If you know AMD tech, think about things like Infinity fabric.
BTW, Intel had an experience with "glue" - look at Kaby Lake G which had a Vega chip in it. In that case it was a simply PCIe connection (and not a fast one, either).
Atari2600 - Friday, August 21, 2020 - link
Indeed. [/Tealc]Without a basis for communication, Intel are whistling in the wind here.
Look at the power budget for AMD's infinity fabric when it came to core vs. uncore. When the number of chiplets rises, so does uncore power budget (and not far away from linear either).
https://www.anandtech.com/show/13124/the-amd-threa...
Intels many chiplet strategy (especially without a magic communication system) is going to blow the entire power budget on each chiplet talking to each other to say "I've no available power to do any work".
eek2121 - Saturday, August 22, 2020 - link
AMD is actively working on improving power efficiency in future generations of chips, however.Sahrin - Saturday, August 22, 2020 - link
Not only that, but AMD has patents on interdie communication tech dating back to 2003 and this is not part of the AMD64 cross-license. AMD has made massive strides in cutting IF power consumption just between Zen and Zen 2.Will be interesting to see the IP 'interconnect' Wars.
lmcd - Friday, August 21, 2020 - link
As if either AMD or Intel would deliver a custom interconnect for a low-volume part?eddman - Saturday, August 22, 2020 - link
The EMIB on Kaby Lake-G is used to connect the GPU to its memory, not CPU to GPU.https://www.extremetech.com/wp-content/uploads/201...
https://www.techspot.com/review/1654-intel-kaby-la...
eddman - Saturday, August 22, 2020 - link
https://fuse.wikichip.org/news/1634/hot-chips-30-i...Ian Cutress - Saturday, August 22, 2020 - link
hetzbh is correct. I was referring to the fabric interconnect, not the die-to-die connections. It literally talks about high-speed fabric protocols in the next sentence and the rest of the paragraph. It'd be a bit odd just to mention physical interconnect in that context just on its own.Besides, you've commented *A LOT* on my articles where I've gone into detail about all the different levels of physical interconnect that Intel have been developing. Literally in the related reading section underneath are several of my articles on those exact topics.
Who exactly are you trying to fool?
psyclist80 - Saturday, August 22, 2020 - link
It was probably the glue comment, it triggered him and was a clever play on words considering Intel's previous comments regarding MCM, what a difference 3 years makes.