The Samsung 870 QVO (1TB & 4TB) SSD Review: QLC Refreshed
by Billy Tallis on June 30, 2020 11:40 AM ESTWhole-Drive Fill
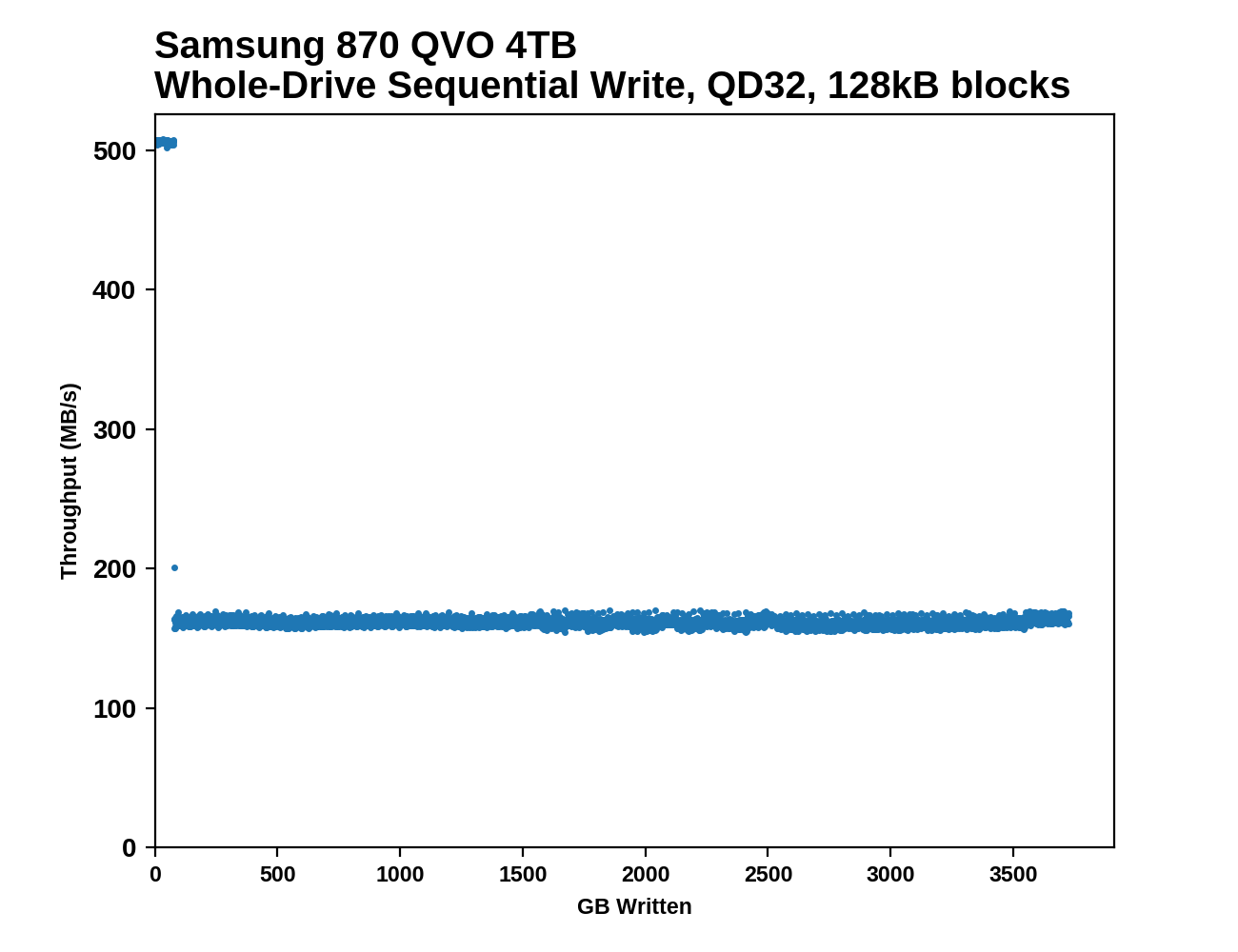
This test starts with a freshly-erased drive and fills it with 128kB sequential writes at queue depth 32, recording the write speed for each 1GB segment. This test is not representative of any ordinary client/consumer usage pattern, but it does allow us to observe transitions in the drive's behavior as it fills up. This can allow us to estimate the size of any SLC write cache, and get a sense for how much performance remains on the rare occasions where real-world usage keeps writing data after filling the cache.
 |
|||||||||
The SLC caches on the 870 QVOs run out right on schedule, at 42 GB and 78 GB. Write performance drops precipitously but is stable thereafter, for the rest of the drive fill process. This behavior hasn't changed meaningfully from the 860 QVO.
 |
|||||||||
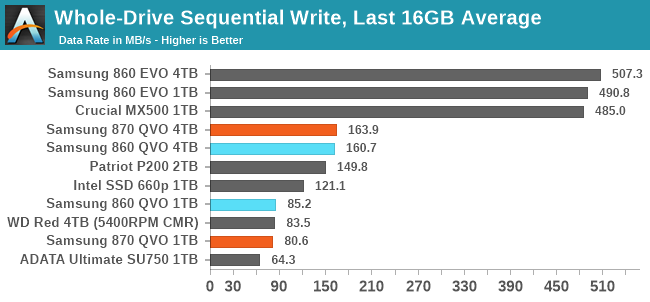
| Average Throughput for last 16 GB | Overall Average Throughput | ||||||||
The 870 QVO turns in scores that are very similar to its predecessor. The 1TB model averages similar write performance to a hard drive, albeit with very different performance characteristics along the way. The 4TB model manages to stay ahead of the hard drive's write performance for pretty much the entire run. Both capacities of QLC drives offer a mere fraction of the post-cache write speed of mainstream TLC drives, and even the 2TB DRAMless TLC drive offers much better sequential write performance for almost all of the test duration.
Working Set Size
Most mainstream SSDs have enough DRAM to store the entire mapping table that translates logical block addresses into physical flash memory addresses. DRAMless drives only have small buffers to cache a portion of this mapping information. Some NVMe SSDs support the Host Memory Buffer feature and can borrow a piece of the host system's DRAM for this cache rather needing lots of on-controller memory.
When accessing a logical block whose mapping is not cached, the drive needs to read the mapping from the full table stored on the flash memory before it can read the user data stored at that logical block. This adds extra latency to read operations and in the worst case may double random read latency.
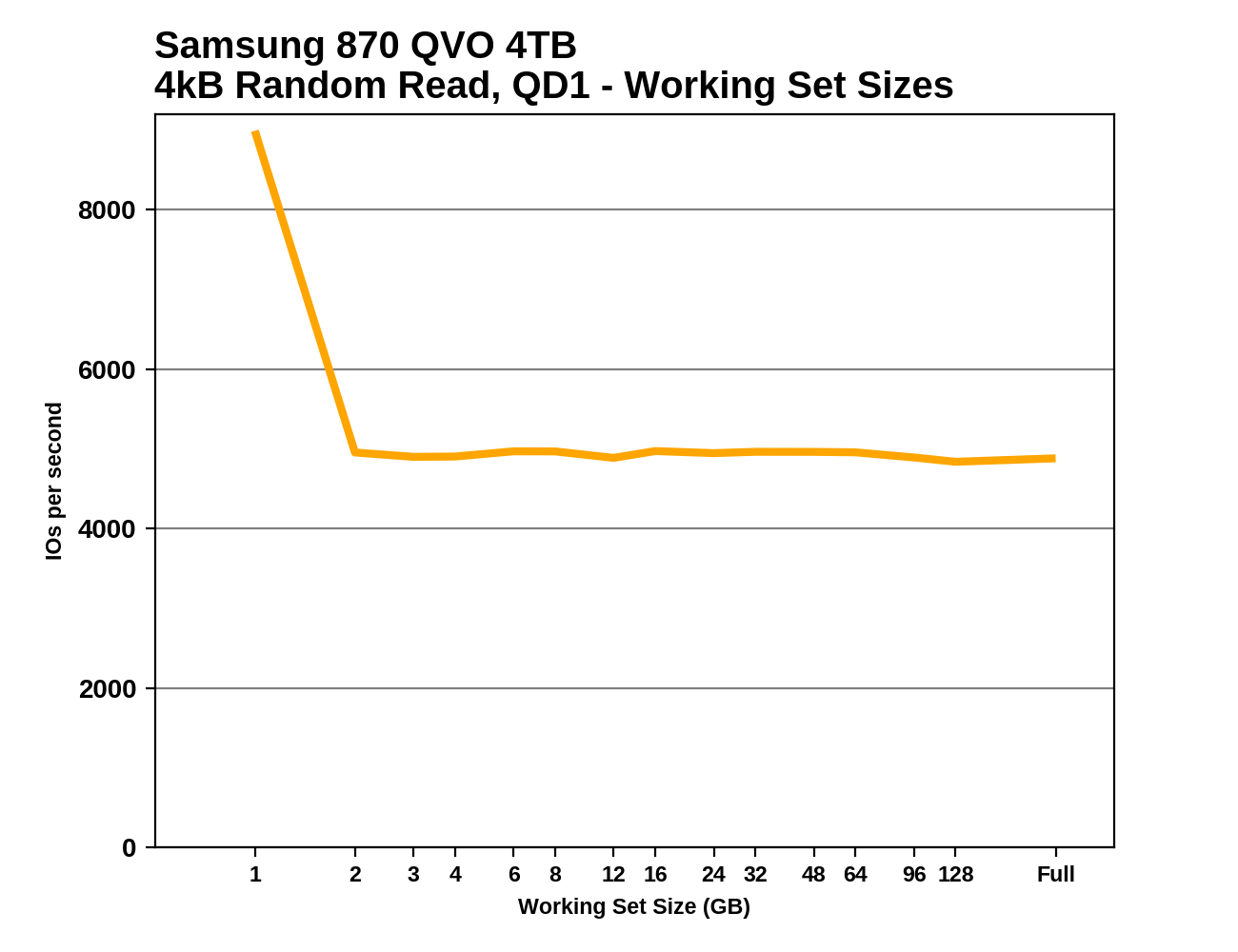
We can see the effects of the size of any mapping buffer by performing random reads from different sized portions of the drive. When performing random reads from a small slice of the drive, we expect the mappings to all fit in the cache, and when performing random reads from the entire drive, we expect mostly cache misses.
When performing this test on mainstream drives with a full-sized DRAM cache, we expect performance to be generally constant regardless of the working set size, or for performance to drop only slightly as the working set size increases.
 |
|||||||||
The 870 QVO clearly has improved read latency over its predecessors, and that's enough for the 1TB 870 to slightly outperform the ADATA SU750, a DRAMless TLC drive. The 4TB 870 QVO also shows a new behavior, with excellent random read performance at the very beginning of the test—better even that the TLC-based 860 EVOs. It looks like this test may have caught some data that was still being served from the SLC cache. Otherwise, the 870 QVOs don't care much about data locality for random reads, unlike many drives with limited or no DRAM cache.








64 Comments
View All Comments
akramargmail - Tuesday, June 30, 2020 - link
So this is better for Samsung, but not for me. Never wanted the 860 QVO and see no reason to change my mind.yeeeeman - Tuesday, June 30, 2020 - link
I agree. Samsung is losing a big chance with this line of SSDs by pricing them very high for what they can do and what competition they have.Urwni - Tuesday, June 30, 2020 - link
Yeah, 860 EVO is still competitive, considering its price, performance and reliability.Great_Scott - Thursday, July 2, 2020 - link
Ahhh. The late great 870 QVO. Perfect match in price and (mostly) performance with major mfr TLC drives.It has no reason to exist at the price point it's sold at. A shame.
B Huggy - Monday, July 6, 2020 - link
"So this is better for Samsung, but not for me. Never wanted the 860 QVO and see no reason to change my mind."Love it - you don't even own it, but somehow it's bad for you. :D
shabby - Tuesday, June 30, 2020 - link
Approaching hdd speeds... congrats samsung 👏👏👏leexgx - Sunday, July 5, 2020 - link
For £0-10 saving I can get this QLC drive (£90 new), just not worth it for the possible slow down compared to a Samsung evo or Crucial mx500 (£90 to £100 new, or less used)Needs to be significantly cheaper
Jorgp2 - Tuesday, June 30, 2020 - link
Those prices are terribleSomeguyperson - Tuesday, June 30, 2020 - link
As Anand said, "There are no bad products, only bad prices".Jorgp2 - Tuesday, June 30, 2020 - link
Whereas Linus says, "It's a bad product if it will get me clicks".