Living On The Edge: Intel Launches Xeon D-2100 Series SoCs
by Ian Cutress on February 7, 2018 9:00 AM ESTSub-NUMA Clustering
When platforms like Xeon D come into existence, focusing on markets that aren’t consumer focused, it can sometimes be difficult to determine which of the consumer or enterprise features are placed into that product. For example, Intel’s Sub-NUMA Clustering (SNC, an upgraded version of Cluster-On-Die) is used in the Xeon Scalable enterprise processors but not on the consumer focused Core-X processors, despite being the same silicon underneath.
SNC is a technology that is drawn from the processor design: within an 18-core processor design, there is actually an x/y arrangement of nodes, in this case we think a 5x5 arrangement. A node can be a core, it can be for memory controllers, for a PCIe root complex, for other IO, and so on. When data needs to be transferred from one node to another, it goes through the mesh topology in what should be the quickest way possible, depending on other node-to-node traffic. Some of the nodes are duplicated, for example, the PCIe x16 root complex nodes, or the memory controllers: for four memory controllers, they are split into pairs, each pair in a separate node, and each of the nodes are at opposite ends of the silicon design. For example, here is the Skylake-SP 18-core layout:
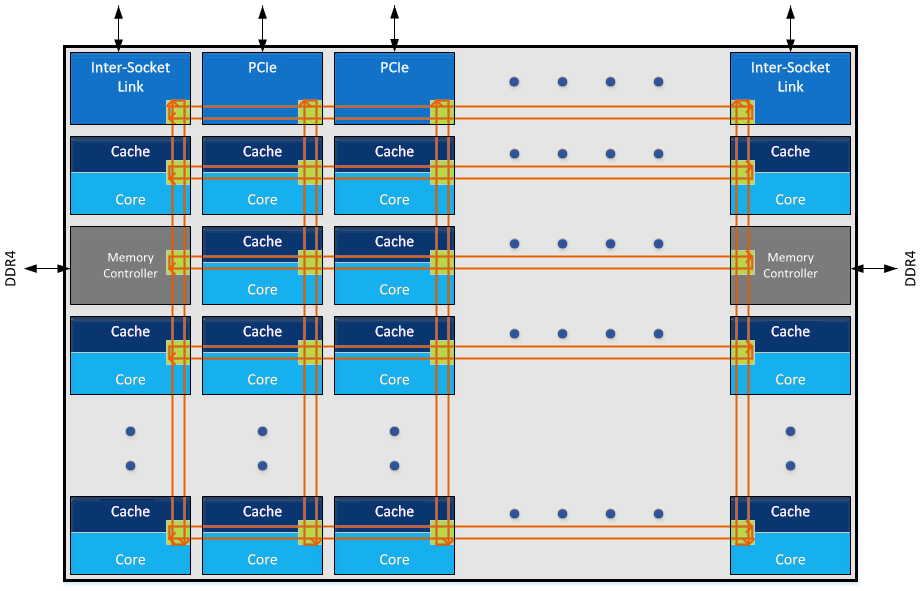
When a system needs main memory, where that memory is held is considered a unified space: the latency to get to all the data is the same. However, due to the physical design of the core, if the data was held in the memory closest to that core in the mesh grid, it would be quicker to access that memory (on average). What SNC does is divide the silicon at a firmware level into two ‘clusters’, with each cluster having a preference for working with the cores, nodes, and memory controllers within its own cluster. There is nothing stopping it going outside its own cluster, but to offer the best latency (sometimes at the expense of peak bandwidth), it is best for each core/node to be limited in this way. Xeon D customers can typically enable SNC in the BIOS of their system, or arrange with their OEM to have it enabled by default.
The reason why SNC is not available in consumer platforms? The benefits/drawbacks of SNC have very little effect on consumer workloads. In most cases users are not striving to minimise their 99th percentile latency figures, while server environments do need to. Also, to get the best out of SNC, software typically has to be written for it, similar to a multi-socket environment.
Intel SpeedShift
The other feature we were interested to see if it made the jump was Intel’s SpeedShift. This technology allows the processor to respond quicker to turbo mode requests, either while in its high-power state or from idle. The standard way a processor works is that when a high-performance power state is requested, the software will send instructions which the operating system will interpret, then the operating system double checks with the firmware for the power state it can ask for, then it will request that power state from the processor. SpeedShift hands control back to the processor, allowing the processor to interpret the frequency and density of the instructions coming into the core, and implement a turbo frequency much quicker.
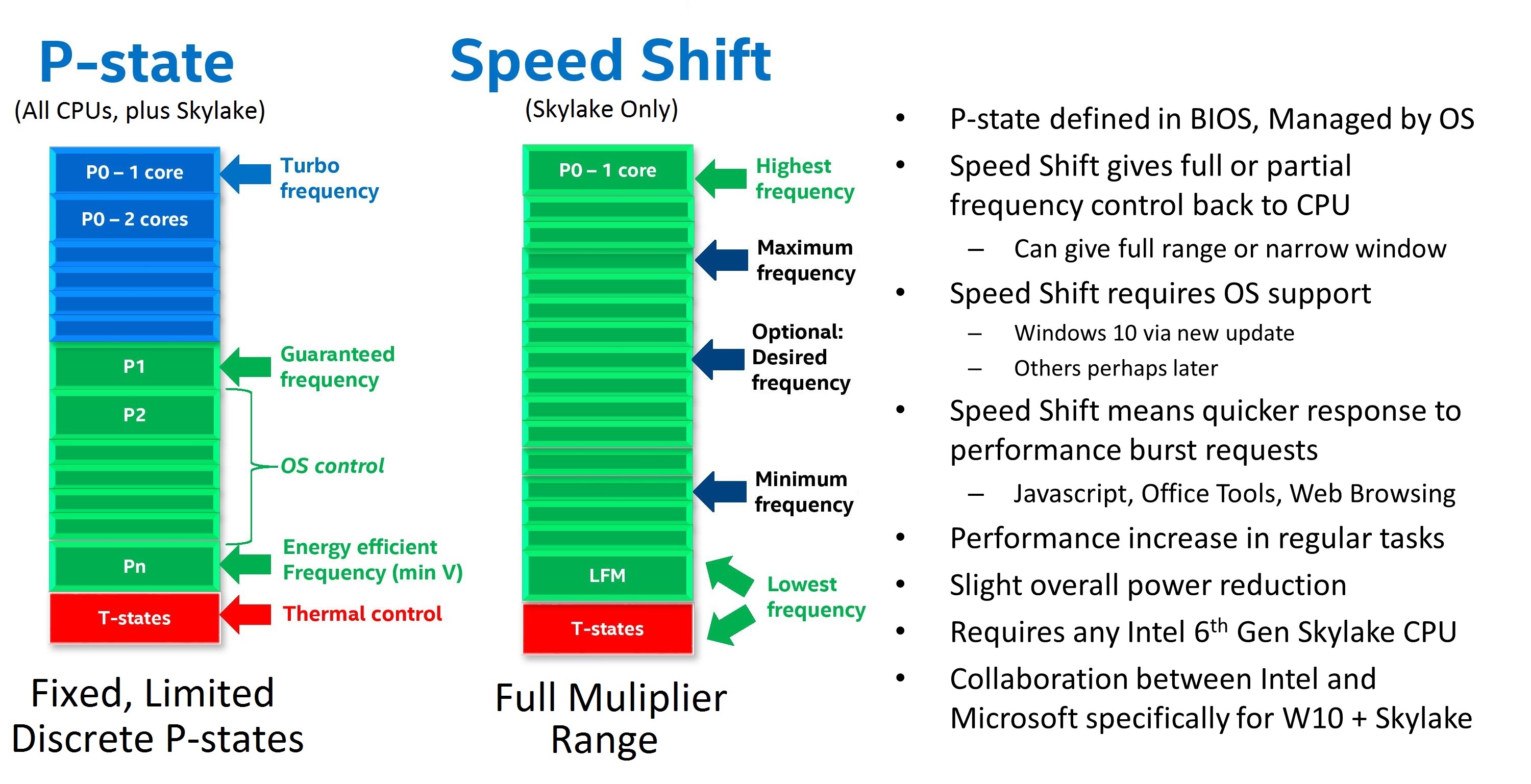
In previous presentations, Intel has stated that this technology drops the time that the processor moves out of idle into peak turbo from 100 milliseconds down to around 25-30 milliseconds. We confirmed that for suitable OS and hypervisor technologies, SpeedShift will also be enabled on the Xeon D-2100 series platform.
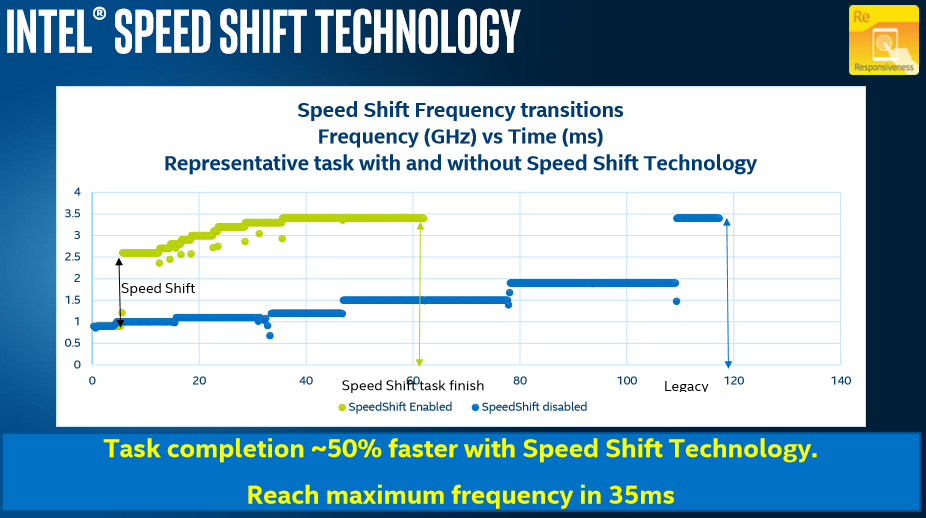
You can read our analysis of Sped Shift on Skylake here:
https://www.anandtech.com/show/9751/examining-intel-skylake-speed-shift-more-responsive-processors
Virtualization
Some of the key ‘edge’ markets that Intel is targeting with the Xeon D-2100 series require virtualization. In our briefing, Intel did not spend much time discussing this part of the product, but did confirm that the latest implementation of VT-x and hardware virtualization technologies is in play. We were told that due to the upgrades over the previous generation of Xeon D, the new platform ‘enables greater VM density for VNF functions, such as Virtual Evolved Packet Core (vEPC), Virtual Content Delivery Network (vCDN), Virtual GiLAN (vGiLAN), Virtualized Radio Access Network (vRAN), and Virtual Broadband Base Unit (vBBU)’.
We were able to confirm that similar to the enterprise platforms, each core can adjust its frequency independently of the other cores, so in multi-user environments if one user is blasting AVX-512 instructions, the frequency of the other cores can still be maintained. This likely applies to L3 cache management, so that ‘noisy neighbors’ cannot crowd L3 use. This situation is less a problem now that the L3 cache is victim cache, but for some customers it can still be an issue.
Availability
Intel stated that it has over a dozen partners, both OEMs and large-scale system integrators, already working with the new D-2100 series ready for product roll-out over 2018. Certain early end-point customers (think the large-scale cloud providers and CDNs) already have had silicon for an amount of time, while it will be rolled out to everyone else in due course through Intel’s partners.

Intel did confirm that it has a sampling program in play for press like AnandTech, so I’m pushing for Johan and Ganesh to get some hands on as we did with the previous generation.
Naming
For the last generation, the Xeon D-1500 series, was tentatively given the code name ‘Broadwell-DE’. By that token, this generation of Xeon D-2100 is based on Skylake, so should be ‘Skylake-DE’. However, references to Skylake-D as an alternative have shown up online, perhaps to keep these code names down to one letter. This isn’t to be confused with Skylake for consumer desktop use, which is usually called Skylake-S. Nice and simple.
Related Reading
- The Intel Xeon D-1500 Review: Performance Per Watt Server SoC Champion
- Evaluating Xeon D-1500 on the Supermicro SYS-5028D-TN4T
- Intel Announces Xeon D-1500 Network Series SoCs with QuickAssist
- ASRock Rack Launches Xeon D Motherboards
- New GIGABYTE Server Motherboards Show Xeon D Round 2
- Skylake-D Creeps Out on Intel’s Price List








22 Comments
View All Comments
Threska - Wednesday, February 7, 2018 - link
" From a pure price perspective, this jump from the top core count part down to the one just below it is sizable, although Intel does have a history with this, such as the E3-1200 Xeon line where the top processor, with a 100 MHz higher frequency than the second best, was 30%+ higher in cost."Must be nice having a monopoly.
Qwertilot - Wednesday, February 7, 2018 - link
That's not a monopoly thing as, by definition, they provide very, very strong competition to themselves :) Some customers are presumably truly price insensitive for whatever reason.Elstar - Wednesday, February 7, 2018 - link
If all you care about is upfront costs, then yes, Intel's high-end parts are expensive. But if you run a data center where "performance/watt" is critical, then the cost of the top parts are reasonable.Elstar - Wednesday, February 7, 2018 - link
If all you care about is upfront costs, then yes, Intel's high-end parts are expensive. But if you run a data center where "performance/watt" is critical, then the cost of the top parts are reasonable.tamalero - Sunday, February 11, 2018 - link
I'm confused how 4 cores less but 600Mhz less per core on base frequency and all turbo is "better performance per watt" while being almost 1400 USD more per processor.HStewart - Wednesday, February 7, 2018 - link
"Must be nice having a monopoly."Well anybody that states Intel has a monopoly should rethink that, even Apple could be consider a Monopoly because they don't allow others to manufacture products on iOS - but the one that comes to mind the most is Qualcomm with recent announcements of Windows 10 for ARM - which only works on Qualcomm.. Can we say Windows 10 for Qualcomm - sorry no thanks
But the real thing that make Qualcomm a real monopoly is it telecommunications.
prisonerX - Friday, February 9, 2018 - link
I guess you can argue what a monopoly is, but Intel is irrefutably abuses their dominant position in the marketplace. The former is not a sin, the later is illegal. Intel is repugnant.Yorgos - Wednesday, February 7, 2018 - link
"Living on the Edge"Right on.
Will it work? will it get infested due to the various sec. holes? will it get bricked like their C2000 cousins?
You can never tell what's going to come tomorrow when you use intel.
Living on the Edge.
HStewart - Wednesday, February 7, 2018 - link
I think you are trying to referred to Atom bases servers - they have been replace with C3xxx versions like 16 Corehttps://ark.intel.com/products/97927/Intel-Atom-Pr...
But if these new D series Xeons have lower power - I could see them replace C2000 cousins. or this Atom based server
DanNeely - Wednesday, February 7, 2018 - link
Looks like only 14 D2xxx CPUs (in all the tables/charts) not 15 as stated in the section header.