Hot Chips: Intel Knights Mill Live Blog (4:45pm PT, 11:45pm UTC)
by Ian Cutress on August 21, 2017 6:45 PM EST- Posted in
- CPUs
- Intel
- SoCs
- MIC
- Xeon Phi
- Machine Learning
- Knights Mill
- Deep Learning

07:38PM EDT - Another talk from Hot Chips, this time on Intel's Knights Mill (KNM). The Intel Knights family stems from their Xeon Phi product line, although KNM is a bit different, with machine learning specific changes. It's not a completely new Xeon Phi design, but Intel wants to go after the machine learning market. Today's talk will go into some of those changes. (We're battling some wifi here, so pictures may come later).
07:41PM EDT - Still fighting WiFi from this morning, but we're seated and Intel's KNM is the next talk :)
07:42PM EDT - Jesus Corbal to the stage, one of the Primary Architects for KNL and Lead Architect for KNM. Part of the team that created AVX512 extensions
07:43PM EDT - 'Machine Learning' is a wide umbrella
07:43PM EDT - 'We need to put in the smarts to the algorithms'
07:44PM EDT - 'Neural Networks are not new - we learned about them in the 60s'
07:44PM EDT - 'The blessing and the cure is the curated data and self-training'
07:45PM EDT - 'A lot of focus on image recognition'
07:46PM EDT - 'We have solutions, from Xeon to Xeon Phy, to FPGA, to Deep Learning in the Crest Family'

07:46PM EDT - *Phi
07:46PM EDT - 'It's a mix from all-purpose to dedicated acceleration'
07:47PM EDT - 'So why is Xeon Phi, a HPC product, now doing Deep Learning?'
07:47PM EDT - 'Xeon Phi allows scale and configuration'
07:48PM EDT - 'Announcing Knights Mill, building on top of Knights Landing'
07:48PM EDT - 'To be launched in Q4'
07:48PM EDT - '4x Deep Learning perf over Knights Landing'
07:49PM EDT - '4x Deep Learning perf over Knights Landing'
07:49PM EDT - 'Builds directly on top of KNL'
07:49PM EDT - 'It's all about integration of different components'
07:49PM EDT - 'Exploiting a new form of parallelism'
07:49PM EDT - 'We want the cake and eat it too: so we have embedded memory and DDR4'
07:50PM EDT - 16GB of MCDRAM
07:50PM EDT - It's all about the smart location of data for capacity and bandwidth
07:50PM EDT - Support binaries from Broadwell and below
07:50PM EDT - 2-way OoO, 4-way SMT, AVX-512 with VNNI, new Quad FMA

07:51PM EDT - TLP, ILP, DLP and PLP
07:51PM EDT - Quad FMA is new, VNNI is new for KNM
07:52PM EDT - PLP = Pipeline level parallelism via Quad FMA

07:52PM EDT - Based on KNL, up to 6-channel of DDR4, 36 lanes PCIe
07:53PM EDT - Same core config of KNL: 2 cores sharing 1MB of L2, one VPU per core
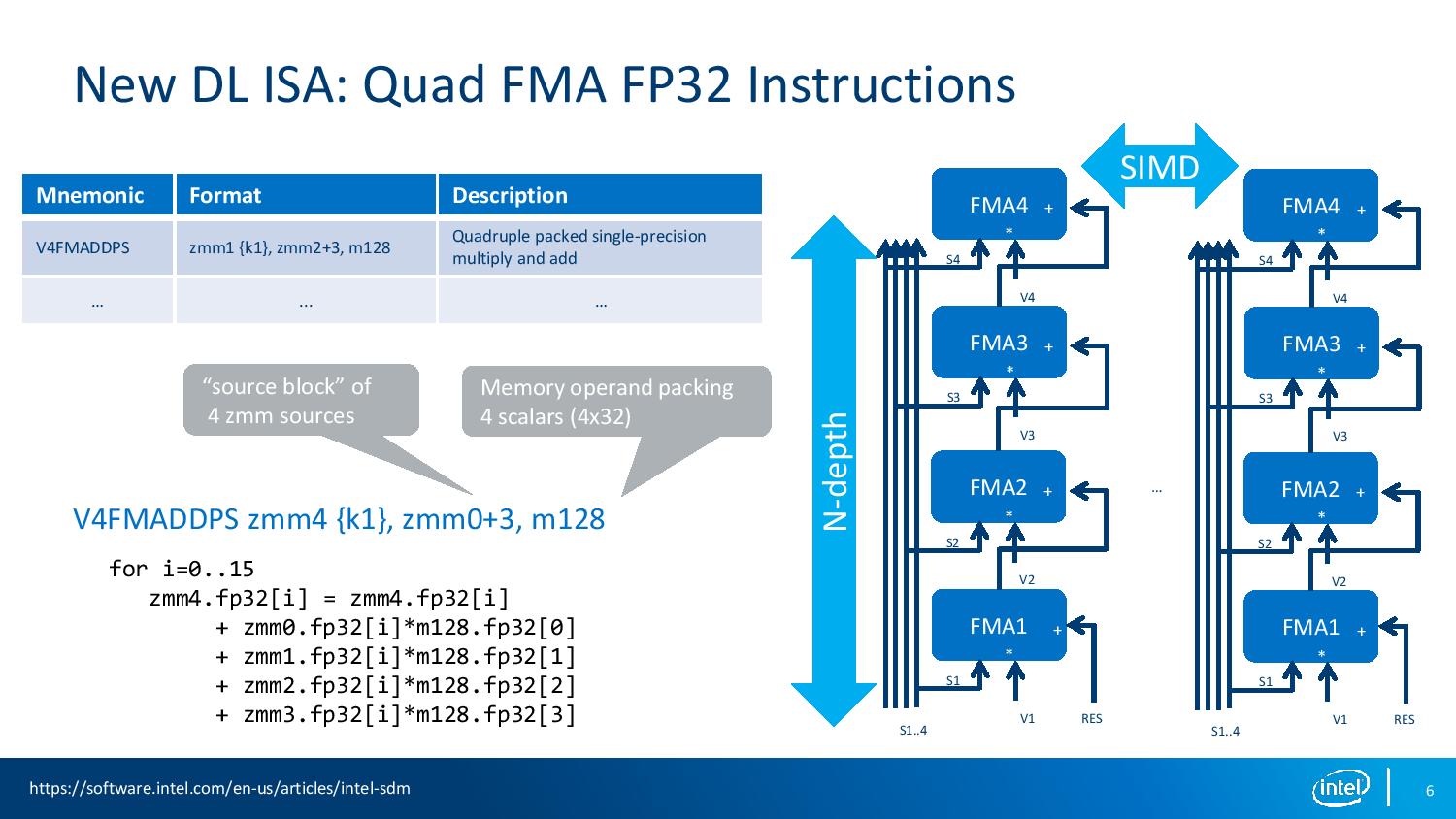
07:54PM EDT - Using the Mesh interconnect
07:54PM EDT - Number of cores withheld for today (although that slide says 36 tiles)
07:54PM EDT - Quad FMA does FMA and funnels into a new FMA while accumulate into new result
07:54PM EDT - Building more FMA entities one after the other vertically
07:55PM EDT - Adds latency, need enough ILP to hide latency
07:55PM EDT - A single target for the vector accumulator
07:55PM EDT - uses source block of 4 zmm sources, memory operand packing of 4 scalars
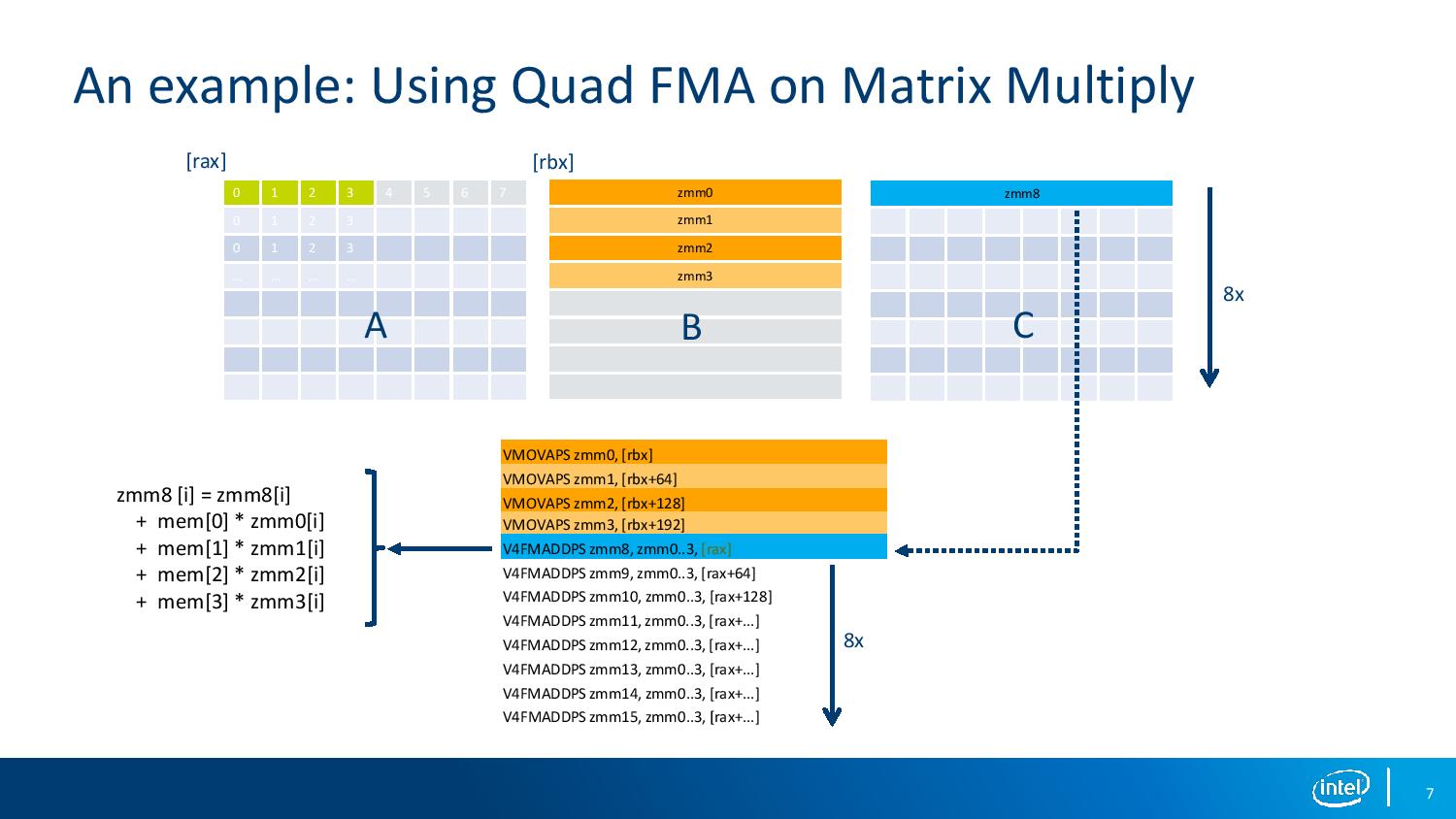
07:57PM EDT - Multiplying A into B to give C
07:57PM EDT - Pack together 12 aligned sources in DRAM to give QFMA
07:58PM EDT - Assuming 3 cycles of latency per FMA
07:58PM EDT - Now VNNI
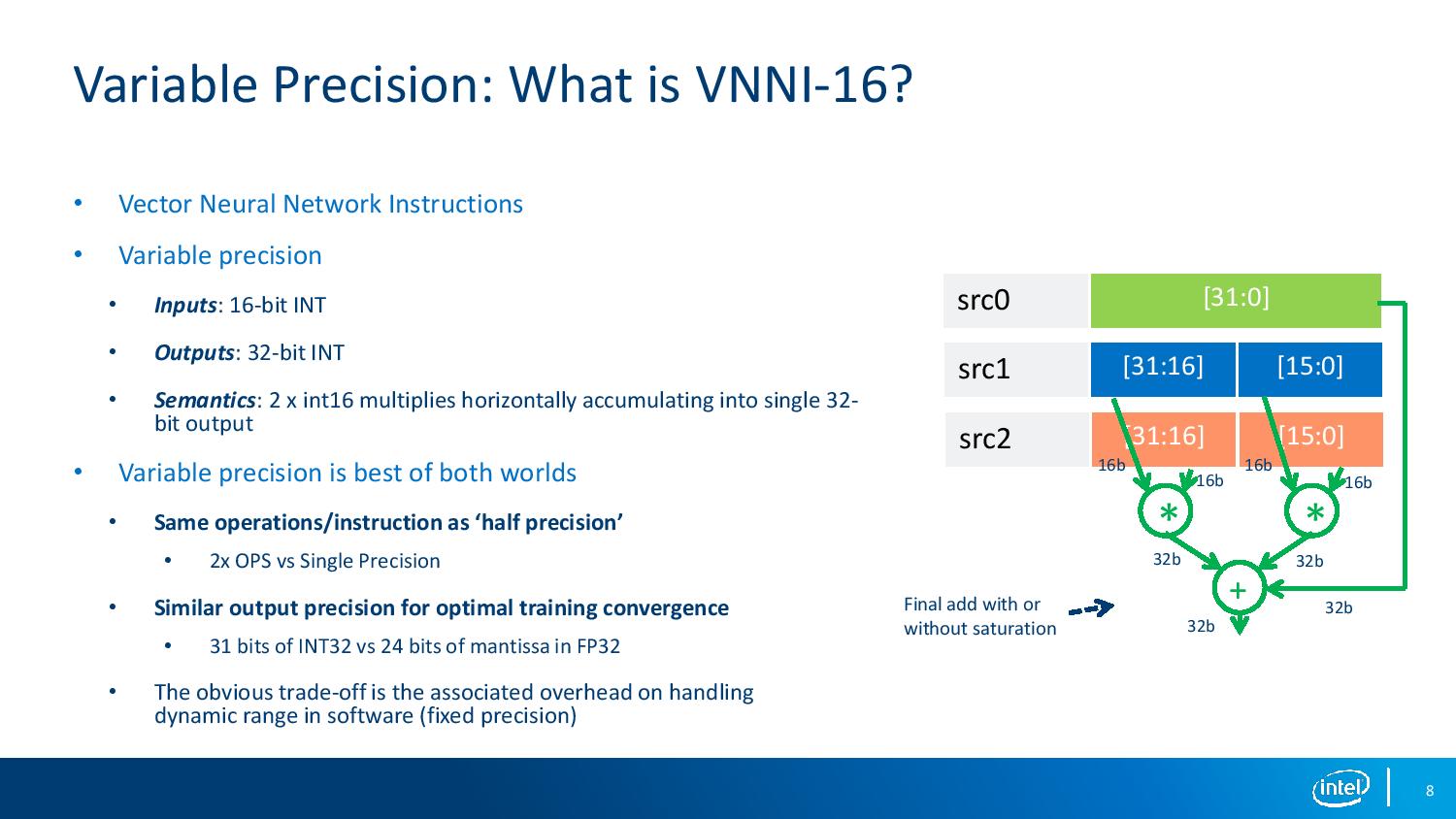
07:58PM EDT - Variable precision via 16-bit INT inputs and 32-bit INT output
07:59PM EDT - Horizontal dot product
07:59PM EDT - Uses 31 bits of INT precision vs 24 bits of Mantissa in FP32
08:01PM EDT - Now for the core - an enhanced KNL, 2way OoO, 4way SMT, 1MB L2, 64-byte / cycle
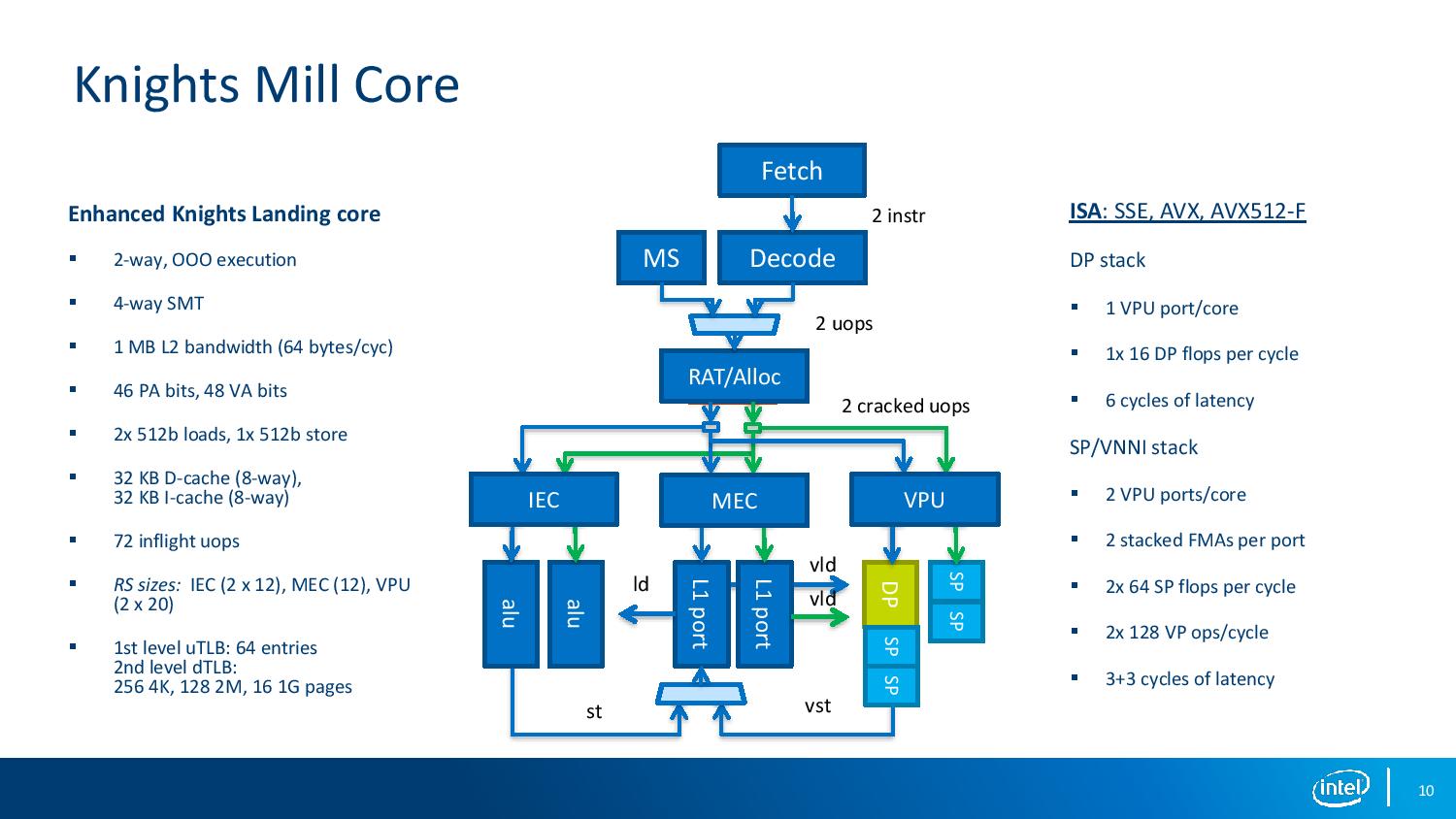
08:03PM EDT - Even though it's 2-way in the front end, it's like 4-way in the back end
08:03PM EDT - We can send the same uop to two clusters - send it to the L/S and the VPU at the same time and is interpreted differently
08:03PM EDT - We can send the same uop to two clusters - send it to the L/S and the VPU at the same time and is interpreted differently
08:04PM EDT - Compensate a narrow front end by packing more operations in a single instruction
08:04PM EDT - In KNL, two units do SP and LP
08:06PM EDT - In KNM, remove one DP ports to give space for four SP VNNI units
08:06PM EDT - So 0.5x DP, 2 x SP, 4x VNNI
08:06PM EDT - Pitching KNM for DL but with tradeoffs, same generation as KNL
08:06PM EDT - KNL to provide time to train and scale up - solve the problem by adding nodes. You can also use it for other things


08:08PM EDT - Now Q&A
08:09PM EDT - 'Why use INT for VNNI rather than FP'
08:10PM EDT - 'FP has failures: it's actually complex to adhere to IEEE and very few advantages. INT is easier and has a similar level of accuracy'
08:11PM EDT - 'Q: Framework performance?'
08:12PM EDT - 'A: we supply libraries, such as MKL, and an open source one called MKL-DNN''
08:13PM EDT - That looks about it. Shame they didn't state cores (even though the slide says 36 tiles), or frequencies.














22 Comments
View All Comments
Drumsticks - Monday, August 21, 2017 - link
I worked on this as an intern before I graduated. Looking forward to this!AndrewJacksonZA - Tuesday, August 22, 2017 - link
Nice!! What and where were you studying?RichUK - Monday, August 21, 2017 - link
1stosteopathic1 - Monday, August 21, 2017 - link
Not 1stMrSpadge - Tuesday, August 22, 2017 - link
I think he meant "1st idiot to post", which seems very true.IntelUser2000 - Monday, August 21, 2017 - link
"Number of cores withheld for today"No they haven't. Maybe they held out for specific SKUs.
Slide 10 says "36 Tiles", and looking at the Tile it has 2 cores. 72 cores. Same as top Knights Landing.
Ian Cutress - Monday, August 21, 2017 - link
Heh, he specifically said on stage 'I'm not disclosing core counts today'. Perhaps the image on the slide is just KNLIntelUser2000 - Monday, August 21, 2017 - link
Perhaps. But I have my doubts. Your page says its a variation of KNL.Could you find out what the "Enhanced" part of Enhanced KNL core is? Because I'm not seeing any differences.
Here's KNL: https://www.extremetech.com/wp-content/uploads/201...
Ian Cutress - Monday, August 21, 2017 - link
Removing the DP from one of the ports, and putting in four VNNI execution units in two pairs. The slide just above the Q&A partIntelUser2000 - Monday, August 21, 2017 - link
Thanks.I get that though. The wording normally suggests the core is somehow better. Guess they mean enhanced for NN, which I think is redundant to say.