Analyzing Falkor’s Microarchitecture: A Deep Dive into Qualcomm’s Centriq 2400 for Windows Server and Linux
by Ian Cutress on August 20, 2017 11:00 AM EST- Posted in
- CPUs
- Qualcomm
- Enterprise
- SoCs
- Enterprise CPUs
- ARMv8
- Centriq
- Centriq 2400
The SoC: 48 Falcor Cores, DDR4, PCIe
Two decades ago, when processors were a single core with external memory controllers, external caches, and external IO, routing was comparatively easier than what we have today. Now we have many core systems, multiple cache levels of different varieties, more IO than we can shake a stick at, and it all has to communicate with each other in a low power, low latency and high bandwidth way using a variety of interfaces. For the Centriq 2400, Qualcomm is implementing a number of enterprise requirements as well as integrating its own developed fabric.
For those that have been following our Intel/AMD coverage of late, we discussed how internal coherent fabrics are changing: Intel has moved from a ring-bus topology to a per-core networking mesh, and AMD uses its scalable Infinity Fabric within a die, between dies, between sockets, and from GPUs to memory. In the mobile space, coherent fabrics like ARMs CCI/CCN are typically all the rage, and ARM allows its partners to modify and tune those IPs as they need to (and most do). Rather than using off-the-shelf IP, Qualcomm has stated that its new interconnect is homegrown.
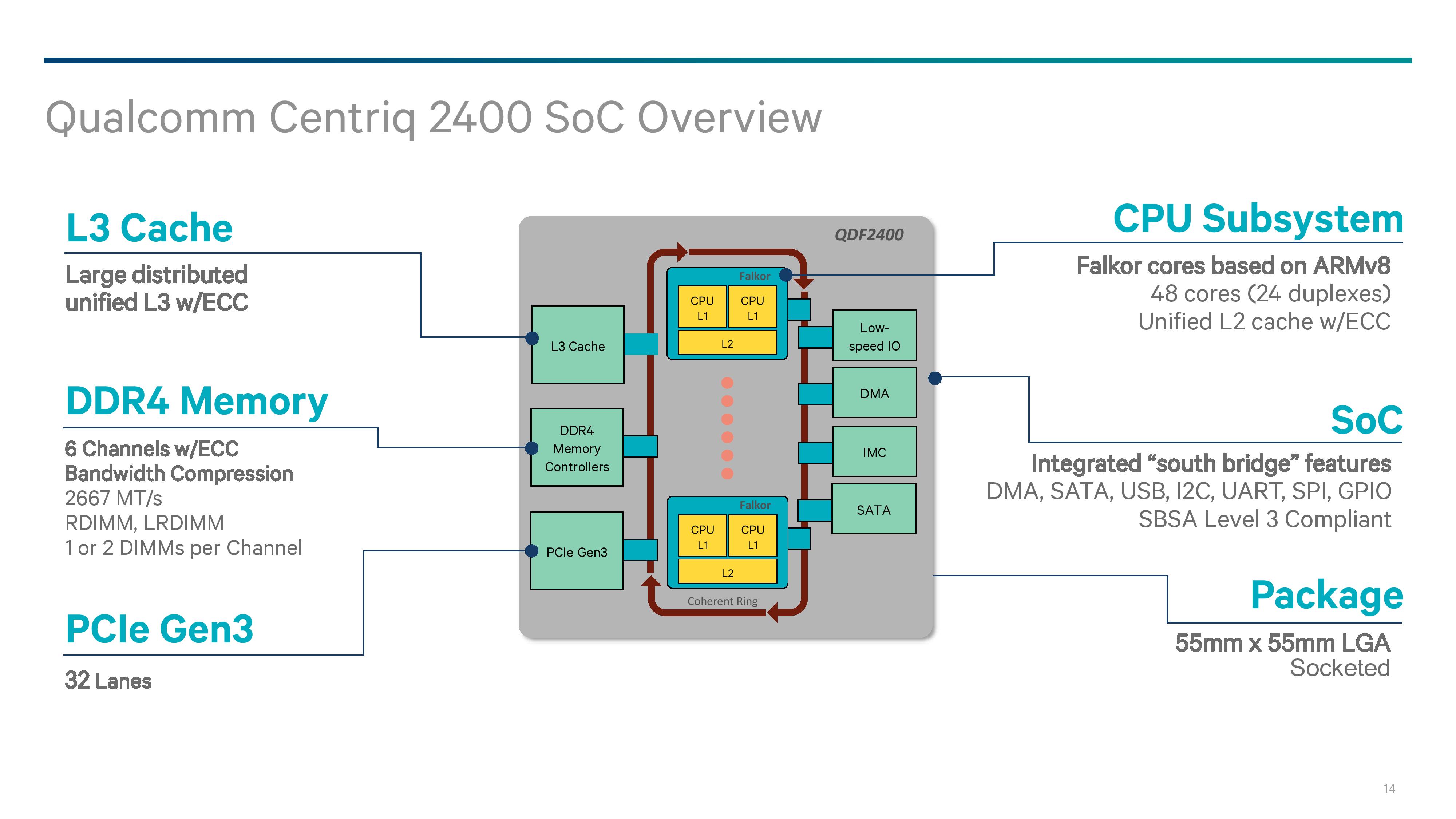
The Qualcomm System Bus (QSB) is a proprietary protocol based, bidirectional segmented ring bus. While Qualcomm shows a ring bus in the image above, we are told that the segmented ring bus might not exactly look like a ring inside the chip – by creating a segmented core-to-core design, it means the cores might not be in a ring at all, with some elements sprouting from off shoots and cores having more than one direction to travel. If Qualcomm were to share a false-color die shot, this would likely be visible. The QSB also allows for multicast on read as well as shortest path routing, which again sounds more like a mesh based networking implementation. Qualcomm quotes a >250GB/s aggregate bandwidth for the QSB.
On the Fabric is everything the system needs: cores, cache, memory, PCIe and IO.
The Centriq family will implement a pair of Falkor cores into a Falkor ‘Duplex’, where each core with have a private L1 cache and a shared L2 cache with ECC. We’ll cover the Falkor design in the next few pages.
For the L3 cache, Qualcomm has not quoted a size but has said that it will scale with the number of cores on the chip. In the above slide it states that it is a distributed unified cache, which can be confusing. Ultimately the cache is fully accessible from all cores, unless a QoS policy is in play, but the cache is likely segmented to allow for the relevant QoS policy tags to bind certain regions to certain cores/VMs. Despite it saying unified, it means that there will be partitions of the L3 around the QSB interconnect. The L3 will be with ECC as well.
Memory controllers are also accessed from the QSB interconnect, with the Centriq 2400 supporting six memory channels of up to DDR4-2667 at up to 2 DIMMs per channel. Support will include RDIMM and LRDIMM, which would suggest up to 1.5TB of LRDIMM support per socket using 128GB LRDIMMs, similar to Intel’s premium memory offerings.
Connectivity comes via 32 lanes of PCIe 3.0, which falls below that offered by Intel (32-44, fewer when chipset level Quick Assist or 10GbE is being used), AMD (128 PCIe in 1P or 2P), X-Gene 3 (42), or Cavium. We probed Qualcomm on features such as NVMe, NVMe RAID, and fall-over support, although in our limited time briefing there was not time to cover it – we might hear more while we are at Hot Chips this week.
Qualcomm has designed the chip as a true SoC such that it doesn’t need a chipset. We’ve confirmed that this is on-die connectivity, rather than via a multi-chip package add-in. The information we have states that the chip will support the usual array of SATA, USB, I2C, UART, GPIO and DMA, although how much of anything has not been stated.








41 Comments
View All Comments
tipoo - Sunday, August 20, 2017 - link
Big ARM server CPUs will be interesting. The ISA is very sane and scalable, if the investment and demand was there it would have no issue getting to where large x86 cores are, the ISA was never the limit.Then we can see if they can actually exceed them.
Kevin G - Sunday, August 20, 2017 - link
This makes me wish that Apple would license their cores to 3rd parties. Recent Apple cores are getting very close to where x86 lies per clock and they've certainly exceeded x86 in performance/watt in the ultra mobile space (granted Intel's last round of ultra mobile chips was flat out cancelled, skewing such a comparison).Considering Apple's work in ultra mobile, I find it believable that a higher performance per clock design in the server space is feasible for an ARM design. A company with enough resources just needs to do it.
iwod - Sunday, August 20, 2017 - link
If the leaked numbers for A11 were true then Apple may have exceeded the performance / clock against Intel x86 as well.While Apple are highly unlikely to ever license their Cores out, I wish they could use those Cores and make an Xserve Server Come back.
peevee - Monday, August 21, 2017 - link
XServe died because of their own OS. Nobody is interested in anything but Linux (and sometimes a little Windows).But they could have sold it with Linux though.
Dr. Swag - Sunday, August 20, 2017 - link
Apple never will though, since it's Apple we're talking about. They keep their tech to themselves to give themselves the advantage.name99 - Sunday, August 20, 2017 - link
The only benchmarks that exist are geekbench4 and the browser benchmarks against Apple laptop hardware. By THOSE benchmarks A9X matched Intel in IPC and A10X exceeds by around 15%.This is clearly an area that draws out the crazies in full screaming mode because a lot of assumptions have to be made (for example the most realistic assumption is that the high-end Intel scores occur at the maximum turbo frequency, but the crazies will insist that, no, you have to normalize to the baseline intel frequency for that particular CPU). Or you get the insistence that the ONLY measurement that matters is against SPEC2006 compiled with icc, which runs into the issues that icc has MASSIVE effects on SPEC; and that no SPEC numbers in any form exist for the A10/A10X.
At the end of the day, it boils down to "what is your goal?" If your goal is an honest comparison of the two processor families, the best data available suggests the summary I gave. If your goal is "my CPU can beat up your CPU" then all the data in the world presumably won't change your mind, and the best data of all is non-existent data (like the certain claims as to how the A10X would or would not behave on SPEC2006).
Final point. It is not at all implausible, IMHO, that Apple have a plan, and have already started proceeding down it, for ARM in their data centers. After all, why not? It saves them money, it allows them to run at their pace not Intel's (eg install AI or compression or encryption accelerators as they need them) and provides better security (both security through obscurity and not having as large an attack surface as Intel).
But why would they talk about it? Apple says nothing ever, unless they have to. No way they would advertise to their competitors the extent to which they have comparative advantage through use of their own data warehouse chips (for at least some purposes).
zodiacfml - Monday, August 21, 2017 - link
Not sa fast. Apple's SoC's are huge in die size which is the reason for their performance. They are as big or bigger than Intel Core. The best part for comparison are the Core M parts. There is little or no business for Apple to do this. There are rumors using Apple SoC on a Macbook Air but that will make little sense as they will to need port OSX to ARM. Again, that is not a good idea as Macbook Pro nor the Mac Pros will continue with OSX .cdillon - Monday, August 21, 2017 - link
Apple has already ported OSX to ARM, and they call it "iOS". It's not going to be as big a deal as you think to get OSX as we know it to run in ARM. Not only that, but they already have experience with juggling two processor architectures (PPC and x86) at the same time in one OS.extide - Monday, August 21, 2017 - link
And 68k to PPC, back in the dayname99 - Monday, August 21, 2017 - link
Apple's SoCs are not huge, neither are their cores.The iPhone SoC's tend to hover around 100 to 120mm^2, the iPad SoCs sometime reach 150, though the A10X is below 100.
The cores are a few mm^2. Eyeballing it, I'd say the entire CPU complex (2 large cores, two small cores, and L2) is about 12mm^2. This is substantially larger than ARM cores (four A73s+their L2 in the same process technology would fit in 8mm^2) but substantially smaller than Intel (an Intel core these days runs at around 8mm^2 in Intels 14nm).