The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTThe Core Complex, Caches, and Fabric
Many core designs often start with an initial low-core-count building block that is repeated across a coherent fabric to generate a large number of cores and the large die. In this case, AMD is using a CPU Complex (CCX) as that building block which consists of four cores and the associated caches.
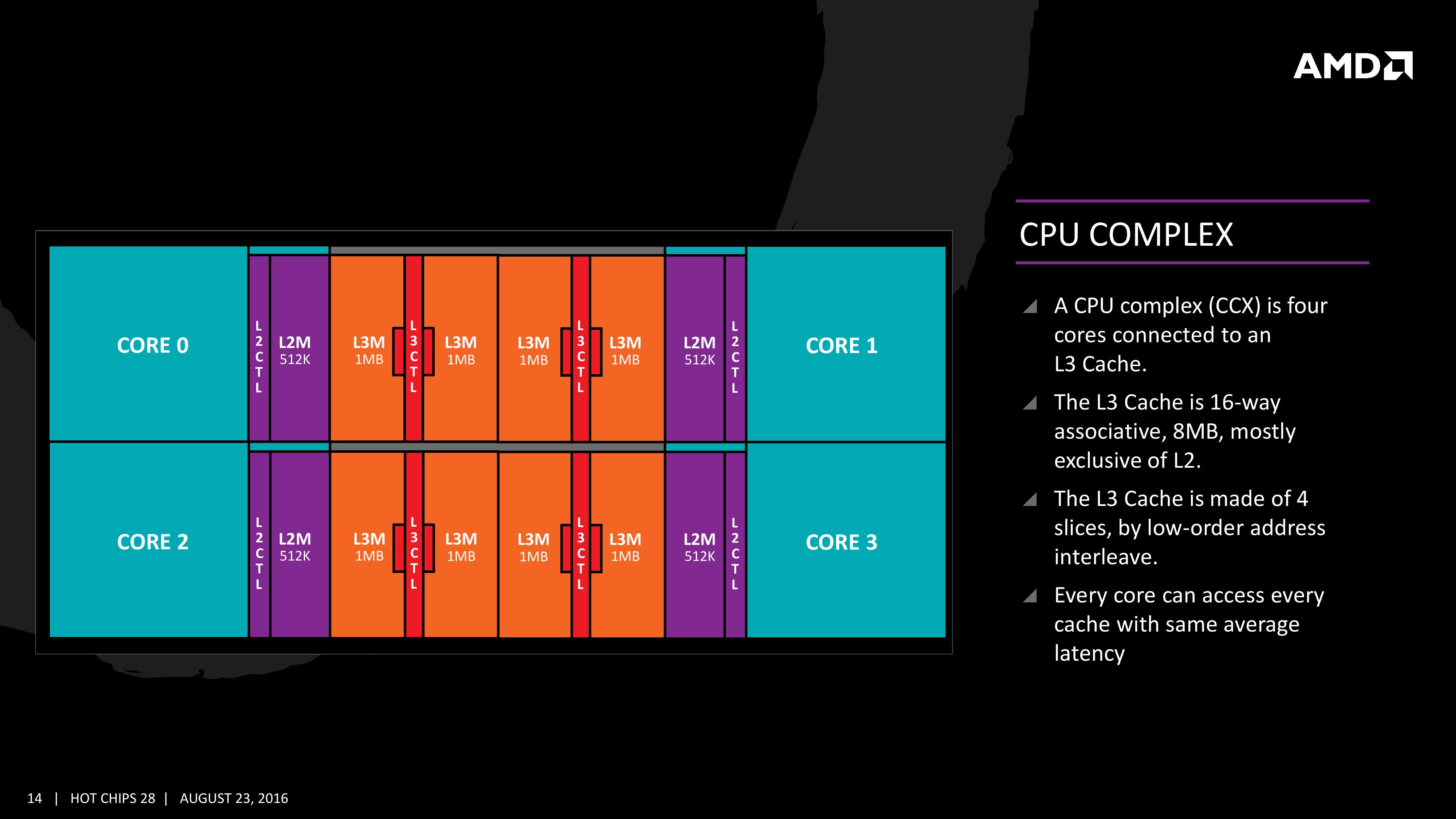
Each core will have direct access to its private L2 cache, and the 8 MB of L3 cache is, despite being split into blocks per core, accessible by every core on the CCX with ‘an average latency’ also L3 hits nearer to the core will have a lower latency due to the low-order address interleave method of address generation.
The L3 cache is actually a victim cache, taking data from L1 and L2 evictions rather than collecting data from prefetch/demand instructions. Victim caches tend to be less effective than inclusive caches, however Zen counters this by having a sufficiency large L2 to compensate. The use of a victim cache means that it does not have to hold L2 data inside, effectively increasing its potential capacity with less data redundancy.
It is worth noting that a single CCX has 8 MB of cache, and as a result the 8-core Zen being displayed by AMD at the current events involves two CPU Complexes. This affords a total of 16 MB of L3 cache, albeit in two distinct parts. This means that the true LLC for the entire chip is actually DRAM, although AMD states that the two CCXes can communicate with each other through the custom fabric which connects both the complexes, the memory controller, the IO, the PCIe lanes etc.
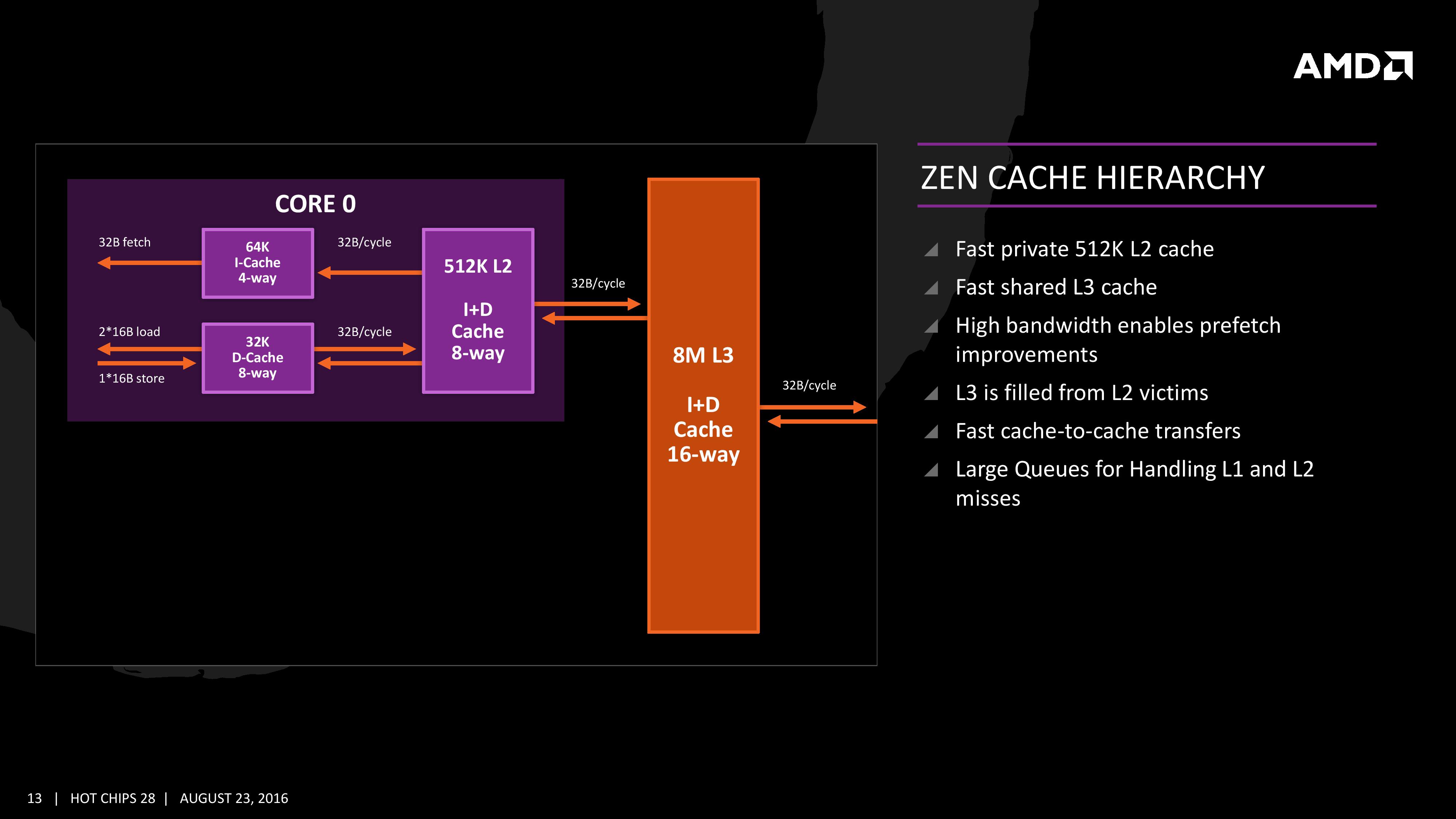
The cache representation shows L1 and L2 being local to each the core, followed by 8MB of L3 split over several cores. AMD states that the L1 and L2 bandwidth is nearly double that of Excavator, with L3 now up to 5x for bandwidth, and that this bandwidth will help drive the improvements made on the prefetch side. AMD also states that there are large queues in play for L1/L2 cache misses.

One interesting story is going to be how AMD’s coherent fabric works. For those that follow mobile phone SoCs, we know fabrics and interconnects such as CCI-400 or the CCN family are optimized to take advantage of core clusters along with the rest of the chip. A number of people have speculated that the fabric used in AMD’s new design is based on HyperTransport, however AMD has confirmed that they are using a superset HyperTransport here for Zen, and that the Infinity fabric design is meant to be high bandwidth, low latency, and be in both Zen and Vega as well as future products. Almost similar to the CPU/GPU roadmaps, the Fabric has its own as well.
Ultimately the new fabric involves a series of control and data passing structures, with the data passing enabling third-party IP in custom designs, a high-performance common bus for large multi-unit (CPU/GPU) structures, and socket to socket communication. The control elements are an extension of power management, enabling parts of the fabric to duty cycle when not in use, security by way of memory management and detection, and test/initialization for activities such as data prefetch.








574 Comments
View All Comments
Crono - Thursday, March 2, 2017 - link
A Hero Has RyzenSweeprshill - Thursday, March 2, 2017 - link
Lived up to the hype. Ryzen is a beast. Intel needs massive price cuts on their 2011-v3 chips. Well done AMD, best price/performance CPUs on the market and as fast or faster than Intel performance.sans - Thursday, March 2, 2017 - link
Hey, what you have found which features improving on AMD's crap has been found in Intel's products for years.Nem35 - Thursday, March 2, 2017 - link
Yeah, and it's beating the Intel. Funny, right?Sweeprshill - Thursday, March 2, 2017 - link
Yeah these new AMD chips are monsters. Wondering how large the price cuts are that Intel will bring to their 2011-v3 chips to compete.czerro - Friday, March 3, 2017 - link
Intel already slashed prices pretty drastically 4 days ago, to kinda deflate Ryzen's release. Before price cuts, Ryzen had a huge price and performance advantage at all metrics, and Intel would have looked ridiculous.I can't believe people aren't reporting the price-cutting right before Ryzen release more. Intel only did it to save face on graphs and confuse people. Ryzen definitely had Intel by the balls a week ago before the price cuts.
It's great that we all have options now, but this really smeared Ryzen's release in a cheap way that anybody can point out all those Intel chips were 100-200 dollars more expensive less than a WEEK ago.
SodaAnt - Saturday, March 4, 2017 - link
No, Intel hasn't slashed prices. There was a sale at microcenter a few days back, but there's no across the board official price cut on Intel chips.Notmyusualid - Monday, March 6, 2017 - link
@ SodaAntAgreed, I see no Intel price drops either.
Notmyusualid - Friday, March 3, 2017 - link
@ Nem35Incomplete review.
After seeing a gaming-focused review, I'd say the AMD procs are just OK. I welcome AMD is back with a fighting chance, but about half my purchase choice will be game-inspired.
Quote:
"For gaming, it’s a hard pass. We absolutely do not recommend the 1800X for gaming-focused users or builds, given i5-level performance at two times the price."
I'm not a 'fanboi', as I'd have no trouble fitting a 1700X in a build I wouldn't game in. But otherwise, like another reviewer said, its a hard pass.
Alexvrb - Saturday, March 4, 2017 - link
For gaming builds the upcoming Ryzen 5 and 3 series will offer a lot more bang for your buck and will compete much more aggressively. However, the Ryzen 7 still offers decent gaming performance and excellent performance everywhere else. The gobs of cores may come in handy in the future too, even in games - as more threads will be available on more rigs, devs will take notice. This year AMD is definitely lowering the pricing for 8-16 thread processors, clearing a path for the future of gaming.With that being said I still think that when strictly considering gaming, their Ryzen 3/5 quadcore models will be a far better value, especially as current-gen games aren't often built in such a way that they can take advantage of the Ryzen 7.