The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700
by Ian Cutress on March 2, 2017 9:00 AM ESTSimultaneous MultiThreading (SMT)
Zen will be AMD’s first foray into a true simultaneous multithreading structure, and certain parts of the core will act differently depending on their implementation. There are many ways to manage threads, particularly to avoid stalls where one thread is blocking another that ends in the system hanging or crashing. The drivers that communicate with the OS also have to make sure they can distinguish between threads running on new cores or when a core is already occupied – to achieve maximum throughput then four threads should be across two cores, but for efficiency where speed isn’t a factor, perhaps power gating/clock gating half the cores in a CCX is a good idea.
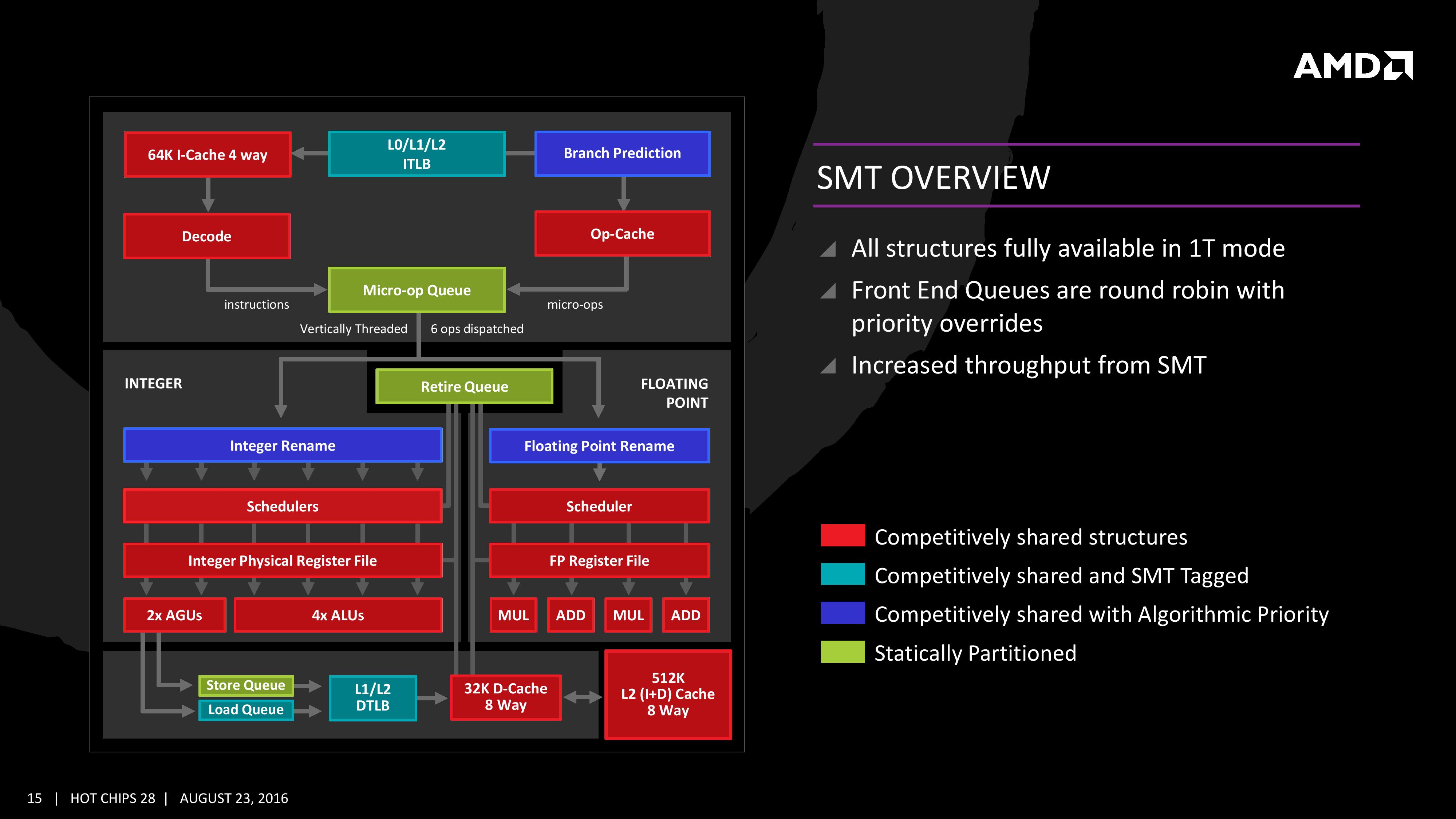
There are a number of ways that AMD will deal with thread management. The basic way is time slicing, and giving each thread an equal share of the pie. This is not always the best policy, especially when you have one performance dominant thread, or one thread that creates a lot of stalls, or a thread where latency is vital. In some methodologies the importance of a thread can be tagged or determined, and this is what we get here, though for some of the structures in the core it has to revert to a basic model.
With each thread, AMD performs internal analysis on the data stream for each to see which thread has algorithmic priority. This means that certain threads will require more resources, or that a branch miss needs to be prioritized to avoid long stall delays. The elements in blue (Branch Prediction, INT/FP Rename) operate on this methodology.
A thread can also be tagged with higher priority. This is important for latency sensitive operations, such as a touch-screen input or immediate user input elements required. The Translation Lookaside Buffers work in this way, to prioritize looking for recent virtual memory address translations. The Load Queue is similarly enabled this way, as typically low latency workloads require data as soon as possible, so the load queue is perfect for this.
Certain parts of the core are statically partitioned, giving each thread an equal timing. This is implemented mostly for anything that is typically processed in-order, such as anything coming out of the micro-op queue, the retire queue and the store queue. However, when running in SMT mode but only with a single thread, the statically partitioned parts of the core can end up as a bottleneck, as they are idle half the time.
The rest of the core is done via competitive scheduling, meaning that if a thread demands more resources it will try to get there first if there is space to do so each cycle.
New Instructions
AMD has a couple of tricks up its sleeve for Zen. Along with including the standard ISA, there are a few new custom instructions that are AMD only.

Some of the new commands are linked with ones that Intel already uses, such as RDSEED for random number generation, or SHA1/SHA256 for cryptography (even with the recent breakthrough in security). The two new instructions are CLZERO and PTE Coalescing.
The first, CLZERO, is aimed to clear a cache line and is more aimed at the data center and HPC crowds. This allows a thread to clear a poisoned cache line atomically (in one cycle) in preparation for zero data structures. It also allows a level of repeatability when the cache line is filled with expected data. CLZERO support will be determined by a CPUID bit.
PTE (Page Table Entry) Coalescing is the ability to combine small 4K page tables into 32K page tables, and is a software transparent implementation. This is useful for reducing the number of entries in the TLBs and the queues, but requires certain criteria of the data to be used within the branch predictor to be met.








574 Comments
View All Comments
Crono - Thursday, March 2, 2017 - link
A Hero Has RyzenSweeprshill - Thursday, March 2, 2017 - link
Lived up to the hype. Ryzen is a beast. Intel needs massive price cuts on their 2011-v3 chips. Well done AMD, best price/performance CPUs on the market and as fast or faster than Intel performance.sans - Thursday, March 2, 2017 - link
Hey, what you have found which features improving on AMD's crap has been found in Intel's products for years.Nem35 - Thursday, March 2, 2017 - link
Yeah, and it's beating the Intel. Funny, right?Sweeprshill - Thursday, March 2, 2017 - link
Yeah these new AMD chips are monsters. Wondering how large the price cuts are that Intel will bring to their 2011-v3 chips to compete.czerro - Friday, March 3, 2017 - link
Intel already slashed prices pretty drastically 4 days ago, to kinda deflate Ryzen's release. Before price cuts, Ryzen had a huge price and performance advantage at all metrics, and Intel would have looked ridiculous.I can't believe people aren't reporting the price-cutting right before Ryzen release more. Intel only did it to save face on graphs and confuse people. Ryzen definitely had Intel by the balls a week ago before the price cuts.
It's great that we all have options now, but this really smeared Ryzen's release in a cheap way that anybody can point out all those Intel chips were 100-200 dollars more expensive less than a WEEK ago.
SodaAnt - Saturday, March 4, 2017 - link
No, Intel hasn't slashed prices. There was a sale at microcenter a few days back, but there's no across the board official price cut on Intel chips.Notmyusualid - Monday, March 6, 2017 - link
@ SodaAntAgreed, I see no Intel price drops either.
Notmyusualid - Friday, March 3, 2017 - link
@ Nem35Incomplete review.
After seeing a gaming-focused review, I'd say the AMD procs are just OK. I welcome AMD is back with a fighting chance, but about half my purchase choice will be game-inspired.
Quote:
"For gaming, it’s a hard pass. We absolutely do not recommend the 1800X for gaming-focused users or builds, given i5-level performance at two times the price."
I'm not a 'fanboi', as I'd have no trouble fitting a 1700X in a build I wouldn't game in. But otherwise, like another reviewer said, its a hard pass.
Alexvrb - Saturday, March 4, 2017 - link
For gaming builds the upcoming Ryzen 5 and 3 series will offer a lot more bang for your buck and will compete much more aggressively. However, the Ryzen 7 still offers decent gaming performance and excellent performance everywhere else. The gobs of cores may come in handy in the future too, even in games - as more threads will be available on more rigs, devs will take notice. This year AMD is definitely lowering the pricing for 8-16 thread processors, clearing a path for the future of gaming.With that being said I still think that when strictly considering gaming, their Ryzen 3/5 quadcore models will be a far better value, especially as current-gen games aren't often built in such a way that they can take advantage of the Ryzen 7.