Investigating Cavium's ThunderX: The First ARM Server SoC With Ambition
by Johan De Gelas on June 15, 2016 8:00 AM EST- Posted in
- SoCs
- IT Computing
- Enterprise
- Enterprise CPUs
- Microserver
- Cavium
Benchmarks Versus Reality
Ever run into the problem that your manager wants a clear and short answer, while the real story has lots of nuances? (ed: and hence AnandTech) The short but inaccurate answer almost always wins. It is human nature to ignore complex stories and to prefer easy to grasp answers. The graph below is a perfect illustration of that. Although this one has been produced by Intel, almost everybody in the industry, including the ARM SoC companies, love the simplicity it affords in describing the competitive situation.
The graph compares the ICC compiled & published results for SPECint_rate_base2006 with some of the claimed (gcc compiled?) results of the ARM server SoC vendors.
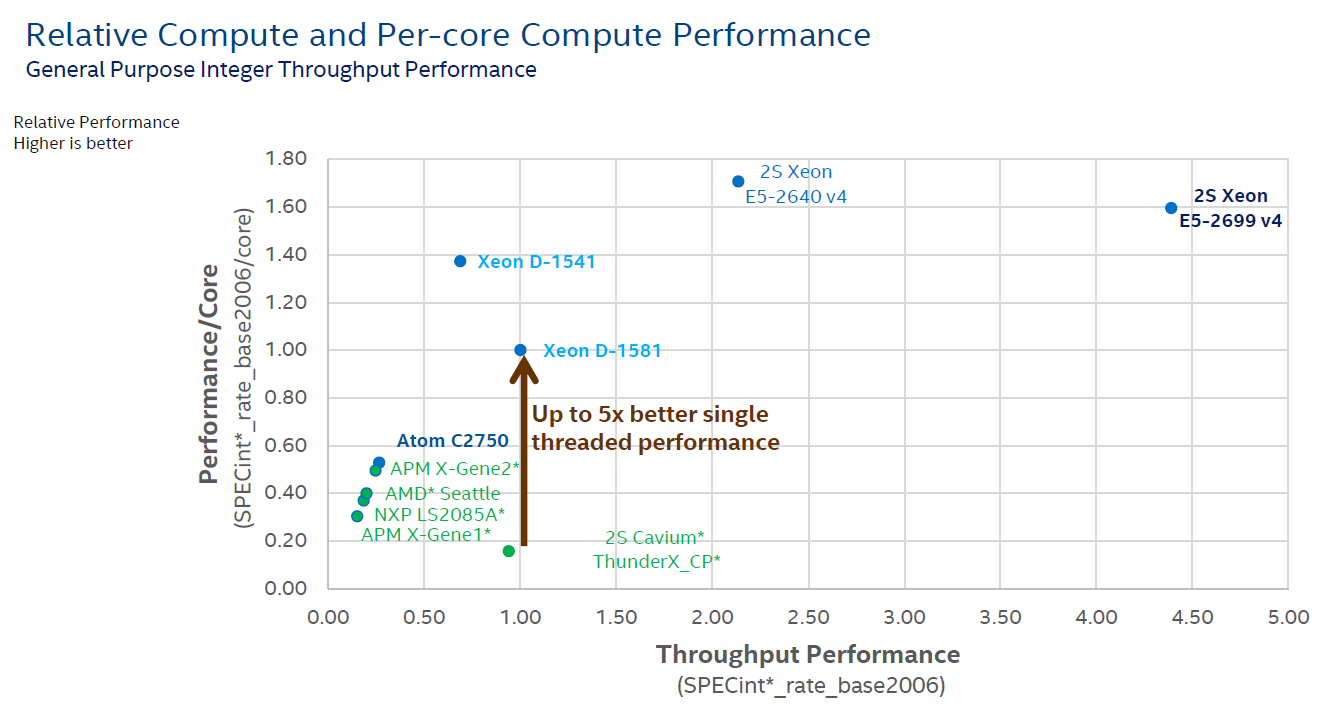
The graph shows two important performance vectors: throughput and single core performance. The former (X-axis) is self-explanatory, the latter (Y-axis) should give an indication of response times (latency). The two combined (x, y coordinate) should give you an idea on how the SoC/CPU performs in most applications that are not perfectly parallel. It is a very elegant way to give a short and crystal clear answer to anyone with a technical or scientific background.
But there are many drawbacks. The main problem is "single core performance". Since this is just diving the score by the number of cores, this favors the CPUs with some form of hardware multi-threading. But in many cases, the extra threads only help with throughput and not with latency. For example, if there are a few heavy SQL requests that keep you waiting, adding threads to a core does not help at all, on the contrary. So the graph above gives a 20% advantage to the SMT capable cores of Intel on y-axis, while hyperthreading is most of the time a feature that boosts throughput.
Secondly, dividing throughput by the number of cores means also that you favor the architectures that are able to run many instances of SPECint. In other words, it is all about memory bandwidth and cache size. So if a CPU does not scale well, the graph will show a lower per core performance. So basically this kind of graph creates the illusion of showing two performance parameters (throughput and latency), but it is in fact showing throughput and something that is more related to throughput (throughput normalized per core?) than latency. And of course, SPECint_rate is only a very inaccurate proxy for server compute performance: IPC is higher than in most server applications and there is too much emphasis on cache size and memory bandwidth. Running 32 parallel instances of an application is totally different from running one application with 32 threads.
This is definitely not written to defend or attack any vendor: many vendors publish and abuse these kind of graphs to make their point. Our point is that it is very likely that this kind of graph gives you a very inaccurate and incomplete view of the competition.
But as the saying goes, the proof is in the pudding, so let's put together a framework for comparing these high level overviews with real world testing. First step, let's pretend the graph above is accurate. So the Cavium ThunderX has absolutely terrible single threaded performance: one-fifth that of the best Xeon D, not even close to any of the other ARM SoCs. A ThunderX core cannot even deliver half the performance of an ARM Cortex-A57 core (+/- 10 points per core), which is worse than the humble Cortex-A53. It does not get any better: the throughput of a single ThunderX SoC is less than half of the Xeon D-1581. The single threaded performance of the Xeon D-1581 is only 57% of the Xeon E5-2640's and it cannot compete with the throughput of even a single Xeon E5-2640 (2S = 2.2 times the Xeon-D 1581).
Second step, do some testing instead of believing vendor claims or published results from SPEC CPU2006. Third step, compare the graph above with our test results...








82 Comments
View All Comments
Spunjji - Wednesday, June 15, 2016 - link
Well, this is certainly promising. Absent AMD, Intel need some healthy competition in this market - even if it is in something of a niche area.niva - Wednesday, June 15, 2016 - link
This is the area where profits are made, not "something of a niche area."Shadow7037932 - Wednesday, June 15, 2016 - link
Yeah, I mean getting some big customers like Facebook or Google would be rather profitable I'd imagine.JohanAnandtech - Thursday, June 16, 2016 - link
More than 30% of Intel's revenue, and the most profitable area for years, and for years to come...prisonerX - Wednesday, June 15, 2016 - link
This is the future. Single thread performance has reached a dead end and parallelism is the only way forward. Intel's legacy architecture is a millstone around its neck. ARM's open model and efficient implementation will deliver more cores and more performance as software adapts.The monopolists monopolise themselves into irrelevance yet again.
CajunArson - Wednesday, June 15, 2016 - link
" Intel's legacy architecture is a millstone around its neck."I wouldn't call those Xeon-D parts putting up excellent performance at lower prices and vastly lower power consumption levels to be any kind of "millstone".
"ARM's open model and efficient implementation "
What's "open" about these Cavium chips exactly? They can only run a few specialized Linux flavors that don't even have the full range of standard PC software available to them.
What is efficient about a brand-new ARM chip from 2016 losing at performance per watt to the 4.5 year old Sandy Bridge parts that you were insulting?
As for monopolies, ARM has monopolized the mobile market and brought us "open" ecosystems like the iPhone walled-garden and Android devices that literally never receive security updates. I'd take a plain x86 PC that I can slap Linux on any day of the week over the true monopoly that ARM has over locked-down smartphones.
shelbystripes - Wednesday, June 15, 2016 - link
You're right to criticize the "millstone" comment, Intel has done quite well achieving both high performance and high performance-per-watt in their server designs.But your comment about a "true monopoly" in the "locked-down smartphone" market is ridiculous. The openness (or lack thereof) that you're complaining about has nothing to do with the CPU architecture at all. An x86 smartphone or tablet can just as easily be locked down, and they are. I own a Dell Venue 8 7000, which is an Android tablet with an Intel Atom SoC inside. It's a great tablet with great hardware. But it's got a bunch of uninstallable crapware installed, Dell abandoned it after 5.1 (it's ridiculous that a tablet with a quad-core 2GHz SoC and 2GB RAM will never see Marshmallow), and the locked smartphone-esque bootloader means I can't repurpose it to a Linux distro even if one existed that supported all the hardware inside this thing.
On the flipside, the most popular open-source learning/development solution out there right now is the ARM-based Raspberry Pi. There are a number of Linux distros available for it, and everything is OSS, even the GPU driver.
TheLightbringer - Thursday, June 16, 2016 - link
You haven't done your homework.Some mobile devices were coming with Intel. But like Microsoft it entered the market too late, without offering any real value. The phrase "Too little, too late" fit them both.
ARM didn't do a monopoly. They just simply saw an opportunity and embrace it. In the early IBM clone days Intel licensed their architecture to allow competition and broad arrange of products. After the market was won, they went greedy, didn't licensed the architecture anymore and cut a lot of players out, leaving a need for a chip licensing scheme. And that's where ARM got in.
Google develops Android OS, but is up to phone vendors and carriers to deploy them. And they don't want to for economic reasons. They prefer to sell you a new phone for $$$.
Intel and MS got in the mobile/car market exactly what they deserve, nothing else.
junky77 - Friday, June 17, 2016 - link
they all greedy. Some just play it smartly or have more luck in decision makingBut, yea, when you read about the way IBM behaved when things were fresh - it's quite amazing. They had much of the market and could do a lot of stuff, but they simply had a very narrow mind set
soaringrocks - Wednesday, June 15, 2016 - link
You make it sound like it's mostly a SW problem, I think it's more complex than that. Actual performance is very dependent on the types of workload and some tasks fit Intel CPUs nicely and the performance per watt for ARM is lacking despite the hype of that architecture being uniquely qualified for low-power. It will be fun to watch how the battle evolves though.