The IBM POWER8 Review: Challenging the Intel Xeon
by Johan De Gelas on November 6, 2015 8:00 AM EST- Posted in
- IT Computing
- CPUs
- Enterprise
- Enterprise CPUs
- IBM
- POWER
- POWER8
Inside the S822L: Hardware Components
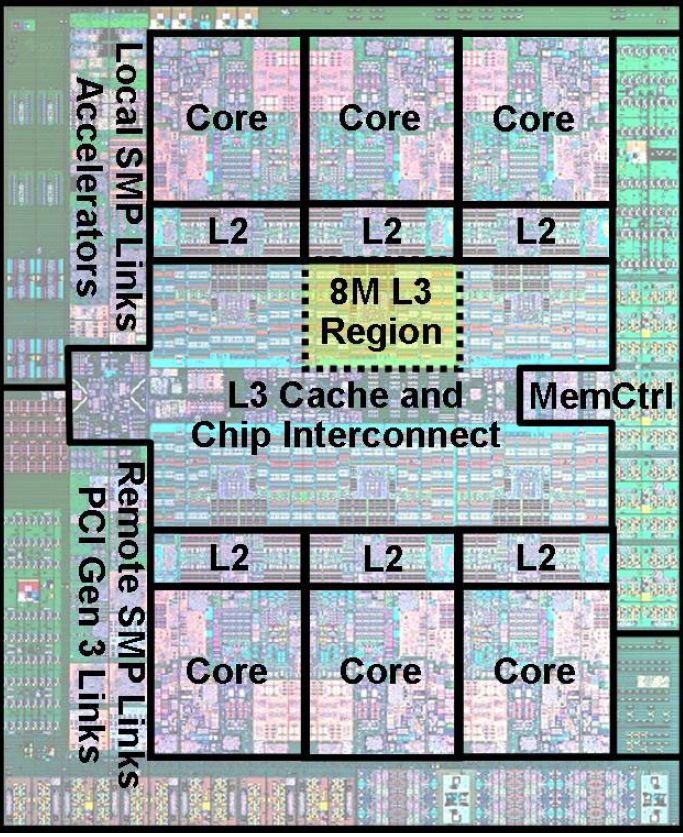
The 2U Rack-mount S822L server contains two IBM POWER8 DCM sockets. Each socket thus contains two cores connected by a 32GBps interconnect. The reason for using a Multi-Chip-Module (MCM) is pretty simple. Smaller five-to-six core dies are a lot cheaper to produce than the massive 650 mm² monolithic 12-core dies. As a result the latter are reserved for IBM's high-end (E880 and a like). So while most POWER8 presentations and news posts on the net talk about the multi-core die below...

... it is actually an MCM with two six core dies like the one below that is challenging the 10 to 18 core Xeons. The massive monolithic 10-12 core dies are in fact reserved for much more expensive IBM servers.
The layout of the S822L is well illustrated by the scheme inside the manual.
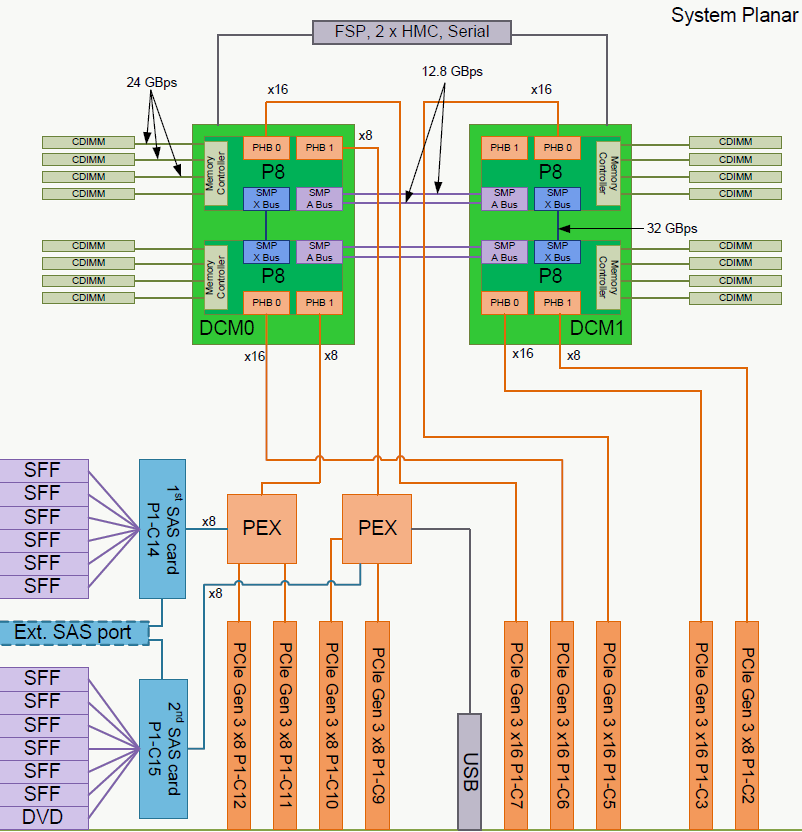
Each DCM offers 48 PCIe Gen 3 lanes. 32 of those lanes are directly connected to the processor while 16 connect to PCIe switches. The PCIe switches have "only" 8 lanes upstream to the DCM, but offer 24 lanes to "medium" speed devices downstream. As it unlikely that both your SAS controllers and your network controllers will gobble up the full PCIe x8 bandwidth, this is a very elegant way to offer additional PCIe lanes.








146 Comments
View All Comments
usernametaken76 - Thursday, November 12, 2015 - link
Technically this is not true. IBM had a working version of AIX running on PS/2 systems as late as the 1.3 release. Unfortunately support was withdrawn and future releases of AIX were not compiled for x86 compatible processors. One can still find a copy of this release if one knows where to look. It's completely useless to anyone but a museum or curious hobbyist, but it's out there.zenip - Friday, November 13, 2015 - link
...>--click here-Steven Perron - Monday, November 23, 2015 - link
Hello Johan,I was reading this article, and I found it interesting. Since I am a developer for the IBM XL compiler, the comparisons between GCC and XL were particularly interesting. I tried to reproduce the results you are seeing for the LZMA benchmark. My results were similar, but not exactly the same.
When I compared GCC 4.9.1 (I know a slightly different version that you) to XL 13.1.2 (I assume this is the version you used), I saw XL consistently ahead of GCC, even when I used -O3 for both compilers.
I'm still interested in trying to reproduce your results, so I can see what XL can do better, so I have a couple questions on areas that could be different.
1) What version of the XL compiler did you use? I assumed 13.1.2, but it is worth double checking.
2) Which version of the 7-zip software did you use? I picked up p7zip 15.09.
3) Also, I noticed when the Power 8 machine was running at full capacity (for me that was 192 threads on a 24 core machine), the results would fluctuate a bit. How many runs did you do for each configuration? Were the results stable?
4) Did you try XL at the less aggressive and more stable options like "-O3" or "-O3 -qhot"?
Thanks for you time.
Toyevo - Wednesday, November 25, 2015 - link
Other than the ridiculous price of CDIMMs the power efficiency just doesn't look healthy. For data centers leasing their hardware like Amazon AWS, Google AppEngine, Azure, Rackspace, etc, clients who pay for hardware yet fail to use their allocation significantly help the bottom line of those companies by reduced overheads. For others high usage is a mandatory part of the ROI equation during its period as an operating asset, thus power consumption is a real cost. Even with our small cluster of 12 nodes the power efficiency is a real consideration, let alone companies standardizing toward IBM and utilising 100s or 1000s of nodes that are arguably less efficient.Perhaps you could devise some sort of theoretical total cost of ownership breakdown for these articles. My biggest question after all of this is, which one gets the most work done with the lowest overheads. Don't get me wrong though, I commend you and AnandTech on the detail you already provide.
AstroGuardian - Tuesday, December 8, 2015 - link
It's good to have someone challenging Intel, since AMD crap their pants on regular basisdba - Monday, July 25, 2016 - link
Dear Johan:Can you extrapolate how much faster the Sparc S7 will be in your Cluster Benchmarking,
if the 2 on Die Infiniband ports are Activated, 5, 10, 20% ???
Thank You, dennis b.