The AMD Radeon R9 Fury X Review: Aiming For the Top
by Ryan Smith on July 2, 2015 11:15 AM ESTHigh Bandwidth Memory: Wide & Slow Makes It Fast
Architecturally, the single most notable addition to AMD’s collection of technologies for Fiji is High Bandwidth Memory (HBM). HBM is a next-generation memory standard that will ultimately come to many (if not all) GPUs as the successor to GDDR5. HBM promises a significant increase in memory bandwidth through the use of an ultra-wide, relatively low-clocked memory bus, with die stacked DRAM used to efficiently place the many DRAM dies needed to drive the wide bus.
As part of their pre-Fury X launch activities, AMD briefed the press on HBM back in May, offering virtually every detail one could want on HBM, how it worked, and the benefits of the technology. So for today’s launch there’s relatively little that’s new to say on the subject, but I wanted to quickly recap what we have seen so far.
After several years of GDDR5 – first used on the Radeon HD 4870 in 2008 – HBM comes at a time where GDDR5 is reaching its limits, and companies have been working on its successors. As awesome as GDDR5 is (and it delivers quite a bit of memory bandwidth compared to just about anything else), GDDR5 is already a bit of a power hog and rather complex to implement. GDDR5’s immediate successors would deliver more bandwidth, but they would also exacerbate this problem by drawing even more power and introducing all of the complexity inherent in differential I/O.

So to succeed GDDR5, AMD, Hynix, and the JEDEC as a whole have taken a very different path. Rather than attempting to push a very high bandwidth, narrow(ish) memory bus standard even higher, they have opted to go in the opposite direction with HBM. HBM would significantly back off of the clockspeeds used, but in return it would go wider than GDDR5. Much, much wider.
The ultimate direction that HBM takes us is with a very wide memory bus clocked at a low frequency. For Fiji, AMD has a 4096-bit memory bus clocked at 1000MHz (500MHz DDR). The use of such a wide bus more than offsets the reduction in clockspeed, allowing R9 Fury X to deliver 60% more memory bandwidth than the R9 290X’s GDDR5 implementation.

On the technical side of things, creating HBM has required a few different technologies to be created/improved in order to assemble the final product. The memory bus itself is rather simple (which is in and of itself a benefit), but a 4096-bit wide memory bus is by conventional standards absurdly wide. It requires thousands of contacts and traces, many times more than even 512-bit GDDR5 required (and that was already a lot).
To solve this problem HBM introduces the concept of a silicon interposer. With traditional packaging not up to the challenge of routing so many traces, the one material/package that is capable of hitting the necessary density is fabbed silicon, and thus the silicon interposer. Essentially a partially fabbed chip with just the metal layers but no logic, the interposer is a large chip whose purpose is to allow the ultra-wide 4096-bit memory bus to be created between a GPU and its VRAM, implemented as traces in the metal layers. The interposer itself is not especially complex, however because of the sheer size of the interposer (it needs to be large enough to hold the GPU and VRAM) the interposer brings with it its own challenges.
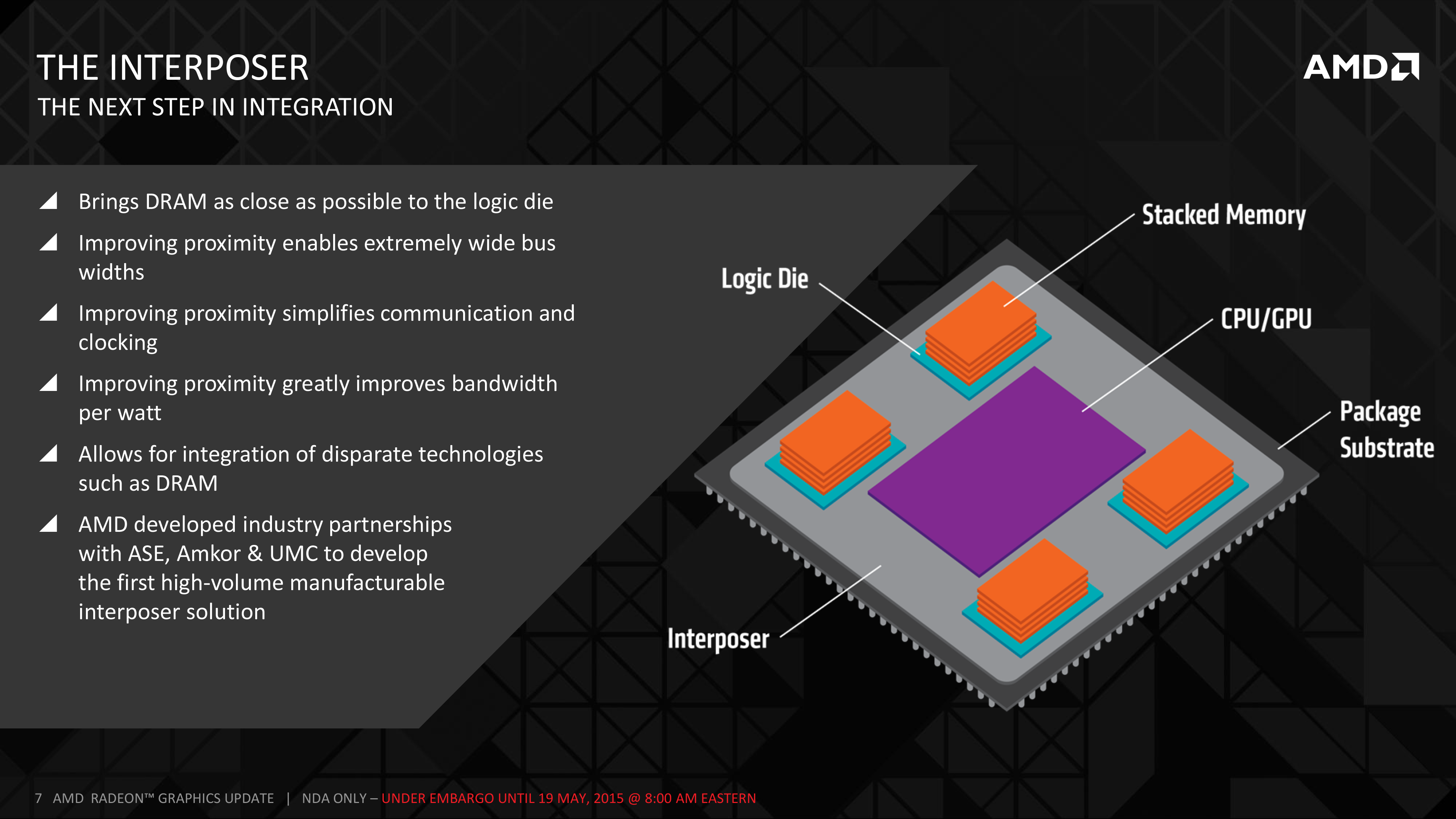
Meanwhile even though the interposer solves the immediate challenges of implementing a 4096-bit memory bus, the next issue that crops up is where to put the necessary DRAM dies. It takes 16 dies at 256-bits wide each to create the 4096-bit memory bus, and even at its largest size the interposer is still a fraction of the size of the PCB space that traditional GDDR5 chips occupy. As a result the DRAM required for an HBM solution needed to be denser than ever before in a 2D sense.
The solution to that problem was the creation of die-stacking the DRAM. If you can’t go wider, go taller, which is exactly what has happened with HBM. In HBM1 the stacks can go up to 4 dies high, allowing the necessary 16 dies to be reduced to a far more easily managed 4 stacks. With a base logic die at the bottom of each stack to serve as the PHY between the DRAM and the GPU (technically making the complete stack 5 dies), stacking the DRAM is what makes it practical to put so much RAM so close to the GPU.
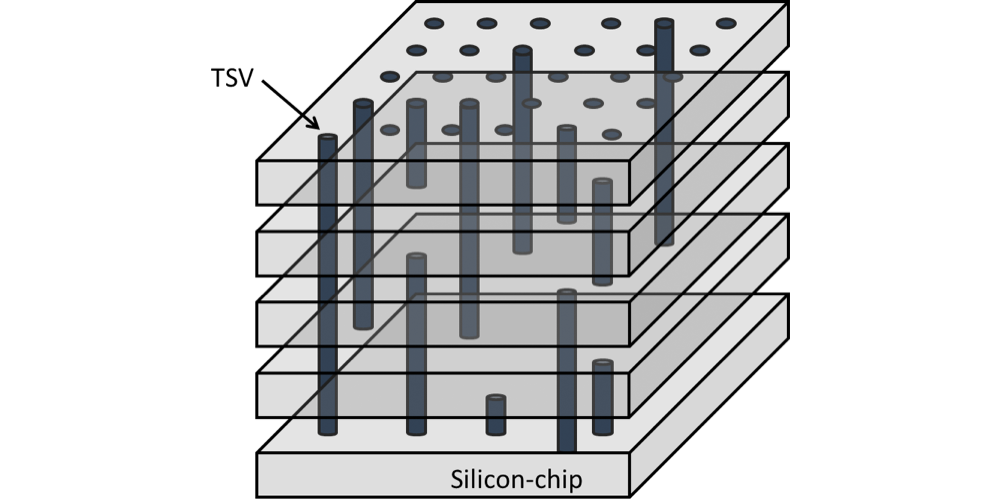
The final new piece of technology in HBM comes in the die stacks themselves. With the need to route a 1024-bit memory bus through 4 memory dies, traditional package-on-package wire bonding is no longer sufficient. To connect up the memory dies, much like the interposer itself, a newer, denser connectivity method is required.
TSVs. Image Courtesy The International Center for Materials Nanoarchitectonics
To solve that problem, the HBM memory stacks implement Through-Silicon Vias, which involves running the vias straight through silicon devices in order to connect layers. The end result is something vaguely akin to DRAM dies surface mounted on top of each other via microbumps, but with the ability to communicate through the layers. From a manufacturing standpoint, between the silicon interposer and TSVs, TSVs are the more difficult technology to master as it essentially combines all the challenges of DRAM fabbing with the challenges of stacking those DRAM dies on top of each other.
Combined together as a single product, HBM is the next generation of GPU memory technology thanks to the fact that it offers multiple benefits over GDDR5. Memory bandwidth of course is a big part, but of similar significance is the power savings from HBM. The greatly simplified memory bus requires far less power be spent on the bus itself, and as a result the amount of power spent on VRAM is reduced. As we discussed earlier AMD is looking at a 20-30W VRAM power savings on R9 Fury X over R9 290X.
The third major benefit of HBM over GDDR5 goes back to the size benefits discussed earlier. Because all of the VRAM in an HBM setup fits on-chip, this frees up a significant amount of space. The R9 Fury X PCB is 3” shorter than the R9 290X PCB, and the bulk of these savings come from the space savings enjoyed by using HBM. Along with the immediate space savings of 4 small HBM stacks as opposed to 16 GDDR5 memory chips, AMD also gets to cut down on the amount of power delivery circuitry needed to support the VRAM, further saving space and some bill of material costs in the process.
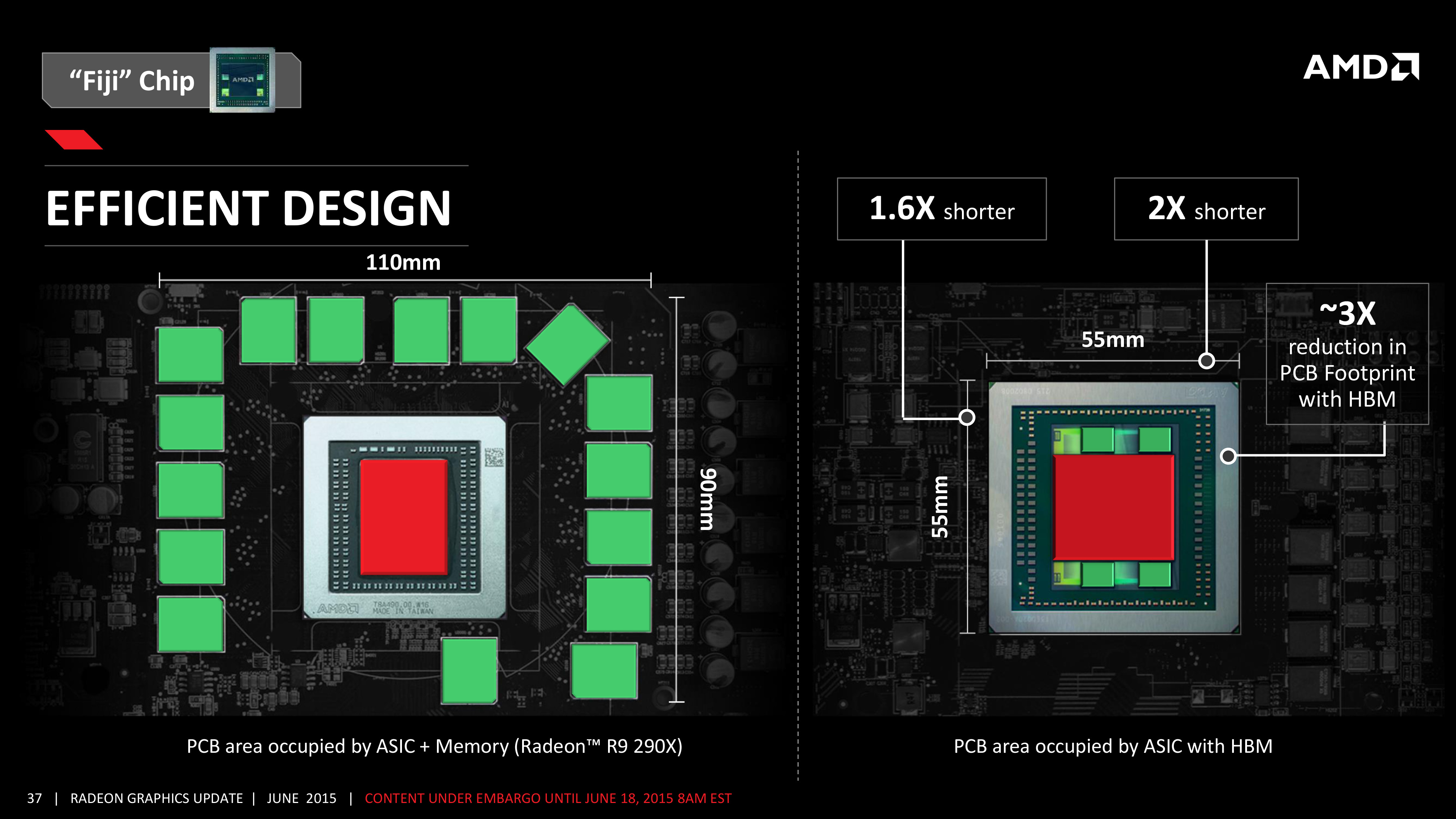
On the downside though, it is the bill of materials that is the biggest question hanging over HBM. Since HBM introduces several new technologies there are any number of things that can go wrong, all of which can drive up the costs. Of particular concern is the yield on the HBM memory stacks, as the TSV technology is especially intricate and said to be difficult to master. The interposer on the other hand is simpler, but it still represents something that has never been done before, and AMD admits upfront that the manufacturing facilities being used to create the interposer are old 65nm lines originally used for full chip production. So while the interposer does not approach the cost of a full logic chip, there is still the matter of the existing manufacturing lines being sub-optimal for high-volume low-cost production. Meanwhile AMD does get to enjoy some cost savings as well – the HBM PHYs are certainly much easier to implement than GDDR5 PHYs on Fiji itself, and the overall package is cheaper since it doesn't have GDDR5 memory running through it – though it's unlikely that these savings outweigh the other costs of implementing HBM at this time.
Ultimately AMD Is not willing to discuss HBM costs or yields at this time. Practically speaking it’s not a consumer matter – what matters to video card buyers is the $650 price tag on the R9 Fury X – and from a trade secrets perspective AMD is loath to share too much about what they have learned since they are the first HBM customer and want to enjoy as much of that advantage as is possible. At this point I feel it’s a safe bet that the 4GB HBM implementation on Fiji is costing AMD more than the 4GB (or even 8GB) GDDR5 implementations on Hawaii cards, but beyond that it’s difficult to say much more on costs.
That said, regardless of what the costs are now, HBM will be the future for AMD, and for the GPU industry as a whole. NVIDIA has already committed to using HBM technology for their high-end Pascal GPU in 2016, so AMD will be joined by other parties next year. Meanwhile AMD has much grander plans for HBM, intending to bring it to other products as costs allow. HBM on lower-priced GPUs is practically a given, meanwhile equipping AMD’s APUs with HBM would solve one of the greatest problems AMD faces today on the iGPU performance front, which is that 128-bit DDR3 bottlenecks the iGPU on their Kaveri APUs. AMD could build a better iGPU, if only they had more bandwidth to feed it with. This is a problem HBM is well positioned to solve.
Finally, at the end of the day what can’t be perfectly captured in words is AMD’s pride in being the first to roll out HBM. AMD was the first (and only) company to support GDDR4, they were the first company to support GDDR5, and now they are the first company to support HBM. The company has put significant resources into helping to develop the technology alongside Hynix, UMC, ASE, Amkor, and the JEDEC, and they see the launch of the technology as a testament to their engineering capabilities.
Furthermore they also see the fact that they are first as being a significant advantage going forward, as it means they have a generational advantage on arch-rival NVIDIA in implementing the technology. Case in point, NVIDIA’s first GDDR5 memory controller was by all accounts an underperformer, and it wasn’t until their second generation GDDR5 controller for Kepler that NVIDIA was able to hit (and even exceed) their aimed for memory clockspeeds. Admittedly this comes down to AMD hoping NVIDIA is going to stumble here, but at the end of the day the company is optimistic that all of their work is going to allow them to get more out of HBM than NVIDIA will be able to.








458 Comments
View All Comments
chizow - Sunday, July 5, 2015 - link
@piiman - I guess we'll see soon enough, I'm confident it won't make any difference given GPU prices have gone up and up anyways. If anything we may see price stabilization as we've seen in the CPU industry.medi03 - Sunday, July 5, 2015 - link
Another portion of bulshit from nVidia troll.AMD never ever had more than 25% of CPU share. Doom to Intel, my ass.
Even in Prescott times Intell was selling more CPUs and for higher price.
chizow - Monday, July 6, 2015 - link
@medi03 AMD was up to 30% a few times and they did certainly have performance leadership at the time of K8 but of course they wanted to charge anyone for the privilege. Higher price? No, $450 for entry level Athlon 64, much more than what they charged in the past and certainly much more than Intel was charging at the time going up to $1500 on the high end with their FX chips.Samus - Monday, July 6, 2015 - link
Best interest? Broken up for scraps? You do realize how important AMD is to people who are Intel\NVidia fans right?Without AMD, Intel and NVidia are unchallenged, and we'll be back to paying $250 for a low-end video card and $300 for a mid-range CPU. There would be no GTX 750's or Pentium G3258's in the <$100 tier.
chizow - Monday, July 6, 2015 - link
@Samus, they're irrelevant in the CPU market and have been for years, and yet amazingly, prices are as low as ever since Intel began dominating AMD in performance when they launched Core 2. Since then I've upgraded 5x and have not paid more than $300 for a high-end Intel CPU. How does this happen without competition from AMD as you claim? Oh right, because Intel is still competing with itself and needs to provide enough improvement in order to entice me to buy another one of their products and "upgrade".The exact same thing will happen in the GPU sector, with or without AMD. Not worried at all, in fact I'm looking forward to the day a company with deep pockets buys out AMD and reinvigorates their products, I may actually have a reason to buy AMD (or whatever it is called after being bought out) again!
Iketh - Monday, July 6, 2015 - link
you overestimate the human drive... if another isn't pushing us, we will get lazy and that's not an argument... what we'll do instead to make people upgrade is release products in steps planned out much further into the future that are even smaller steps than how intel is releasing nowsilverblue - Friday, July 3, 2015 - link
I think this chart shows a better view of who was the underdog and when:http://i59.tinypic.com/5uk3e9.jpg
ATi were ahead for the 9xxx series, and that's it. Moreover, NVIDIA's chipset struggles with Intel were in 2009 and settled in early 2011, something that would've benefitted NVIDIA far more than Intel's settlement with AMD as it would've done far less damage to NVIDIA's financials over a much shorter period of time.
The lack of higher end APUs hasn't helped, nor has the issue with actually trying to get a GPU onto a CPU die in the first place. Remember that when Intel tried it with Clarkdale/Arrandale, the graphics and IMC were 45nm, sitting alongside everything else which was 32nm.
chizow - Friday, July 3, 2015 - link
I think you have to look at a bigger sample than that, riding on the 9000 series momentum, AMD was competitive for years with a near 50/50 share through the X800/X1900 series. And then G80/R600 happened and they never really recovered. There was a minor blip with Cypress vs. Fermi where AMD got close again but Nvidia quickly righted things with GF106 and GF110 (GTX 570/580).Scali - Tuesday, July 7, 2015 - link
nVidia wasn't the underdog in terms of technology. nVidia was the choice of gamers. ATi was big because they had been around since the early days of CGA and Hercules, and had lots of OEM contracts.In terms of technology and performance, ATi was always struggling to keep up with nVidia, and they didn't reach parity until the Radeon 8500/9700-era, even though nVidia was the newcomer and ATi had been active in the PC market since the mid-80s.
Frenetic Pony - Thursday, July 2, 2015 - link
Well done analysis, though the kick in the head was Bulldozer and it's utter failure. Core 2 wasn't really AMD's downfall so much as Core/Sandy Bridge, which came at the exact wrong time for the utter failure of Bulldozer. This combined with AMD's dismal failure to market its graphics card has cost them billions. Even this article calls the 290x problematic, a card that offered the same performance as the original Titan at a fraction of the price. Based on empirical data the 290/x should have been almost continuously sold until the introduction of Nvidia's Maxwell architecture.Instead people continued to buy the much less performant per dollar Nvidia cards and/or waited for "the good GPU company" to put out their new architecture. AMD's performance in marketing has been utterly appalling at the same time Nvidia's has been extremely tight. Whether that will, or even can, change next year remains to be seen.