The Intel Xeon E7-8800 v3 Review: The POWER8 Killer?
by Johan De Gelas on May 8, 2015 8:00 AM EST- Posted in
- CPUs
- IT Computing
- Intel
- Xeon
- Haswell
- Enterprise
- server
- Enterprise CPUs
- POWER
- POWER8
Single-threaded Integer Performance: 7-Zip
The profile of a compression algorithm is somewhat similar to many server workloads: it can be hard to extract instruction level parallelism (ILP) and it's sensitive to memory parallelism and latency. The instruction mix is a bit different, but it's still somewhat similar to many server workloads. Testing single threaded is also a great way to check how well the turbo boost feature works in a CPU.
And as one more reason to test performance in this manner, the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.2.
We added the 7-zip scores that we could find at the 7-zip benchmark page. But there is more. The numbers on the 7-zip bench page have no software details, so we could not be sure that they would be accurate. So we managed to get a brief session on a POWER8 "for development purposes" server. The hardware specs can be read below:

Yes, we only got access to 1 core (8 threads) and 2 GB of RAM. So real world server benchmarking was out of the question. Nevertheless, it's a start. To that end we tested with gcc 4.9.1 (supports POWER8) and recompiled our source with the "-O2 -mtune="power8" options on Ubuntu Linux 14.10 for POWER.
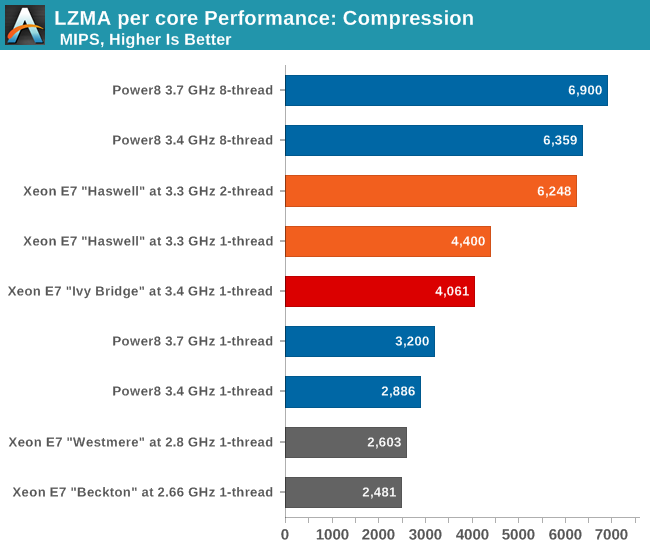
Let us first focus on the new Haswell core inside the Xeon E7, which offers a solid 10% improvement. Turbo boost brings the clockspeed of the Haswell core close enough to the Ivy Bridge core (3.3GHz vs 3.4GHz) and the improved core does the rest. Nevertheless, it is clear that we should not expect huge performance increases with a 10% faster core and 20% more cores.
Back to the more exciting stuff: the fight between Intel and IBM, between the Xeon "Haswell" and the POWER8 chip. The Haswell core is a lot more sophisticated: single threaded performance at 3.3 GHz (turbo) is no less than 50% higher than the POWER8 at 3.4 GHz. That means that the Haswell core is a lot more capable when it comes to extracting ILP out of that complex code.
However, when the IBM monster is allowed to use 8 simultaneous threads spread out over one core, something magical happens. Something that we have not seen in a long, long time: the Intel chip is no longer on top. When you use all the available threading resources in one core, the 3.4 GHz chip is a tiny bit (2%) faster than the best Intel Xeon at 3.3 GHz.








146 Comments
View All Comments
DanNeely - Saturday, May 9, 2015 - link
The work loads that you'd be buying racks of servers for are better handled with individually less expensive systems. These 4/8way leviatans are for the one or two core business functions that only scale up not out; so the typical customer would only be buying a handful of these max.The other half is that even a thousand or two thousand/year in increased operating costs for the server is not only dwarfed by the price of the server; but by the price of software that makes the server look cheap. The best server for those applications isn't the server that costs the least to run. It's not the server that has the cheapest hardware price either. It's the one that lets you get away with the cheapest licensing fee for the application you're running.
One extreme example from the better part of a decade ago was that prior to being acquired by Oracle, Sun was making extremely wide processors that were very competitive on a per socket basis but used a huge number of really slow cores/threads to get their throughput. At that time Oracle licensed its DB on a per core (per thread?) basis, not per socket. As a result, an $80-100k HP/IBM server was a cheaper way to run a massive Oracle database than a $30k Sun box even if your workload was such that the cheap Sun hardware performed equally well; because Oracle's licensing ate several times the difference in hardware prices.
KateH - Saturday, May 9, 2015 - link
I think the Intel transition was almost-entirely dictated by the lack of mobile options for PowerPC. 125W each for 970MP's sounds like a lot, but keep in mind that the Mac Pro has been using a pair of 100-130W Xeons since the beginning in 2008. Workstations and HPC are much, much less constrained by TDP. The direction that Power and SPARC has been taking for the past decade of cramming loads of SMT-enabled, high-clocked cores into a single chip somewhat negates the power concerns- if a Power8 is pulling a couple hundred watts for a 12C/96T chip, that's probably going to be worth it for the users that need that much grunt. Even Intel's E7-8890V3 is a 165W chip!melgross - Saturday, May 9, 2015 - link
Actually, the G5 was moving faster than Netburst was. In a bit over a year, it would have caught up, then moved past. Intel's unexpected move to the older "M" series for the Yonah series surprised everyone (particularly AMD), and allowed Apple to make that move. It never would have happened with Netburst.Apple switched for two reasons. One was that IBM failed to deliver a mobile G5 chip right at the time when laptop sales were increasing faster than desktop sales, and Apple was forced into using two G4s instead, which wasn't a good alternative. IBM delivered the chip after Apple switched over, but it was too late.
The second reason was that Apple wanted better Windows compatibility, which could only occur using x86 chips.
Kevin G - Saturday, May 9, 2015 - link
IBM did fail to make a G5 chip for laptops which significantly hurt Apple. Though Apple did have a plan B: PowerPC chips from PA-Semi. Also Apple never shipped a laptop with two G4 chips.And Apple didn't care about Windows software compatibility. Apple did care about hardware support as many chips couldn't be used in big endian mode or it made writing firmware for those chips complicated.
And the real second reasons why Apple ditched PowerPC was due to chipsets. The PCIe based G5's actually had a chipset that was more expensive than the CPUs that were used. It was composed of a DDR2/Hypertransport north bridge, two memory buffers, a hypertransport PCIe bridge chip from Broadcomm/Serverworks and a south bridge chip to handle SATA/USB IO, Firewire 800 chip, and a pair of Broadcomm ethernet chips. The dual core 2.5 Ghz PowerPC 970MP at the time were going between $200 and $250 a piece. Not only was the hardware complex for the motherboards but so was the software side. PowerPC 970's cannot boot themselves as they need a service processor to initialize the FSB. The PowerPC 970 chipsets Apple used have an embedded PowerPC 400 series chip in them that'll initialize and calibrate the PowerPC's high speed FSB before handing off the rest of the boot process.
SnowCat00 - Friday, May 8, 2015 - link
I would question how accurate that chart is...Mainframe sales are up: http://www.businessinsider.com/mainframe-saves-ibm...
Also as someone who works with mainframes, if one wanted to they could consolidate a entire data center to one big z13.
ats - Friday, May 8, 2015 - link
Um, I'm not sure you quite comprehend the scale of some of the datacenters out here. While Z13 is very nice, Its hardly a replacement of 10 racks of 8 socket Xeons.usernametaken76 - Friday, May 8, 2015 - link
That depends entirely on what those 10 racks worth of systems are doing and what type of applications they are running and at what utilization.Mainframes are built to run up to 100% utilization. Real world x86 systems at or above 80% are either rendering video, doing HPC or they have process control issues.
Real world Enterprise applications running in a virtualized environment is a more appropriate comparison. Everywhere I look it's VMWare at the moment.
Compare a PowerVM DLPAR to a VMWare VM running Linux x64 for a more fair, real world comparison.
melgross - Saturday, May 9, 2015 - link
It isn't the same thing. Mainframes excell in I/O, which often trumps pure processing power. It's a very different environment.ats - Saturday, May 9, 2015 - link
Um, the days of mainframes having any real advantage in I/O are long gone, fyi.Kevin G - Saturday, May 9, 2015 - link
Sort of. Mainframes still farm off most IO commands to dedicated coprocessors so that they don't eat away CPU cycles running actually applications.Mainframes also have dedicated hardware for encryption and compression. This is becoming more common in the x86 world on a drive basis but the mainframe implements this at a system level so that any drive's data can be encrypted and compressed.
It is also because of these coprocessors that IBM's mainframe virtualization is so robust: even the hypervisor itself can be virtualized on top of an another hypervisor without any slow down in IO or reduction in functionality.