NVIDIA Tegra X1 Preview & Architecture Analysis
by Joshua Ho & Ryan Smith on January 5, 2015 1:00 AM EST- Posted in
- SoCs
- Arm
- Project Denver
- Mobile
- 20nm
- GPUs
- Tablets
- NVIDIA
- Cortex A57
- Tegra X1
Automotive: DRIVE CX and DRIVE PX
While NVIDIA has been a GPU company throughout the entire history of the company, they will be the first to tell you that they know they can’t remain strictly a GPU company forever, and that they must diversify themselves if they are to survive over the long run. The result of this need has been a focus by NVIDIA over the last half-decade or so on offering a wider range of hardware and even software. Tegra SoCs in turn have been a big part of that plan so far, but NVIDIA of recent years has become increasingly discontent as a pure hardware provider, leading to the company branching out in unusual ways and not just focusing on selling hardware, but selling buyers on whole solutions or experiences. GRID, Gameworks, and NVIDIA’s Visual Computing Appliances have all be part of this branching out process.
Meanwhile with unabashed car enthusiast Jen-Hsun Huang at the helm of NVIDIA, it’s slightly less than coincidental that the company has also been branching out in to automotive technology as well. Though still an early field for NVIDIA, the company’s Tegra sales for automotive purposes have otherwise been a bright spot in the larger struggles Tegra has faced. And now amidst the backdrop of CES 2015 the company is taking their next step into automotive technology by expanding beyond just selling Tegras to automobile manufacturers, and into selling manufacturers complete automotive solutions. To this end, NVIDIA is announcing two new automotive platforms, NVIDIA DRIVE CX and DRIVE PX.
DRIVE CX is NVIDIA’s in-car computing platform, which is designed to power in-car entertainment, navigation, and instrument clusters. While it may seem a bit odd to use a mobile SoC for such an application, Tesla Motors has shown that this is more than viable.

With NVIDIA’s DRIVE CX, automotive OEMs have a Tegra X1 in a board that provides support for Bluetooth, modems, audio systems, cameras, and other interfaces needed to integrate such an SoC into a car. This makes it possible to drive up to 16.6MP of display resolution, which would be around two 4K displays or eight 1080p displays. However, each DRIVE CX module can only drive three displays. In press photos, it appears that this platform also has a fan which is likely necessary to enable Tegra X1 to run continuously at maximum performance without throttling.

NVIDIA showed off some examples of where DRIVE CX would improve over existing car computing systems in the form of advanced 3D rendering for navigation to better convey information, and 3D instrument clusters which are said to better match cars with premium design. Although the latter is a bit gimmicky, it does seem like DRIVE CX has a strong selling point in the form of providing an in-car computing platform with a large amount of compute while driving down the time and cost spent developing such a platform.

While DRIVE CX seems to be a logical application of a mobile SoC, DRIVE PX puts mobile SoCs in car autopilot applications. To do this, the DRIVE PX platform uses two Tegra X1 SoCs to support up to twelve cameras with aggregate bandwidth of 1300 megapixels per second. This means that it’s possible to have all twelve cameras capturing 1080p video at around 60 FPS or 720p video at 120 FPS. NVIDIA has also made most of the software stack needed for autopilot applications already, so there would be comparatively much less time and cost needed to implement features such as surround vision, auto-valet parking, and advanced driver assistance.

In the case of surround vision, DRIVE PX is said to deliver a better experience by improving stitching of video to reduce visual artifacts and compensate for varying lighting conditions.

The valet parking feature seems to build upon this surround vision system, as it uses cameras to build a 3D representation of the parking lot along with feature detection to drive through a garage looking for a valid parking spot (no handicap logo, parking lines present, etc) and then autonomously parks the car once a valid spot is found.
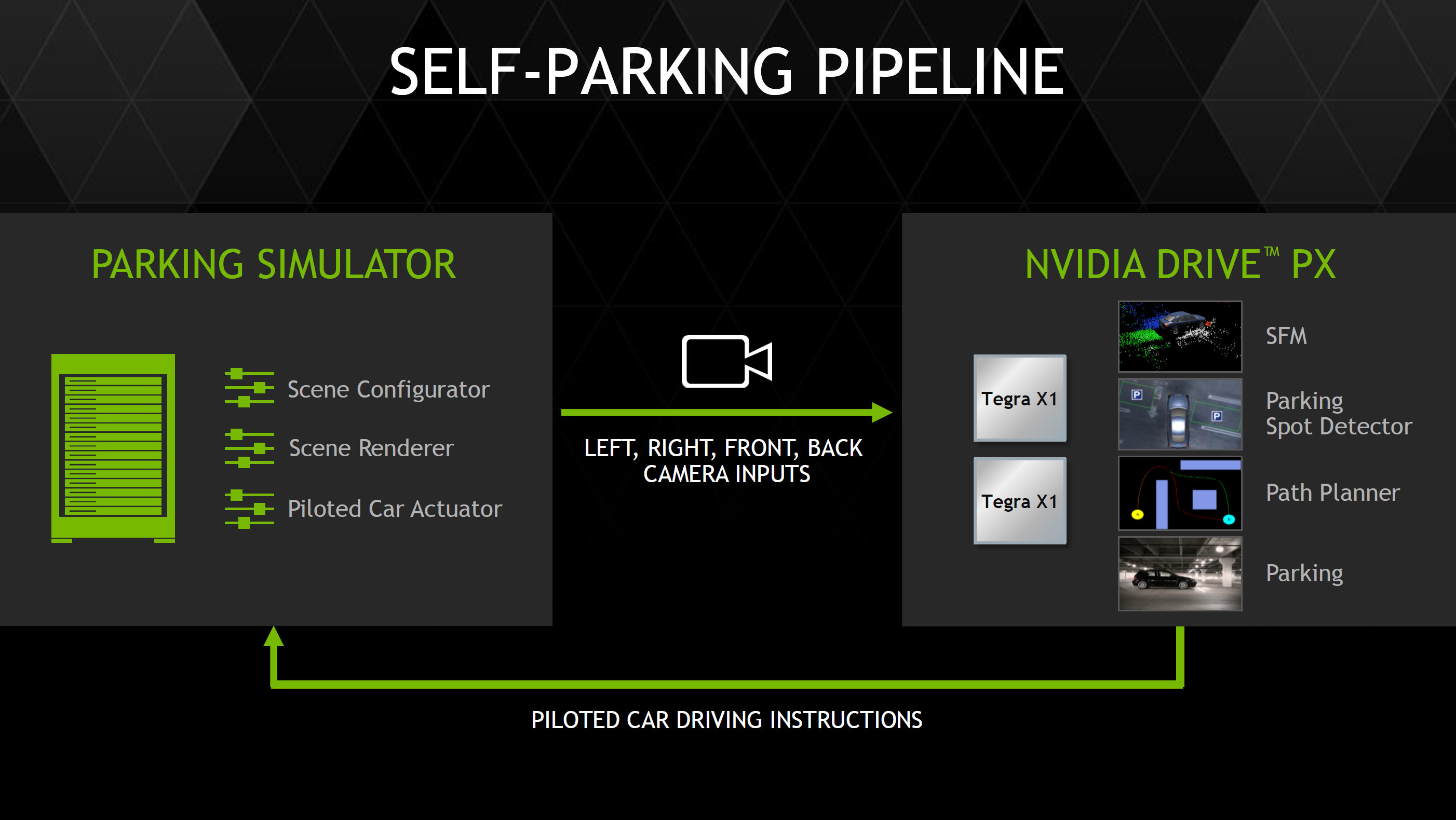
NVIDIA has also developed an auto-valet simulator system with five GTX 980 GPUs to make it possible for OEMs to rapidly develop self-parking algorithms.

The final feature of DRIVE PX, advanced driver assistance, is possibly the most computationally intensive out of all three of the previously discussed features. In order to deliver a truly useful driver assistance system, NVIDIA has leveraged neural network technologies which allow for object recognition with extremely high accuracy.
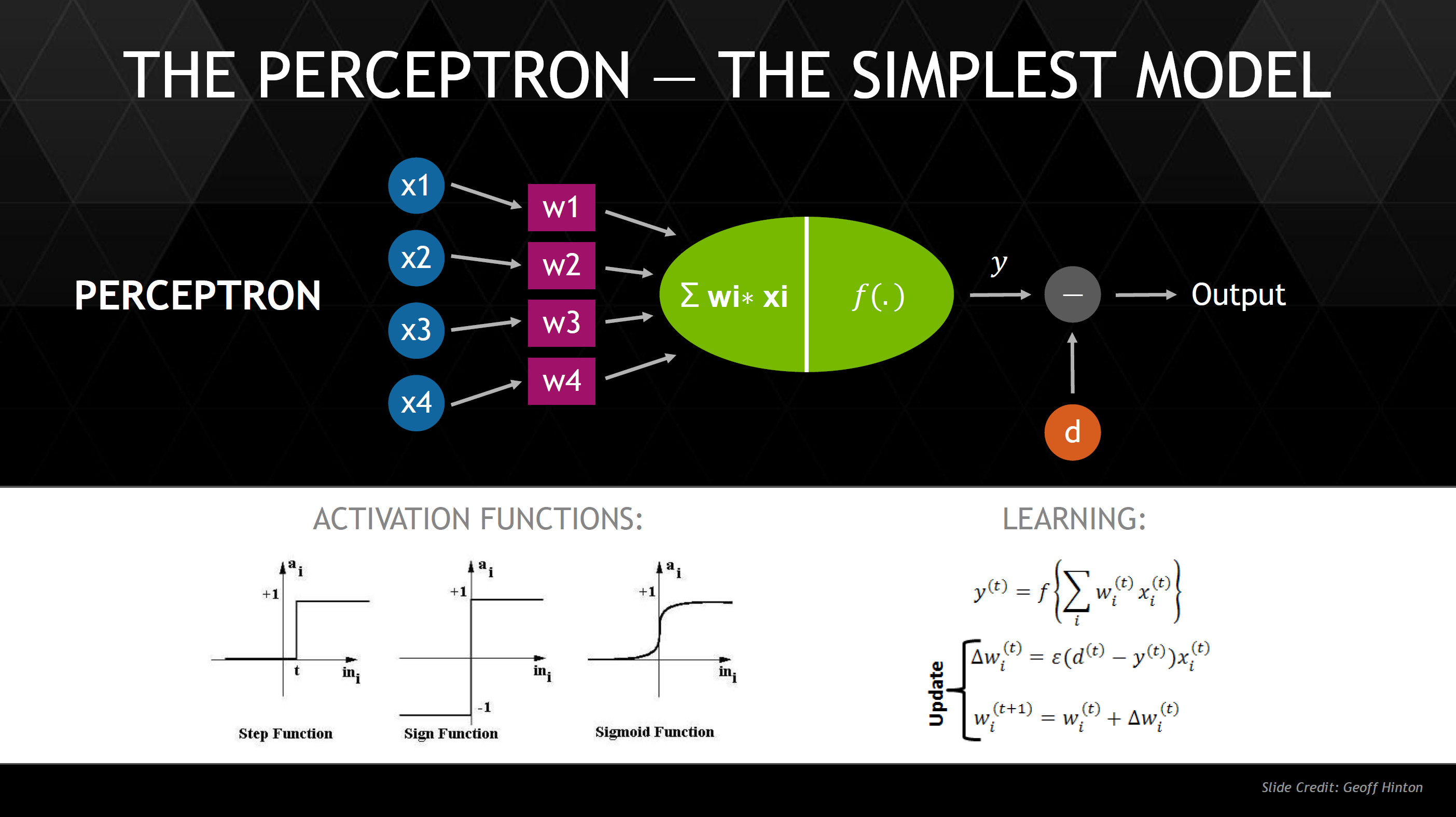
While we won’t dive into deep detail on how such neural networks work, in essence a neural network is composed of perceptrons, which are analogous to neurons. These perceptrons receive various inputs, then given certain stimulus levels for each input the perceptron returns a Boolean (true or false). By combining perceptrons to form a network, it becomes possible to teach a neural network to recognize objects in a useful manner. It’s also important to note that such neural networks are easily parallelized, which means that GPU performance can dramatically improve performance of such neural networks. For example, DRIVE PX would be able to detect if a traffic light is red, whether there is an ambulance with sirens on or off, whether a pedestrian is distracted or aware of traffic, and the content of various road signs. Such neural networks would also be able to detect such objects even if they are occluded by other objects, or if there are differing light conditions or viewpoints.

While honing such a system would take millions of test images to reach high accuracy levels, NVIDIA is leveraging Tesla in the cloud for training neural networks that are then loaded into DRIVE PX instead of local training. In addition, failed identifications are logged and uploaded to the cloud in order to further improve the neural network. Both of these updates can be done either over the air or at service time, which should mean that driver assistance will improve with time. It isn’t a far leap to see how such technology could also be leveraged in self-driving cars as well.

Overall, NVIDIA seems to be planning for the DRIVE platforms to be ready next quarter, and production systems to be ready for 2016. This should mean that it's possible for vehicles launching in 2016 to have some sort of DRIVE system present, although it's possible that it would take until 2017 to see this happen.








194 Comments
View All Comments
tipoo - Monday, January 5, 2015 - link
Oh I read that wrong, you meant the games, not the play store. Still, games almost never crash on this either.PC Perv - Monday, January 5, 2015 - link
Why do you guys write what essentially is a PR statements by NV as if they were independently validated facts by yourselves? I suppose you guys did not have time to test any of these claims.So you end up writing contradictory paragraphs one after another. In the first, you say NVIDIA "embarked on a mobile first design for the first time." That statement in and of itself is not something one can prove or disprove, but in the very next paragraph you write,
"By going mobile-first NVIDIA has been able to reap a few benefits.. their desktop GPUs has resulted chart-topping efficiency, and these benefits are meant to cascade down to Tegra as well." (??)
I suggest you read that paragraph again. Maybe you missed something, or worse the whole paragraph comes off unintelligible.
ABR - Monday, January 5, 2015 - link
Well the situation itself is confusing since NVIDIA might have designed Maxwell "mobile-first" but actually released it "desktop-first". Then came notebook chips and now we are finally seeing Tegra. So release-wise the power efficiency "cascades down", even though they presumably designed starting from the standpoint of doing well under smaller power envelopes.PC Perv - Monday, January 5, 2015 - link
But that is a tautology that is totally vacuous of meaning. One can say the opposite thing in the exact same way: "We went with desktop first, but released to mobile first, so that power efficiency we've learned "cascaded up" to the desktops.So the impression one gets from reading that explanation is that it does not matter whether it was mobile first or desktop first. It is a wordplay that is void of meaningful information. (but designed to sound like something, I guess)
Yojimbo - Monday, January 5, 2015 - link
Isn't that standard reviewing practice? "Company X says they did Y in their design, and it shows in Z." The reviewer doesn't have to plant a mole in the organization and verify if NVIDIA really did Y like they said. This is a review, not an interrogation. If the results don't show in Z, then the reviewer will question the effectiveness of Y or maybe whether Y was really done as claimed. Yes, the logical flow of the statement you quoted is a bit weak, but I think it just has to do with perhaps poor writing and not from being some sort of shill, like you imply. The fact is that result Z, power-efficiency, is there in this case and it has been demonstrated on previously-released desktop products.As far as your statement that one could say the opposite thing and have the same meaning, I don't see it. Because going "mobile-first" means to focus on power-efficiency in the design of the architecture. It has nothing to do with the order of release of products. That is what the author means by "mobile-first," in any case. To say that NVIDIA was going "desktop-first" would presumably mean that raw performance, and not power-efficiency, was the primary design focus, and so the proper corresponding statement would be: "We went desktop-first, but released to mobile first, and the performance is meant to "cascade up" (is that a phrase? probably should be scale up, unless you live on a planet where the waterfalls fall upwards) to the desktops." There are two important notes here. Firstly, one could not assume that desktop-first design should result in increased mobile performance just because mobile-first design results in increased desktop efficiency. Secondly and more importantly, you replaced "is meant to" with "so". "So" implies a causation, which directly introduces the logical problem you are complaining about. The article says "is meant to," which implies that NVIDIA had aforethought in the design of the chip, with this release in mind, even though the desktop parts launched first. That pretty much describes the situation as NVIDIA tells it (And I don't see why you are so seemingly eager to disbelieve it. The claimed result, power-efficiency, is there, as I previously said.), and though maybe written confusingly, doesn't seem to have major logical flaws: "1. NVIDIA designed mobile-first, i.e., for power-efficiency. 2. We've seen evidence of this power-efficiency on previously-released desktop products. 3. NVIDIA always meant for this power-efficiency to similarly manifest itself in mobile products." The "cascade down" bit is just a color term.
Yojimbo - Monday, January 5, 2015 - link
I just want to note that I don't think the logical flow of the originally-written statement is as weak as I conceded to in my first paragraph. In your paraphrase-quote you left out the main clause and instead included a subordinate clause and treated it as the main clause. The author is drawing a parallel and citing evidence at the same time as making a logical statement and does so in a way that is a little confusing, but I don't think it really has weak logical flow.chizow - Monday, January 5, 2015 - link
Anyone who is familiar with the convergence of Tegra and GeForce/Tesla roadmaps and design strategy understands what the author(s) meant to convey there.Originally, Nvidia's design was to build the biggest, fastest GPU they could with massive monolithic GPGPUs built primarily for intensive graphics and compute applications. This resulted in an untenable trend with increasingly bigger and hotter GPUs.
After the undeniably big, hot Fermi arch, Nvidia placed an emphasis on efficiency with Kepler, but on the mobile side of things, they were still focusing on merging and implementing their desktop GPU arch with their mobile, which they did beginning with Tegra K1. The major breakthrough for Nvidia here was bringing mobile GPU arch in-line with their established desktop line.
That has changed with Maxwell, where Nvidia has stated, they took a mobile-first design strategy for all of their GPU designs and modularized it to scale to higher performance levels, rather than vice-versa, and the results have been obvious on the desktop space. Since Maxwell is launching later in the mobile space, the authors are saying everyone expects the same benefits in terms of power saving from mobile Maxwell over mobile Kepler that we saw with desktop Maxwell parts over desktop Kepler parts (roughly 2x perf/w).
There's really no tautology if you took the time to understand the development and philosophy behind the convergence of the two roadmaps.
Mondozai - Monday, January 5, 2015 - link
No, it's not untelligible for reasons that other people have already explained. If you understand the difference between what it is developed for and what is released first you understand the difference. And apparently you don't.OBLAMA2009 - Monday, January 5, 2015 - link
man nvidia is such a jokeMasterTactician - Monday, January 5, 2015 - link
512 GFLOPS... 8800GTX in a phone, anyone? Impressive.