The Google Nexus 9 Review
by Joshua Ho & Ryan Smith on February 4, 2015 8:00 AM EST- Posted in
- Tablets
- HTC
- Project Denver
- Android
- Mobile
- NVIDIA
- Nexus 9
- Lollipop
- Android 5.0
Designing Denver
Diving into the depths of Denver, Denver is in a lot of ways exactly the kind of CPU you’d expect a GPU company to build. NVIDIA’s traditional engineering specialty is in building wide arrays of simple in-order processors, a scheme that maps well to the ridiculously parallel nature of graphics. Whether intentional to tap their existing expertise or just a result of their plan to go in such a divergent route from “traditional” CPUs, Denver makes you stop and ponder GPUs for a moment when looking at its execution workflow.
The results of NVIDIA’s labors in designing Denver has been a wide but in-order processor. With the potential to retire up to 7 operations per cycle, Denver measured front-to-back is wider than A15/A57 and wider than Cyclone. Officially NVIDIA calls this a “7+” IPC architecture, alluding to Denver’s binary translation and code optimization step, and the potential to merge operations as part of the process.
Meanwhile the existence of this code optimizer is the first sign we see that Denver is not a traditional CPU by the standards of ARM/Apple or Intel/AMD. To understand why that is we must first discuss Out of Order Execution (OoOE), why it exists, and why Denver doesn’t have it.
In traditional CPU designs, we make a distinction between in-order designs and out-of-order designs. As appropriately named, in-order designs will execute instructions in the order they receive them, and meanwhile out-of-order designs have the ability to rearrange instructions within a limited window, so long as the altered order doesn’t change the results. For the kinds of tasks that CPUs work with, OoOE improves throughput, but it does come at a cost.
Overall OoOE is considered the next logical step after in-order execution has reached its natural limits. Superscalar in-order execution can potentially scale up to a few instructions at once, but actually achieving that is rare, even with the help of good compilers. At some point other constraints such as memory accesses prevent an instruction from executing, holding up the entire program. In practice once you need performance exceeding a traditional in-order design, then you switch to out-of-order. With OoOE then it becomes possible to scale performance out further, with the ability to use the reodering process to fill wider processors and to keep from losing performance due to stalls.

K1-64 Die Shot Mock-up (NVIDIA)
The cost of OoOE is complexity, die size, and power consumption. The engines to enable OoOE can be quite large, being tasked with queuing instructions, identifying which instructions can be reordered, and ensuring instructions are safe to execute out-of-order. Similarly, there is a power cost to these engines, and that means adding OoOE to a processor can make it much larger and more power hungry, even without actually adding further units for the OoOE engines to fill. Make no mistake, the benefits of OoOE are quite large, but then so is the cost of implementing it.
As such, while OoOE has been treated as the next step after in-order processors it is not the only solution to the problem being pursued. The fundamental problems in-order processors face are a combination of hardware and software; hardware issues such as memory stalls, and software issues such as poor instruction ordering. It stands to reason then that if the performance scaling problem can be solved in hardware with OoOE, then can it be solved in software as well? It’s this school of thought that NVIDIA is pursuing in Denver.
Perhaps the critical point in understanding Denver then is that it is non-traditional for a high-performance CPU due to its lack of OoOE hardware, and for that reason it’s a CPU unlike any of its contemporaries. We’ll get back to the software aspects of Denver in a bit, but for now it’s enough to understand why NVIDIA has not pursued an OoOE design and what they have pursued instead.
Denver’s Deep Details
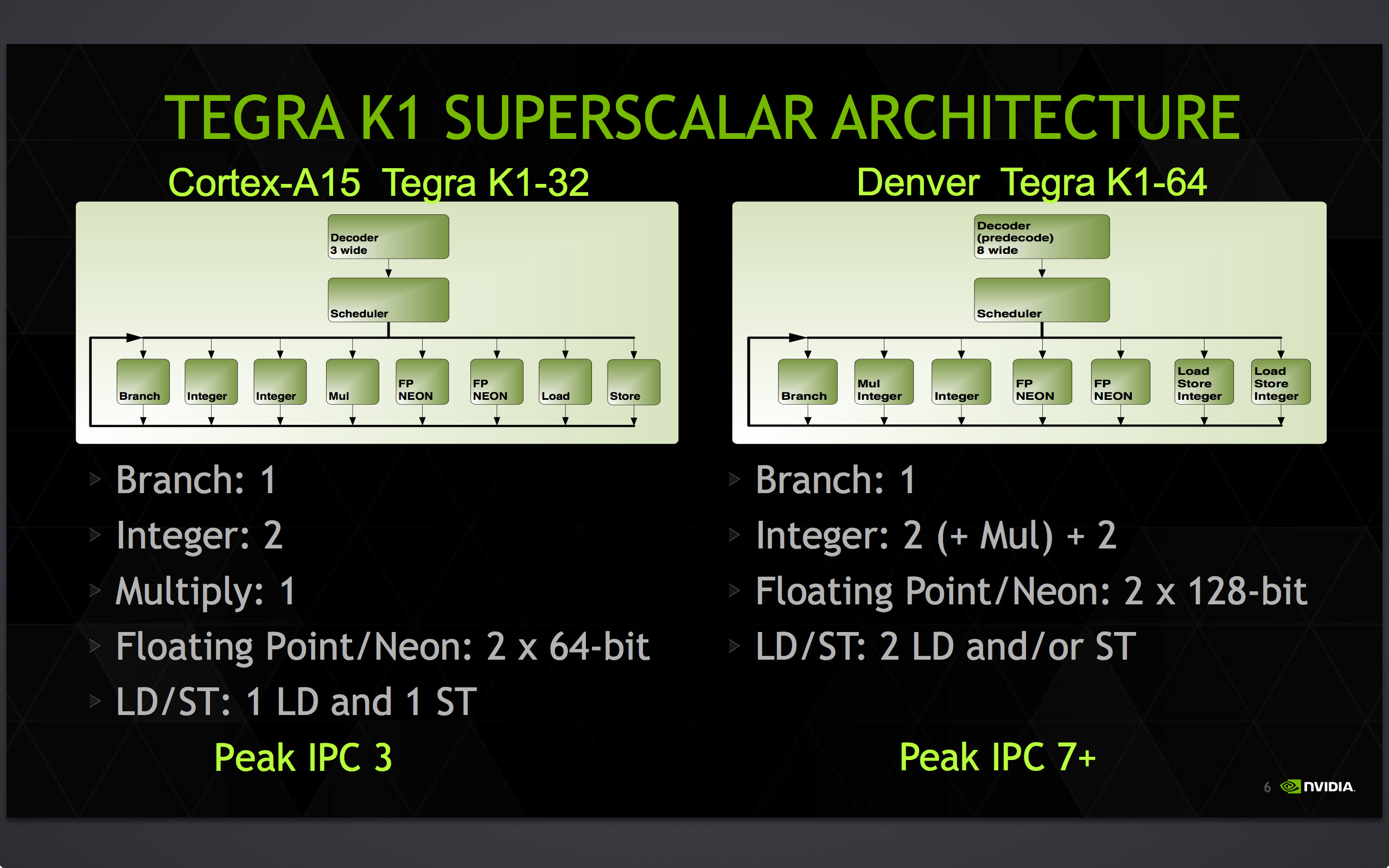
Due to NVIDIA’s choice not to pursue OoOE on Denver and simultaneously pursue a large, high performance core, Denver is by consumer standards a very wide CPU. With no OoOE hardware NVIDIA has been able to fill out Denver with execution units, with 7 slots’ worth of execution units backed by a native decoder wide enough to feed all of those units at once. The native decoder in particular is quite notable here, as most other CPU designs have narrower decoders that put a lower limit on their theoretical IPC. The Cortex-A15 cores in Tegra K1-32 for example only feature 3-wide decoders, despite having many more slots’ worth of execution units. Consequently a large decoder not only opens up the ability to increase IPC, but it is a sign that the CPU developer believes that their design is capable of keeping that many execution units busy enough to justify the cost of the wider decoder.
| NVIDIA CPU Core Comparison | ||||||
| K1-32 | K1-64 | |||||
| CPU | Cortex-A15 | NVIDIA Denver | ||||
| ARM ISA | ARMv7 (32-bit) | ARMv8 (32/64-bit) | ||||
| Issue Width | 3 micro-ops | 2 (ARM) or 7 (Native) micro-ops | ||||
| Pipeline Length | 18 stages | 15 stages | ||||
| Branch Mispredict Penalty | 15 cycles | 13 cycles | ||||
| Integer ALUs | 2 | 4 | ||||
| Load/Store Units | 1 + 1 (Dedicated L/S) | 2 (Shared L/S) | ||||
| Branch Units | 1 | 1 | ||||
| FP/NEON ALUs | 2x64-bit | 2x128-bit | ||||
| L1 Cache | 32KB I$ + 32KB D$ | 128KB I$ + 64KB D$ | ||||
| L2 Cache | 2MB | 2MB | ||||
These execution units themselves are fairly unremarkable, but none the less are very much at the heart of Denver. Compared again to Terga 4, there are twice as many load/store units, and the NEON units have been extended from 64-bits wide to 128-bits wide, allowing them to retire up to twice as much work per cycle if they can be completely filled.
Internally Denver executes instructions using the Very Long Instruction Word (VLIW) format, which is an instruction format that these days is more common with GPUs than it is CPUs, making it another vaguely GPU-like aspect of Denver. In VLIW all instructions are packed into a single word and sent through the pipeline at once, rather than handing each slot its own instruction. Each VLIW instruction is variable in length, and in turn the length of the operation is similarly variable, depending in part on factors such as the number of registers any given instruction operates upon. With a maximum VLIW instruction size of 32 bytes, this means that the number of operations a single instruction can contain is dependent on the operations, and it’s possible for large operations to fill out the VLIW early.
Another one of Denver’s unusual aspects is its internal instruction format, which is very different from ARMv7 or ARMv8. Though the specific format is beyond the scope of this article, it has long been rumored that Denver was originally meant to be an x86 design, with Denver’s underlying design and binary translation pairing intended to allow for an x86 implementation without infringing on any x86 hardware patents. Whether that is true or not, the end result of Denver is that owing to NVIDIA’s decision to solve their needs in software, NVIDIA was able to create an architecture whose design is decoupled from the actual instruction set it is executing.
Yet in spite of this architectural choice, Denver still needs to be able to execute ARM code as well as native code from binary translation, which leads to one more interesting wrinkle to Denver’s design. Denver has not one but two decoders, the native decoder and a proper ARM decoder. Designed to work in situations where Denver’s software optimizer is not worth running or can’t translate in time – such as with brand new code segments – the ARM decoder allows for Denver to directly decode ARM instructions.
The ARM decoder is not quite a backup, but it is not intended to be the main source of operations for Denver over the long run. Rather the bulk of the work for Denver should come from its binary translator, and only a small fraction of infrequently used code should hit the ARM decoder. At only 2 instructions wide this decoder is narrower than even A15’s decoder, not to mention it forms an entirely in-order pipeline that misses out on the instruction rescheduling and other optimizing benefits of the software code optimizer. Never the less it serves an important role in situations where Denver can’t use native code by giving it a means to immediately begin executing ARM code. This as a result makes Denver a kind of hybrid design, capable of executing either ARM instructions or NVIDIA’s own internal microcode.
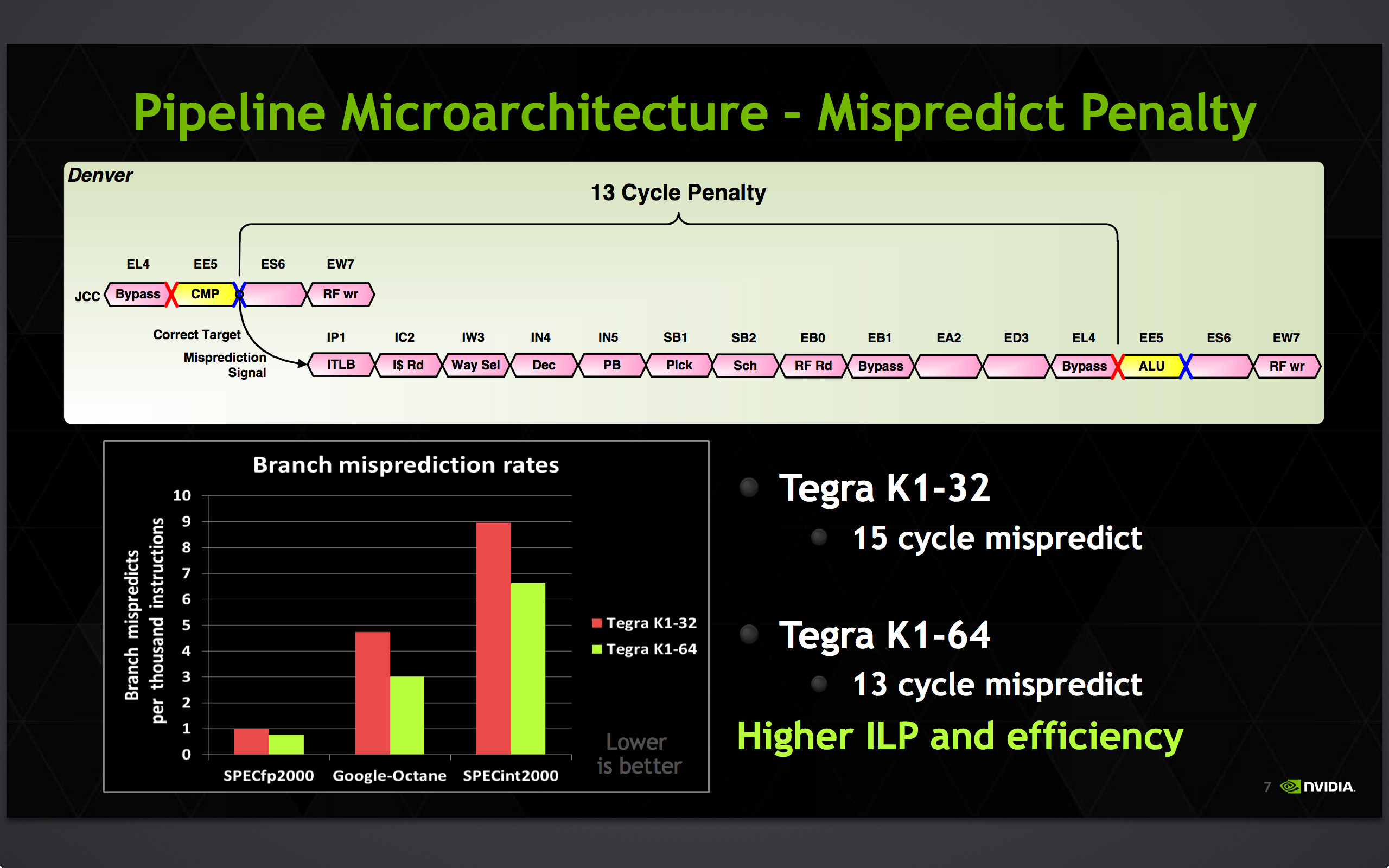
Meanwhile Denver’s overall pipeline stands at 15 stages deep. Despite the overall width of Denver this actually makes the pipeline shorter than the 18 stage A15 by a few stages. And similarly, the penalty for branch mispredictions is down from 15 cycles in A15 to 13 cycles in Denver.
Last but not least, on the logical level NVIDIA has also been working to further reduce their power consumption through a new mode called CC4. CC4 is essentially a deeper state of sleep that’s not quite power-gating the entire CPU, but none the less results in most of the CPU being shut off. What ends up being retained in CC4 is the cache and what NVIDIA dubs the “architectural state” of the processor, a minimal set of hardware that allows the core voltage to drop below traditional Vmin and instead hold at just enough voltage to retain the contents of the cache and state, as no work needs to be done in this state. It's worth noting that we've seen similar power collapse states as far back as the A15 though, so the idea isn't necessarily new.
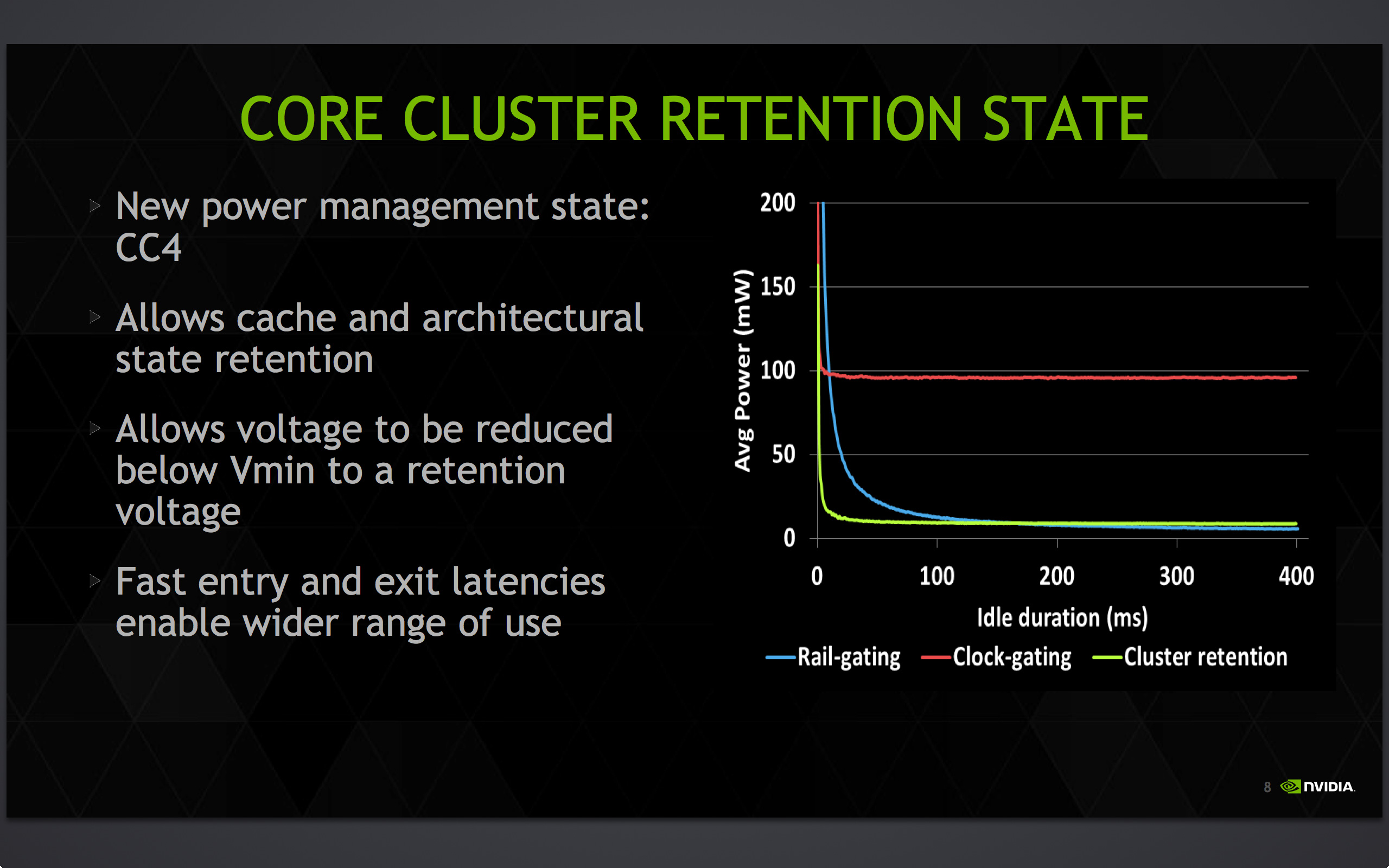
CC4 as a result is intended to be a relatively fast sleep state given its depth, with Denver able to enter and exit it faster than power-gating, and consequently it can be used more frequently. That said since it is deeper than other sleep states it is also slower than them, meaning the CPUIdle governor needs to take this into account and only select CC4 when there’s enough time to take advantage of it. Otherwise if Denver enters CC4 and has to come out of it too soon, the processor can end up wasting more power setting up CC4 than a very short CC4 duration would save.
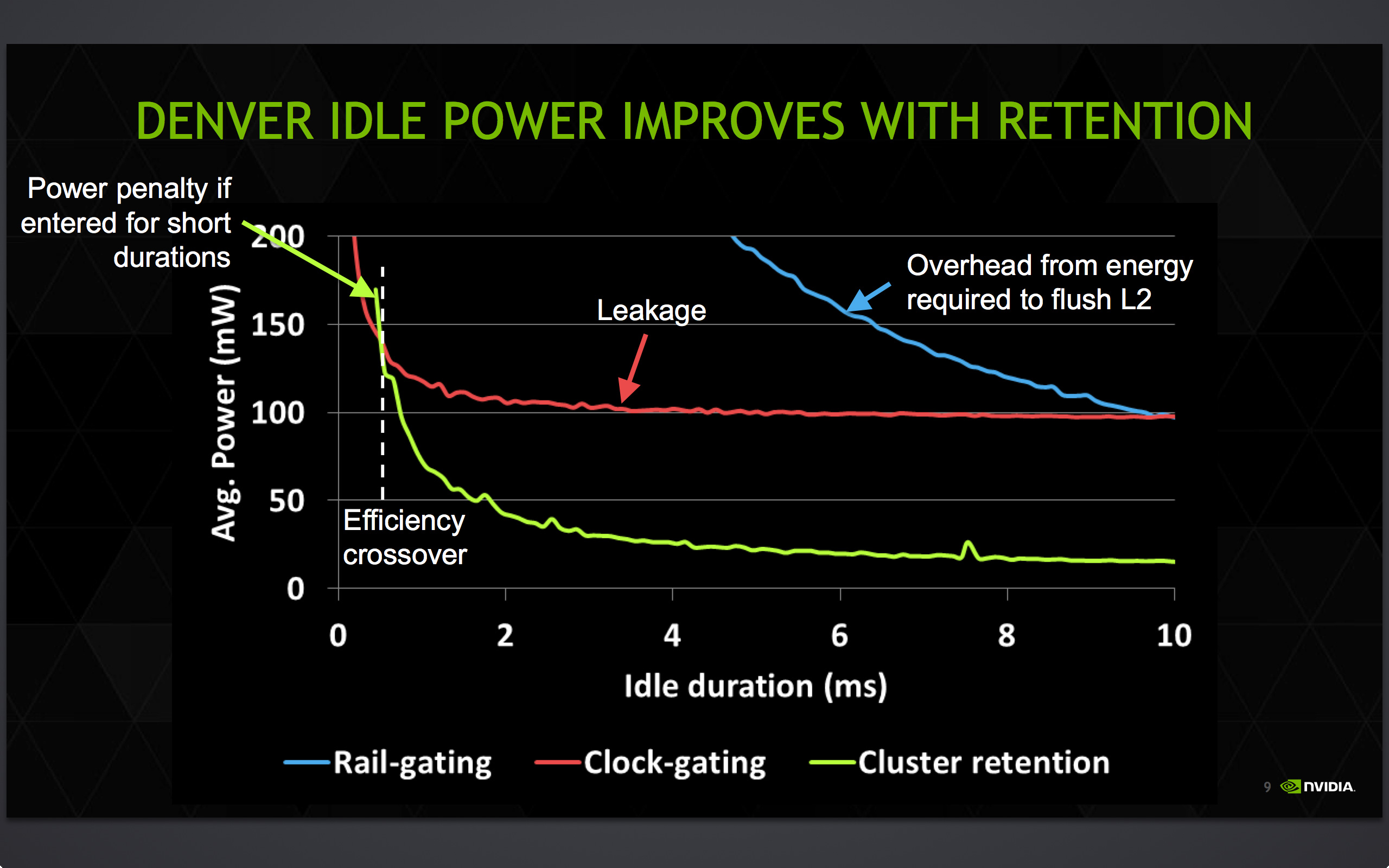
Of course CC4 is just one of many factors in Denver’s power consumption. Hardware and software alike plays a role, from the silicon itself and the leakage characteristics of the physical transistors to the binary translation layer necessary for Denver to operate at its peak. And that brings us to the final and more crucial piece of the Denver puzzle: the binary translation layer.








169 Comments
View All Comments
coburn_c - Wednesday, February 4, 2015 - link
High end my rear end. HTC has made high end tablets, HTC makes high end devices, Google makes high end companies make garbage. Seriously. Google devices are done.rpmrush - Wednesday, February 4, 2015 - link
On the cover page it has a tag in the top right saying, "HTX Nexus #2". Should be HTC?cknobman - Wednesday, February 4, 2015 - link
So regardless of how nice the hardware it Android (and more importantly most of its apps) still have major issues when it comes to tablets.Why waste time buying this stuff when you can get a Windows 8 tablet?
I get the best of both tablet and PC worlds in one device without being held hostage by lord overseer Apple dictating my every move or Androids crappy support and busted app ecosystem.
milkod2001 - Wednesday, February 4, 2015 - link
@cknobmanthere's no Windows 8 tablet out there for the same price,with same quality screen and snappiness as this one or Apple tablets. The closest would be Surface3 but it's much more expensive.
If you happen to know about any please post some links please.
rkhighlight - Wednesday, February 4, 2015 - link
Because a Windows 8 tablet is worse than a tablet when it comes to tablet user experience and worse than a notebook when it comes to notebook experience. Most people like to have two separate devices rather than owning a product that tries to combine everything. For some people this works but the majority prefers two product.milkod2001 - Wednesday, February 4, 2015 - link
not necessarily if done right. Lenovo Yoga comes probably the closest with its hybrid(tablet +notebook). It need to be much cheaper if it wants to be acquired by majority though.melgross - Wednesday, February 4, 2015 - link
The Yoga got terrible reviews everywhere. It's hardly recommended.Midwayman - Wednesday, February 4, 2015 - link
I don't think that's true at all. Most people would probably prefer to only pay for one device. The issue is one more of execution than concept. If the surface pro 3 were as light, thin, and as good on battery as high end tablets I certainly would have bought one. At a premium even.Impulses - Wednesday, February 4, 2015 - link
It that were true MS wouldn't be able to keep Surface on the shelves and the market for x86 Atom hybrids at <$500 would be comprised of more than a handful of OEM & models...I think for a certain class of individuals it makes all the sense in the world; students, business travelers, etc. For most people however it's just a compromise on both form factors and not really much of a money saver (specially when you factor the upgrade cycle into the equation).
steven75 - Thursday, February 5, 2015 - link
I have a Windows 8.1 tablet (not RT). It's the worst tablet interface I've used yet. A total bomb. And the touch apps and selection are universally awful.If it didn't have "classic" Windows desktop, I'd have sent it back to the store.