The Google Nexus 9 Review
by Joshua Ho & Ryan Smith on February 4, 2015 8:00 AM EST- Posted in
- Tablets
- HTC
- Project Denver
- Android
- Mobile
- NVIDIA
- Nexus 9
- Lollipop
- Android 5.0
The Secret of Denver: Binary Translation & Code Optimization
As we alluded to earlier, NVIDIA’s decision to forgo a traditional out-of-order design for Denver means that much of Denver’s potential is contained in its software rather than its hardware. The underlying chip itself, though by no means simple, is at its core a very large in-order processor. So it falls to the software stack to make Denver sing.
Accomplishing this task is NVIDIA’s dynamic code optimizer (DCO). The purpose of the DCO is to accomplish two tasks: to translate ARM code to Denver’s native format, and to optimize this code to make it run better on Denver. With no out-of-order hardware on Denver, it is the DCO’s task to find instruction level parallelism within a thread to fill Denver’s many execution units, and to reorder instructions around potential stalls, something that is no simple task.
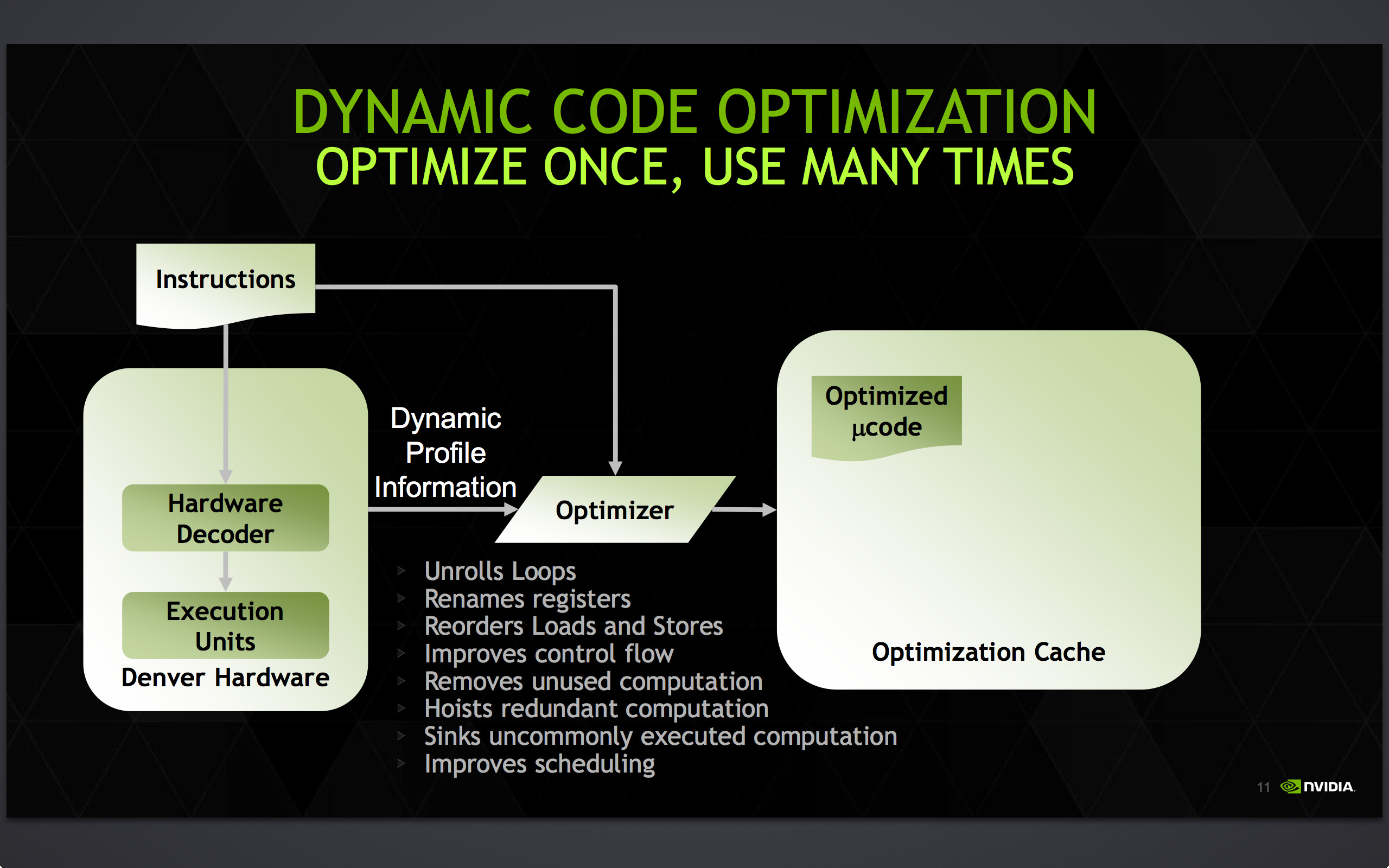
Starting first with the binary translation aspects of DCO, the binary translator is not used for all code. All code goes through the ARM decoder units at least once before, and only after Denver realizes it has run the same code segments enough times does that code get kicked to the translator. Running code translation and optimization is itself a software task, and as a result this task requires a certain amount of real time, CPU time, and power. This means that it only makes sense to send code out for translation and optimization if it’s recurring, even if taking the ARM decoder path fails to exploit much in the way of Denver’s capabilities.
This sets up some very clear best and worst case scenarios for Denver. In the best case scenario Denver is entirely running code that has already been through the DCO, meaning it’s being fed the best code possible and isn’t having to run suboptimal code from the ARM decoder or spending resources invoking the optimizer. On the other hand then, the worst case scenario for Denver is whenever code doesn’t recur. Non-recurring code means that the optimizer is never getting used because that code is never seen again, and invoking the DCO would be pointless as the benefits of optimizing the code are outweighed by the costs of that optimization.
Assuming that a code segment recurs enough to justify translation, it is then kicked over to the DCO to receive translation and optimization. Because this itself is a software process, the DCO is a critical component due to both the code it generates and the code it itself is built from. The DCO needs to be highly tuned so that Denver isn’t spending more resources than it needs to in order to run the DCO, and it needs to produce highly optimal code for Denver to ensure the chip achieves maximum performance. This becomes a very interesting balancing act for NVIDIA, as a longer examination of code segments could potentially produce even better code, but it would increase the costs of running the DCO.
In the optimization step NVIDIA undertakes a number of actions to improve code performance. This includes out-of-order optimizations such as instruction and load/store reordering, along register renaming. However the DCO also behaves as a traditional compiler would, undertaking actions such as unrolling loops and eliminating redundant/dead code that never gets executed. For NVIDIA this optimization step is the most critical aspect of Denver, as its performance will live and die by the DCO.
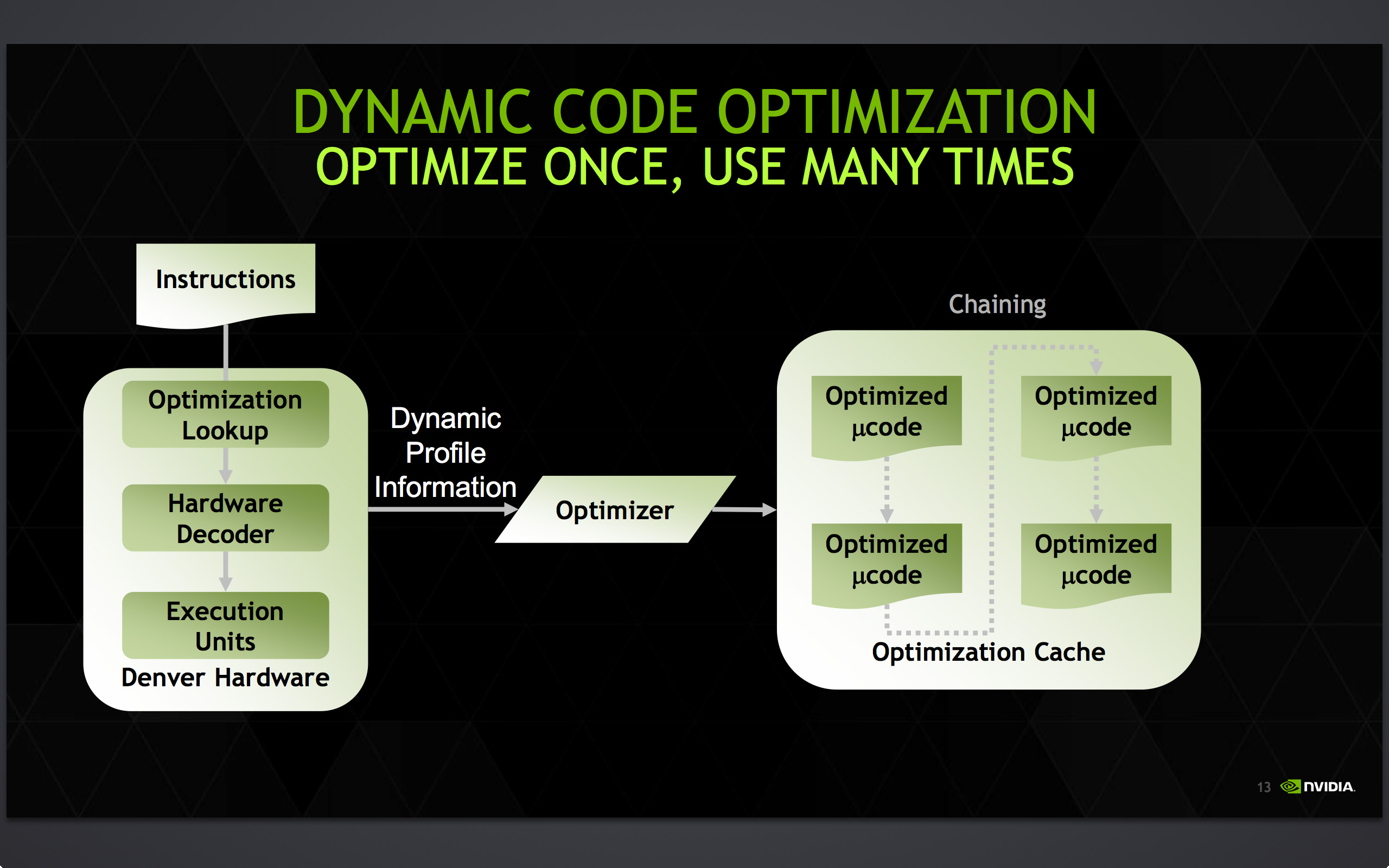
Denver's optimization cache: optimized code can call other optimized code for even better performance
Once code leaves the DCO, it is then stored for future use in an area NVIDIA calls the optimization cache. The cache is a 128MB segment of main memory reserved to hold these translated and optimized code segments for future reuse, with Denver banking on its ability to reuse code to achieve its peak performance. The presence of the optimization cache does mean that Denver suffers a slight memory capacity penalty compared to other SoCs, which in the case of the N9 means that 1/16th (6%) of the N9’s memory is reserved for the cache. Meanwhile, also resident here is the DCO code itself, which is shipped and stored as already-optimized code so that it can achieve its full performance right off the bat.
Overall the DCO ends up being interesting for a number of reasons, not the least of which are the tradeoffs are made by its inclusion. The DCO instruction window is larger than any comparable OoOE engine, meaning NVIDIA can look at larger code blocks than hardware OoOE reorder engines and potentially extract even better ILP and other optimizations from the code. On the other hand the DCO can only work on code in advance, denying it the ability to see and work on code in real-time as it’s executing like a hardware out-of-order implementation. In such cases, even with a smaller window to work with a hardware OoOE implementation could produce better results, particularly in avoiding memory stalls.
As Denver lives and dies by its optimizer, it puts NVIDIA in an interesting position once again owing to their GPU heritage. Much of the above is true for GPUs as well as it is Denver, and while it’s by no means a perfect overlap it does mean that NVIDIA comes into this with a great deal of experience in optimizing code for an in-order processor. NVIDIA faces a major uphill battle here – hardware OoOE has proven itself reliable time and time again, especially compared to projects banking on superior compilers – so having that compiler background is incredibly important for NVIDIA.
In the meantime because NVIDIA relies on a software optimizer, Denver’s code optimization routine itself has one last advantage over hardware: upgradability. NVIDIA retains the ability to upgrade the DCO itself, potentially deploying new versions of the DCO farther down the line if improvements are made. In principle a DCO upgrade not a feature you want to find yourself needing to use – ideally Denver’s optimizer would be perfect from the start – but it’s none the less a good feature to have for the imperfect real world.
Case in point, we have encountered a floating point bug in Denver that has been traced back to the DCO, which under exceptional workloads causes Denver to overflow an internal register and trigger an SoC reset. Though this bug doesn’t lead to reliability problems in real world usage, it’s exactly the kind of issue that makes DCO updates valuable for NVIDIA as it gives them an opportunity to fix the bug. However at the same time NVIDIA has yet to take advantage of this opportunity, and as of the latest version of Android for the Nexus 9 it seems that this issue still occurs. So it remains to be seen if BSP updates will include DCO updates to improve performance and remove such bugs.








169 Comments
View All Comments
Mondozai - Wednesday, February 4, 2015 - link
No offence but how relevant is this review so many months after release?You guys dropped the ball on this one. We're also still waiting for the GTX 960 review.
What has happened to Anandtech...
LocutusEstBorg - Wednesday, February 4, 2015 - link
There's no Anand.nathanddrews - Wednesday, February 4, 2015 - link
That's the only change I've noticed.Morawka - Wednesday, February 4, 2015 - link
and no Brian Klugnathanddrews - Wednesday, February 4, 2015 - link
Yeah, but that was earlier.Ryan Smith - Wednesday, February 4, 2015 - link
"What has happened to Anandtech..."Nothing has happened to AnandTech. We're still here and working away at new articles.=)
However this article fell victim to bad timing. The short story is that I was out sick for almost 2 weeks in December, which meant this got backed up into the mess that is the holidays and CES.
As for how relevant it is, it is still Google's premiere large format tablet and the only shipping Denver device, both of which make it a very interesting product.
Jon Tseng - Wednesday, February 4, 2015 - link
It's fine to be late (although maybe not as late as the Razer Blade 2014 review!). Better to have late, differentiated content than early, commoditised content. Whether the review like's the colour of a tablet's trim is of limited interest for me; the details of Denver code-morphing are.Actually my worry is that under new ownership Anandtech might be pushed to go down the publish early/get click views route vs. the publish late/actually deliver something useful. Hopefully it won't come to this, but this is what historically happens... :-(
Operandi - Thursday, February 5, 2015 - link
Being there on day one is not a huge deal but its certainly not ok be as late as this review is or the still MIA 960 review. If you are going to be late you better be brining something new to the table to justify not being there in the same time frame as your peers. This is so laughably late its almost embarrassing to release it at all at this point.Tech journalism like most other markets is competitive and there are lots of other very competent publications out there competing for the same readers. Personally I've already gotten all the Nexus 9 information elsewhere so this review is of no value to me whatsoever. The same goes for the 960 review when/if that review ever shows up.
akdj - Wednesday, February 11, 2015 - link
Not sure where you've seen such an extensive write up and dissection of Denver, but I certainky haven't. Nor were the N9/6 widely available until the holidays were over. Like a month agoFor every 10,000,000 iPads produced, HTC is probably knocking out 10,000
Excellent review, write up and information about the 'other 64bit' option.
Taneli - Wednesday, February 4, 2015 - link
Timing is secondary for a deeply technical article like this here. You guys did exactly the right thing, reporting when the device was announced and waited for the review to be done before publishing. Also, having people out sick in a small team is something you really can't do that much about. I hope you're well now.The article itself was superb. Thanks for the read and keep up the good work.