Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM ESTCapacity: the New Arms Race
Some of the hottest software trends of today are Big Data and In Memory Business Analytics. Both applications benefit from fast processors, but even more importantly they are virtually unsatiable when it comes to RAM capacity. Another important area that's much closer to the daily work of many IT professionals is virtualization. As heavier applications are being virtualized, the typical amount of memory allocated to virtual machines has increased rapidly. As announced on the latest VMworld, vSphere 6 will now support Virtual machines that allocate up to 4TB (!!) of memory. The days where virtual machines were limited to only a fraction of "native" operating systems are behind us.
With the above developments, support for and development of high capacity DIMMs is crucial. Intel has been steadily improving the support for LRDIMMs (here's some additional information on LRDIMMs). The first Xeon E5-2600 had support for LRDIMMs but it only delivered higher capacity at the expense of lower bandwidth and higher latency. The memory controller of the Xeon E5-2600 v2 had several improvements specifically for LRDIMMs and as a result the latency and throughput tax was greatly reduced.
The advent of DDR4 has given the engineers of IDT the opportunity to give LRDIMMs a performance advantage instead of a disadvantage. By introducing data buffers close to the DRAM chips, they managed to reduce the I/O trace lengths tremendously. See the figure below.
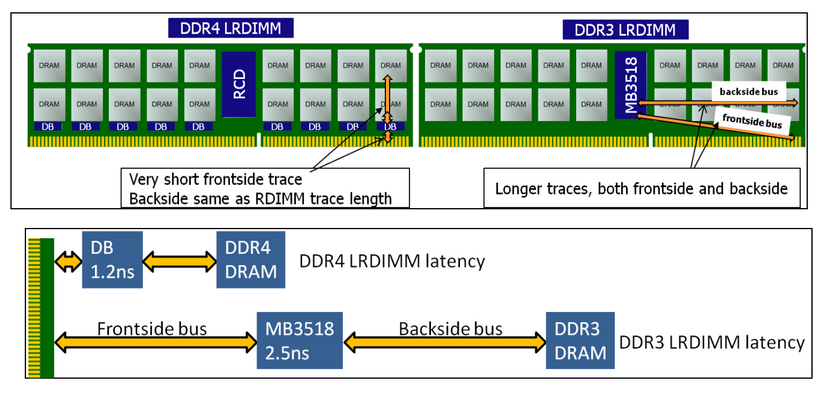
DDR4 and DDR3 LRDIMMs compared, image courtesy of IDT.
The latency overhead of the extra buffering is thus significantly lower on DDR4 LRDIMMs. In other words, compared to Registered DDR4 running at the same speed with 1 DPC (1 DIMM per channel), the latency overhead will be small. As soon as you start to use more DIMMs per channel, LRDIMMs actually offer lower latency as they can run at higher speeds.
Below you can see the evolution of LRDIMM support over the three generations of Xeon E5s. On the far right is the speed of DIMMs on Sandy Bridge EP, in the middle is Ivy Bridge EP, and on the left is the speed of DIMMs on the new Haswell EP Xeon.
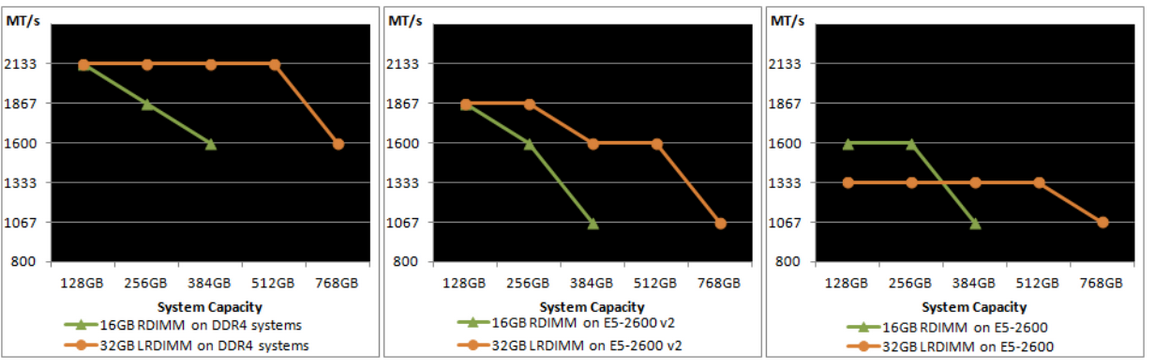
On Sandy Bridge EP (Xeon E5-2600), LRDIMMs were only clocked faster at three DPC. On Ivy Bridge EP (Xeon E5-2600 v2), the LRDIMMs were faster at two and three DPC. And on Haswell EP (Xeon E5-2600 v3), the bandwidth speed gap at two and three DPC has increased while the latency tax (not seen in the picture) has been reduced.

Samsung LRDIMM on top, RDIMM below. Notice the data buffers on the LRDIMM
Several sources tell us that LRDIMMs will be about 20%-25% more expensive. Our task then is to help you decide wether or not the investment is worth it. In this review, we will show some preliminary results.
The latency penalty has been reduced, but what about capacity? As you can see by the 4G marking in the photo above, the DIMMs used in our current servers are still using the mature 4Gbit DRAM chip technology. So currently, the Xeon E5-2600 v2 platform is limited to 384GB of registered DDR4 or 768GB of LRDIMMs. Quad-ranked RDIMMs, which were expensive, slow, and could only be used at 2DPC, are dead. The current 64GB LRDIMMs can be used at 3DPC, but they are Octal (!) ranks using quad-die-packages. As a result they are slow at 3DPC and power hungry.
But the future looks bright. At the end of this year, dual-ranked modules, such as the ones you can see above, will use 8Gb. This results in 64GB LRDIMMs and 32GB RDIMMs. That means the Xeon E5 platform will soon be able to address up to 1.5TB of physical RAM. In the second half of 2015, 128GB LRDIMMs should be available too, allowing up to 3TB of RAM.








85 Comments
View All Comments
martinpw - Monday, September 8, 2014 - link
There is a nice tool called i7z (can google it). You need to run it as root to get the live CPU clock display.kepstin - Monday, September 8, 2014 - link
Most Linux distributions provide a tool called "turbostat" which prints statistical summaries of real clock speeds and c state usage on Intel cpus.kepstin - Monday, September 8, 2014 - link
Note that if turbostat is missing or too old (doesn't support your cpu), you can build it yourself pretty quick - grab the latest linux kernel source, cd to tools/power/x86/turbostat, and type 'make'. It'll build the tool in the current directory.julianb - Monday, September 8, 2014 - link
Finally the e5-xxx v3s have arrived. I too can't wait for the Cinebench and 3DS Max benchmark results.Any idea if now that they are out the e5-xxxx v2s will drop down in price?
Or Intel doesn't do that...
MrSpadge - Tuesday, September 9, 2014 - link
Correct, Intel does not really lower prices of older CPUs. They just gradually phase out.tromp - Monday, September 8, 2014 - link
As an additional test of the latency of the DRAM subsystem, could you please run the "make speedup" scaling benchmark of my Cuckoo Cycle proof-of-work system at https://github.com/tromp/cuckoo ?That will show if 72 threads (2 cpus with 18 hyperthreaded cores) suffice to saturate the DRAM subsystem with random accesses.
-John
Hulk - Monday, September 8, 2014 - link
I know this is not the workload these parts are designed for, but just for kicks I'd love to see some media encoding/video editing apps tested. Just to see what this thing can do with a well coded mainstream application. Or to see where the apps fades out core-wise.Assimilator87 - Monday, September 8, 2014 - link
Someone benchmark F@H bigadv on these, stat!iwod - Tuesday, September 9, 2014 - link
I am looking forward to 16 Core Native Die, 14nm Broadwell Next year, and DDR4 is matured with much better pricing.Brutalizer - Tuesday, September 9, 2014 - link
Yawn, the new upcoming SPARC M7 cpu has 32 cores. SPARC has had 16 cores for ages. Since some generations back, the SPARC cores are able to dedicate all resources to one thread if need be. This way the SPARC core can have one very strong thread, or massive throughput (many threads). The SPARC M7 cpu is 10 billion transistors:http://www.enterprisetech.com/2014/08/13/oracle-cr...
and it will be 3-4x faster than the current SPARC M6 (12 cores, 96 threads) which holds several world records today. The largest SPARC M7 server will have 32-sockets, 1024 cores, 64TB RAM and 8.192 threads. One SPARC M7 cpu will be as fast as an entire Sunfire 25K. :)
The largest Xeon E5 server will top out at 4-sockets probably. I think the Xeon E7 cpus top out at 8-socket servers. So, if you need massive RAM (more than 10TB) and massive performance, you need to venture into Unix server territory, such as SPARC or POWER. Only they have 32-socket servers capable of reaching the highest performance.
Of course, the SGI Altix/UV2000 servers have 10.000s of cores and 100TBs of RAM, but they are clusters, like a tiny supercomputer. Only doing HPC number crunching workloads. You will never find these large Linux clusters run SAP Enterprise workloads, there are no such SAP benchmarks, because clusters suck at non HPC workloads.
-Clusters are typically serving one user who picks which workload to run for the next days. All SGI benchmarks are HPC, not a single Enterprise benchmark exist for instance SAP or other Enterprise systems. They serve one user.
-Large SMP servers with as many as 32 sockets (or even 64-sockets!!!) are typically serving thousands of users, running Enterprise business workloads, such as SAP. They serve thousands of users.