X-Gene 1, Atom C2000 and Xeon E3: Exploring the Scale-Out Server World
by Johan De Gelas on March 9, 2015 2:00 PM ESTMemory Subsystem: Latency
To measure latency, we use the open source TinyMemBench benchmark. The source was compiled for x86 with gcc 4.8.2 and optimization was set to "-O2". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests. To keep the graph readable we limited ourselves to the CPUs that were different.
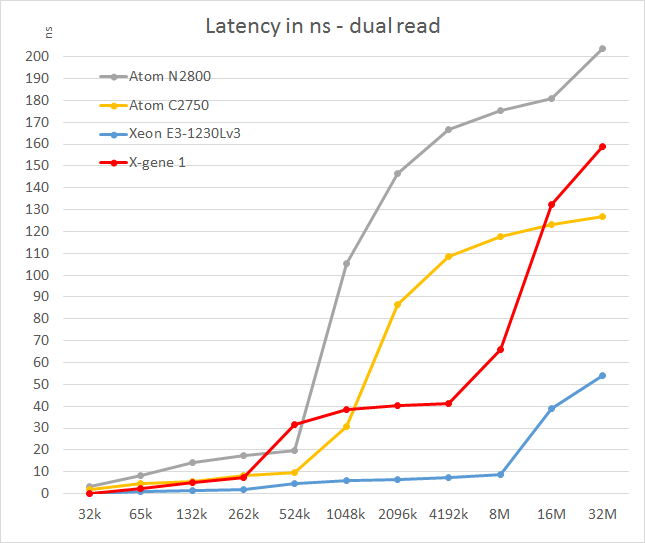
The X-Gene's L2 cache offers slightly better latency than the Atom C2750. That is not surprising as the L2 cache is four times smaller: 256KB vs 1024KB. Still, considering Intel has a lot of experience in building very fast L2 caches and the fact that AMD was never able to match Intel's capabilities, AppliedMicro deserves kudos.
However, the L3 cache seems pretty mediocre: latency tripled and then quadrupled! We are measuring 11-15 cycle latency for the L2 (single read) to 50-80 cycles (single read, up to 100 cycles in dual read) for the L3. Of course, on the C2750 it gets much worse beyond the 1MB mark as that chip has no L3 cache. Still, such a slow L3 cache will hamper performance in quite a few situations. The reason for this is probably that X-Gene links the cores and L3 cache via a coherent network switch instead of a low-latency ring (Intel).
In contrast to the above SoCs, the smart prefetchers of the Xeon E3 keep the latency in check, even at high block sizes. The X-Gene SoC however has the slowest memory controller of the modern SoCs once we go off-chip. Only the old Atom "Saltwell" is slower, where latency is an absolute disaster once the L2 cache (512KB) is not able to deliver the right cachelines.








47 Comments
View All Comments
JohanAnandtech - Tuesday, March 10, 2015 - link
Are you sure this is up to date? gcc tells me -march=native is not supported.JohanAnandtech - Tuesday, March 10, 2015 - link
Update. march=native does not work. I have tried -march=armv8-a but does not do much (it is probably the default). O3 makes the biggest difference. Omit it and you get 5.7 GB/s. With -O3, I am at 18 GB/s and more (stream m400)Alone-in-the-net - Tuesday, March 10, 2015 - link
Apologies. For AArch64 the only is "armv8-a", for intel, -march=native sets it to use the one for your CPU.https://gcc.gnu.org/onlinedocs/gcc-4.8.2/gcc/AArch...
https://gcc.gnu.org/onlinedocs/gcc-4.8.2/gcc/i386-...
From version 4.9.x and above of GCC, you can really start to add tuning for the CPU.
https://gcc.gnu.org/onlinedocs/gcc-4.9.2/gcc/AArch...
-mtune=name
Specify the name of the target processor for which GCC should tune the performance of the code. Permissible values for this option are: ‘generic’, ‘cortex-a53’, ‘cortex-a57’.
Additionally, this option can specify that GCC should tune the performance of the code for a big.LITTLE system. The only permissible value is ‘cortex-a57.cortex-a53’.
Where none of -mtune=, -mcpu= or -march= are specified, the code will be tuned to perform well across a range of target processors.
Alone-in-the-net - Tuesday, March 10, 2015 - link
Also support for the XGene1 as a compilation target is only from GCC5.https://gcc.gnu.org/gcc-5/changes.html
Support has been added for the following processors (GCC identifiers in parentheses): ARM Cortex-A72 (cortex-a72) and initial support for its big.LITTLE combination with the ARM Cortex-A53 (cortex-a72.cortex-a53), Cavium ThunderX (thunderx), Applied Micro X-Gene 1 (xgene1). The GCC identifiers can be used as arguments to the -mcpu or -mtune options, for example: -mcpu=xgene1
The_Assimilator - Monday, March 9, 2015 - link
So AMD, how's that bet on ARM you made looking now?extide - Monday, March 9, 2015 - link
Don't count them out yet. I really wish that intel didn't abandon ARM for the Atom, I bet they could come out with a sweet armv8 core if they had to, and on their process it would be sweet.BlueBlazer - Monday, March 9, 2015 - link
That AMD Opteron A1100 looking more like abandonware as more time passes on, and that was like 8 months ago. Until now not a single real world deployment nor was used in any of AMD's own SeaMicro servers. Currently available as development kit with a rather steep price tag.tuxRoller - Monday, March 9, 2015 - link
You REALLY should be using GCC 5. that includes many improvements for the armv8 isa. I'd suggest grabbing a nightly of Fedora 22, but Ubuntu 15.04 may be using gcc5 as well.Wilco1 - Monday, March 9, 2015 - link
Agreed, nobody doing anything on AArch64 should contemplate using GCC4.8. Even 4.9 is way out of date. GCC5.0 with latest GLIBC gives major speedups across the board.JohanAnandtech - Tuesday, March 10, 2015 - link
"Way out of date?" We tried out 4.9.2, which has been released on October 30th 2014. That is about 4 months old. https://www.gnu.org/software/gcc/releases.html. Latest version is 4.8.4, 5.0 has not even been released AFAIK.