X-Gene 1, Atom C2000 and Xeon E3: Exploring the Scale-Out Server World
by Johan De Gelas on March 9, 2015 2:00 PM ESTSingle-Threaded Integer Performance
The LZMA compression benchmark only measures a part of the performance of some real-world server applications (file server, backup, etc.). The reason why we keep using this benchmark is that it allows us to isolate the "hard to extract instruction level parallelism (ILP)" and "sensitive to memory parallelism and latency" integer performance. That is the kind of integer performance you need in most server applications.
This is more or less the worst-case scenario for "brawny" cores like Haswell or Power 8. Or in other words, it should be the best-case scenario for a less wide "energy optimized" ARM or Atom core, as the wide issue cores cannot achieve their full potential.
One more reason to test performance in this manner is that the 7-zip source code is available under the GNU LGPL license. That allows us to recompile the source code on every machine with the -O2 optimization with gcc 4.8.2.
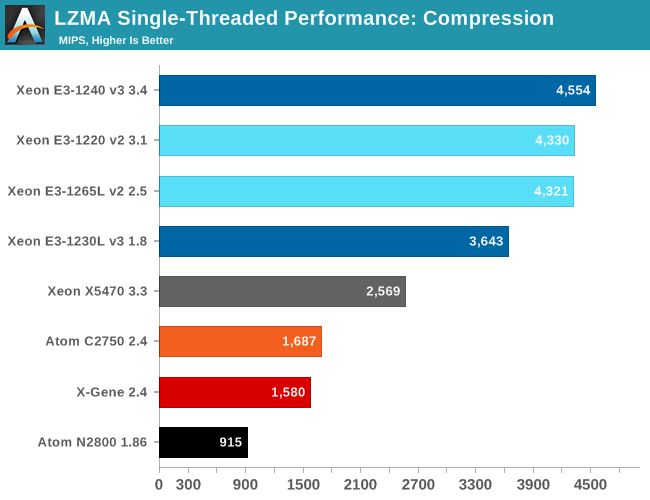
Despite the fact that the X-Gene has a 4-wide core, it is not able to outperform the dual issue Atom "Silvermont" core. Which is disappointing, considering that the AppliedMicro marketing claimed that the X-Gene would reach Xeon E5 levels. A 2.4GHz "Penryn/Harpertown" core reaches about 1860, which means that the X-Gene core still has a lot of catching up to do. It is nowhere near the performance levels of Ivy Bridge or Haswell.
Of course, the ARM ecosystem is still in its infancy. We tried out the new gcc 4.9.2, which has better support for AArch64. Compression became 6% faster, however decompression performance regressed by 4%....
Both the Xeon E3-1265L and E3-1220 v2 can boost to 3.5GHz, so they offer the same integer performance. The only reason that the Xeon E3-1240 v3 can offer higher performance is the slightly higher clock (3.8GHz Turbo Boost). The ultra efficient Xeon E3-1230L is capable of offering 80% of the performance of the 80W Xeon E3-1240. That is an excellent start.
As a long-time CPU enthusiast, you'll forgive me if I find the progress that Intel made from the 45nm "Harpertown" (X5470) to 22nm Xeon E3-1200 v3 pretty impressive. If we disable Turbo Boost, the Xeon E3-1240 at 3.4GHz achieves about 4200. This means that the Haswell architecture has an IPC that is no less than 63% better while running "IPC unfriendly" software.
The Xeon E3-1230L and Atom C2750 run at similar clock speeds in this single threaded task (2.8GHz vs 2.6GHz), but you can see how much difference a wide complex architecture makes. The Haswell Core is able to run about twice as many instructions in parallel as the Silvermont core. Meanwhile the Silvermont core is about 45% more efficient clock for clock than the old Saltwell core of the Atom N2800. The Haswell core result clearly shows that well designed wide architectures remain quite capable in "high ILP" (Instruction Level Parallelism) code.
Let's see how the chips compare in decompression. Decompression is an even lower IPC (Instructions Per Clock) workload, as it is pretty branch intensive and depends on the latencies of the multiply and shift instructions.
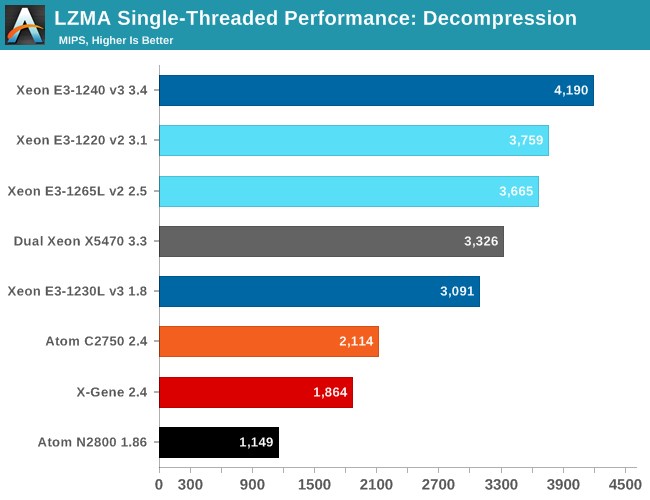
Decompression uses a rather exotic instruction mix and the progress made here is much smaller. The Haswell core is about 15% faster clock for clock than the old Harpertown core. Compared to the Silvermont core, the Haswell core is about 40% more efficient in this kind of software. The X-Gene core is about 10% slower than the Atom C2000.








47 Comments
View All Comments
gdansk - Monday, March 9, 2015 - link
xgene is not looking so great. Even if it is 50% more efficient as they promise they'll still be behind Atom.Samus - Monday, March 9, 2015 - link
HP Moonshot chassis are still *drool*Krysto - Monday, March 9, 2015 - link
The main problem with the non-Intel systems is not only that they use older processes compared to Intel, but that they use older processes even compared to the rest of the non-Intel chip industry. AMD is typically always behind 1 process node among non-Intel chip makers. If they'd at least use the cutting edge processes as they become available from non-Intel processes, maybe they'd stand a chance, especially now that the gap in process technologies is shrinking.Samus - Monday, March 9, 2015 - link
AMD simply isn't as bad as people continually make them out to be. Yes, they're "behind" Intel but it's all in the approach. We are talking about two engineering houses that share nothing in common but a cross licensing agreement. AMD has very competitive CPU's to Intel's i5's for nearly half the price, but yes, they use more power (at times 1/3 more.)But facts are facts: AMD is the second high-tech CPU manufacture in the world. Not Qualcomm, not Samsung. It's pretty obvious AMD engineering talent spreads more diversity than anyone other than Intel, and potentially superior to Intel on GPU design (although this has obviously been shifting over the years as Intel hires more "GPU talent.")
AMD in servers is a hard pill to swallow though. If purchasing based on price alone, it can be a compelling alternative, but for rack space or low-energy computing?
Taneli - Tuesday, March 10, 2015 - link
AMD doesn't even make it in top 10 semiconductor companies in sales. Qualcomm is three, Samsung semicondutors six and Intel almost ten times the size of AMD.Outside of the gaming consoles they are being completely overrun by competition.
owan - Tuesday, March 10, 2015 - link
I'm sorry, at one point I was an AMD fanboy, back when they actually deserved it based on their products, but you just sound like an apologist. Facts are the facts, FX processors aren't competitive with i5's in performance or power or performance/$ because they get smacked so hard they can't be cheap enough to make up for it. Their CPU designs are woefully out of date, their APU's are bandwidth starved and use way too much power to be useful in the one place they'd be great (mobile), and their lagging process tech means theres not much better coming on the horizon. I don't want to see them go, but at the rate ARM is eating up general computing share, it won't be long before AMD becomes completely irrelevant. It will be Intel vs. ARM and AMD will be an afterthought.xenol - Wednesday, March 11, 2015 - link
Qualcomm is used in pretty much used in most cell phones in the US to the point you'd think Qualcomm is the only SoC manufacturer. I'm pretty sure that's also how it looks in most of the other markets as Korea. Plus even if their SoCs aren't being used, they're modems are heavily used.If anything, Qualcomm is bigger than AMD. Or rather, Qualcomm is the Intel of the SoC market.
xenol - Wednesday, March 11, 2015 - link
[Response to myself since I can't edit]Qualcomm's next major competitor is Apple. But that's about it.
Also I meant to say other markets except Korea.
CajunArson - Monday, March 9, 2015 - link
Bear in mind that the Atom parts were commercially available in 2013, so they are by no means brand-new technology and the 14nm Atom upgrades will definitely help power efficiency even if raw performance doesn't jump a whole lot.Anandtech is also a bit behind the curve because Intel is about to release Xeon-D (8 Broadwell cores and integrated I/O in a 45 watt TDP, or lower), which is designed for exactly this type of workload and is going to massively improve performance in the low-power envelope sphere:
http://techreport.com/review/27928/intel-xeon-d-br...
SarahKerrigan - Monday, March 9, 2015 - link
14nm server Atom isn't coming.http://www.eetimes.com/document.asp?doc_id=1325955
"Atom will become a consumer only SoC."