An Introduction to Semiconductor Physics, Technology, and Industry
by Joshua Ho on October 9, 2014 3:00 PM EST- Posted in
- Semiconductors
- CMOS
- Physics
- Industry
- Technology
Introduction and Short Channel Effects
Unfortunately, it’s not as easy as simply driving resolution higher. Improving lithography is only one aspect, and as transistors get smaller and smaller previously insignificant issues become incredibly important ones. One of the biggest issues is leakage current.
I alluded to this earlier with the discussion of band structure, but electrons more closely resemble the models of quantum mechanics rather than classical mechanics. This leads to effects such as quantum tunneling, where electrons can pass through insulating layers as if there was nothing there to stop it.
While it was safe to ignore these effects at larger process nodes, the smaller we go the worse the problems get. There are five short channel effects that can be discussed, but the primary effect of interest in drain-induced barrier lowering, or DIBL. An example of the effect that DIBL has can be seen in the image below. What DIBL means is that because the channel length is so short, the voltage applied to the drain can affect the source because the drain itself acts as a capacitor due to the separation of charge.
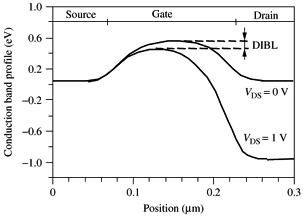
This capacitance from the drain means that the gate becomes less effective at controlling the flow of current through the gate because the drain is competing with the gate. As a result of this effect, there is a shift in the threshold voltage because the drain has made it easier for the inversion layer to be generated. When discussing threshold voltage, this generally refers to the point where current through the channel begins to increase exponentially with increases in gate voltage. In addition to this change in threshold voltage, there is a decrease in the subthreshold slope because the drain is causing a level of current to always flow through the channel. This means that more voltage has to be applied to the gate in order to generate the same increase in current flow in the channel.
It's possible to try and alleviate this issue by strongly doping the areas between the source and drain to eliminate the depletion region created. Unfortunately, another effect of this halo doping is that parasitic diode leakage increases, and due to the strong doping there is a greater scattering of electrons and lower electron mobility. In addition, because doping relies on an imperfect process, higher doping levels make the threshold voltage vary from transistor to transistor. This makes the operating voltages higher than necessary to accomodate for the variance in doping.
The end result is that performance falls off dramatically. However, there are multiple methods that can stave off these effects. These methods include straining silicon, silicon on insulator (SOI), high-k metal gate (HKMG), and FinFET.
Silicon On Insulator
Silicon On Insulator / Advanced Substrate News
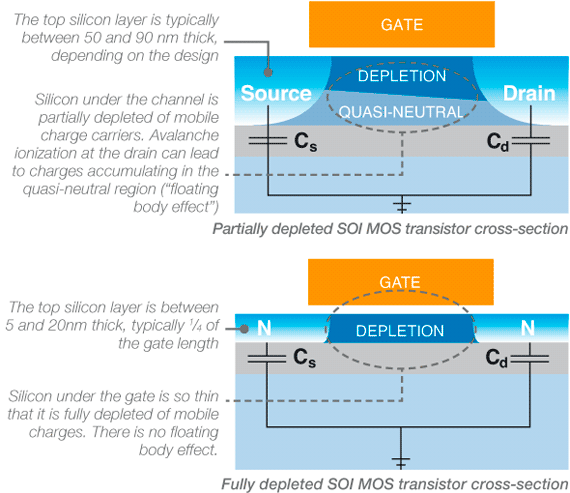
One of the first methods used in this area was SOI, which will be familiar to those that followed this site 13 years ago. In short, instead of the standard bulk silicon substrate that we’ve been showing in all of our MOSFET diagrams, an insulating layer is added just beneath the channel. This is an advantage in some ways, but a disadvantage in others.
First, parasitic capacitance is reduced. What we haven’t talked about until now is that by virtue of the depletion zone and charge on the source or drain, there is a separation of charge between the source or drain and the body. A planar capacitor is nothing more than two metal plates with a dielectric between the two, with a charge on one of the plates, so this is a form of capacitance. The issue with this capacitance is that once you add a resistor in series with the capacitor, you have an inherent delay in current. This is a classical RC circuit problem, and this reduces the rate at which the transistor can switch, which reduces performance. This delay is because the rise and fall of current from switching the transistor on and off is slower than if there was no capacitance. By adding a thick silicon oxide layer underneath the transistor, the distance is increased and therefore the capacitance decreases. This means that the time delay gated by RC decreases, which means clock speed increases.
The other problem is leakage far away from the gate. In recent process nodes, leakage has become a bigger and bigger problem. This is due to the short channel effects that we discussed before. While gate-induced drain leakage (GIDL) current is one issue that arises from smaller process nodes, it's inherently a different problem. While solving GIDL is done with HKMG, channel leakage far from the gate has been a persistent issue in recent process nodes, and it's something that scaling equivalent oxide thickness (EOT) at the gate won't solve. This is because the area far away from the gate cannot have its voltage pulled down by the gate. This goes back to the effect of DIBL that we previously discussed.
One of the first methods used to solve this problem was SOI, and by looking at a diagram of even partially depleted SOI (PD-SOI), it's clear why this is. SOI technology in general reduces the amount of silicon far away from the gate, and this in turn means that there is much less channel leakage. For PD-SOI though, because the bulk of the silicon isn't connected to a terminal the body "floats". This leads to something called the history effect, which means that the threshold voltage will change depending upon the previous voltages applied to the gate. This can also cause parasitic transistors to activate and cause leakage.
The logical conclusion to fix these issues is fully depleted SOI, which makes the channel thin enough that the body no longer floats, as it doesn't have a region where charge can accumulate one way or another. The gate can still create its inversion layer, but when the inversion layer isn't present the barrier for current is much stronger than before because all of the silicon in the channel is very close to the gate. This means that the leakage current in general is lower.
Unfortunately, SOI technology in general comes with higher cost and due to the insulating layer that the transistors are built on thermal dissipation of the transistors isn't as effective as it is on bulk processes. While AMD used to use SOI technology, they have since transitioned to bulk processes. FD-SOI is still a viable option, but for the most part SOI technology isn't found in VLSI chips like CPUs, GPUs, and other forms of digital logic. There are certainly niche cases where SOI dominates such as analog RF and radiation-hardened applications, but it seems that the foundry model makes SOI unpopular.
Straining Silicon
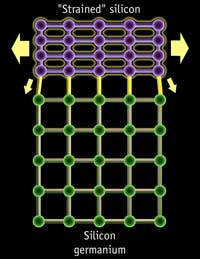
While SOI seems to have lost the popularity that it once had, other methods of improving transistor performance have become much more popular. For example, by putting silicon germanium (SiGe) or silicon carbide (SiC) in the source and drain, the silicon in the channel is stretched past its normal interatomic distance and reduces the effects of electrostatic forces. In other words, we get strained silicon. This increases the mobility of charge carriers in the channel, thus increasing drive current and overall transistor performance. There’s more than one way to achieve this, but the principle is ultimately the same. This kind of technology can be seen as early as 2003 with Intel's 90nm process.
High-k/Metal Gate
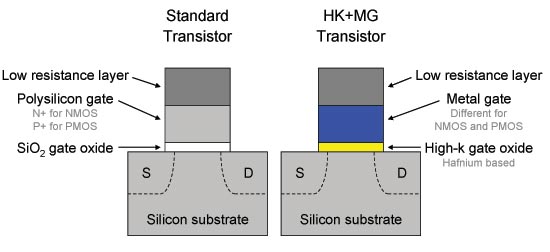
While straining silicon has been around since the 90nm node, the high-k metal gate has been critical for improving transistor performance at the 45nm node and below. When we first discussed the gate structure of a MOSFET, we talked about how a silicon dioxide layer is grown on top of a silicon substrate, which then has another polysilicon layer deposited on top of the silicon dioxide. Unfortunately, that hasn’t been the structure of the transistor gate for at least the past year for SoCs like the Snapdragon 800 and newer. HKMG has actually been around since 2007 in consumer devices with the launch of Intel’s Penryn CPUs.
The reason why HKMG is so important goes back to quantum mechanics. Those familiar with the equation for capacitance of a planar capacitor will know that reducing the distance between the two plates will increase capacitance. This means the field effect is stronger, which improves drive current and control over the channel. This control over the channel also increases the rate at which transistors switch. Unfortunately, at sufficiently small thicknesses, this all breaks down. Because electrons work probabilistically, we suddenly encounter cases where electrons begin tunneling through the insulator from the gate to the silicon channel. This causes significant leakage current through the gate to ground even when the gate isn’t being switched from one state to another, so we can no longer decrease thickness beyond a certain point.
One way to continue increasing gate capacitance while also decreasing leakage is to use a high-k dielectric, but this introduces a great deal of complexity in the manufacturing process compared to simple chemical vapor deposition of SiO2. The gate material itself can no longer be polysilicon, as it’s close enough to the inversion layer that it starts to become a depletion region. This causes issues in channel formation, so it becomes important to use a metal gate to improve performance. In addition to the poly depletion issue, a phenomenon known as Fermi level pinning occurs between the polysilicon/high-k interface. This effect dramatically raises the threshold voltage and decreases drive current.
FinFET
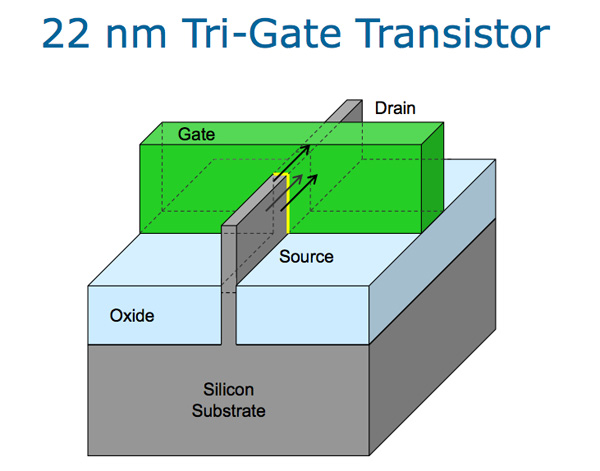
Unfortunately, once we get to 22 nanometers and below, short channel effects become even more significant. While we managed to decrease leakage and improve performance with HKMG, the gate still doesn’t have sufficient control over the channel because the gate keeps getting smaller relative to the substrate. The answer with the Tri-Gate transistor is to wrap the gate all around the channel that would form, dramatically reducing the amount of silicon far away from the gate. The resultant structure becomes like a fin, and due to the extremely thin channel the extent of the depletion region is determined by the physical structure rather than the applied bias to the terminals of the FET. This makes the transistor channel fully depleted as well, but this is merely an interesting side-effect, not a causative mechanism.
It's important to understand that this is why FinFET and FD-SOI are fully depleted technologies, but the key here is that the channel is now extremely thin so that the area far from the gate is eliminated. This means that the voltage and resultant capacitance of the gate should be able to overpower the effect of the drain's capacitance in all areas of the channel. The impact on performance is enormous.
As a result of this change, the off current is much lower than before as the effect of DIBL is reduced. This means that heavily doping the channel isn't necessary so variance in threshold voltages from one transistor to another is reduced. In addition, because of the larger inversion layer that can be generated and lower doping levels used in the channel, drive current is improved. This also means improved subthreshold swing can be achieved, so switching transistors on and off is even faster, which also improves performance. This is very much similar to the advantages that we see with FD-SOI, but it can be implemented on bulk silicon which reduces variable cost. FinFET and FD-SOI are just different ways of accomplishing the same goal, and share all the advantages of a thin channel.








{kind=link}
{kind=link}
77 Comments
View All Comments
danjw - Thursday, October 9, 2014 - link
I am wondering if we haven't already hit the limits of current technology. TSMC doesn't seem to be able to produce anything more powerful than a SOC for phones and tablets on their 20nm process. While Intel seems to think they will have 14nm desktop and notebook parts out in the second quarter of next year, I wonder if they really will. Right now all we have seen from them at 14nm is similar to what TSMC is able to do at 20nm.This really concerns me as far as technology stagnating until the next big thing comes along.
Homeles - Thursday, October 9, 2014 - link
There's no end in sight. About a year ago, perhaps a little earlier, the 7 or 5nm nodes were seen as the end of Moore's Law. Advancements have been made since then, though, and scaling past the 5nm node is very likely. 10nm's "recipe" is basically all finished at Intel at this point, with "all" that's left to do at this point being increasing the yields. EUV is making good progress, finally, and should be ready for insertion at Intel's 7nm node (if they skipped it for 10nm, which they likely did).14nm has been in production for quite some time now, with Broadwell first landing in tablets later this month. The chances that Broadwell won't make it to the desktop and notebook market around the middle of next year are essentially zero.
We're still also on schedule to have 450mm wafers introduced by the end of the decade, which would reduce costs by ~30%.
Even not looking at Intel, TSMC has millions of 20nm-based products on the market right now. 20nm is roughly twice as dense as its 28nm predecessor. It doesn't really make sense to be so skeptical of progress, given that the proof pudding has already been delivered.
danjw - Thursday, October 9, 2014 - link
All those 20nm products are not desktop or notebook CPUs or GPUs, which they lead AMD and Nvidia to believe they would be able to do. Intel is way behind its original estimates to get Broadwell out, and that just in table SOCs. Intel wanted badly to get Broadwell parts out for the new school year, then it was Christmas, now it is Q2 of 2015. Yes, I think there is plenty of reason to be skeptical.EMM81 - Monday, October 13, 2014 - link
Your facts are all incorrect...If you can produce an SOC you already have all of the capability to produce GPU's or CPU's since it has logic, SRAM and graphics components already. Broadwell parts are already in the hands of vendors NOW and are being sold this year and they are not SOC's they are low power full core chips. 14nm Broadwell chips are in no way equivalent to 20nm TSMC chips. A fab can use the additional capability of a new node in different ways. They can reduce density to make chips cheaper to make, increase performance, decrease power and all of these things will be done in different ratios depending on the product. You need to work on detailed reasoning and apples to apples comparisons.errorr - Thursday, October 9, 2014 - link
The problem is that the only real advancements are more expensive per transistor and I doubt they will change.The great thing about process shrinks is that it reduces the cost per transistor.
Also I doubt EUV will ever work. It has been almost ready and a couple years away for a decade. Tell me when you don't need MW levels of power to get usable light to a wafer and maybe I will consider it.
450mm wafers have also been just a couple years away for at least 15 years. I'll believe the 2020 hype when I actually see it.
The way to the next node is easy and everyone knows they can use triple patterning. Nobody wants that because of the expense is huge already and every single circuit would have to be redrawn due to limitations on the pokygons.
I don't know what's next but the only people expecting EUV to pan out are the people who have spent billions trying to make it work and failing.
ShieTar - Friday, October 10, 2014 - link
EUV is not "almost ready", it has been commercially available for 2 years now.http://www.zeiss.com/semiconductor-manufacturing-t...
Khenglish - Thursday, October 9, 2014 - link
The problem with smaller processes is not physically producing them. The problem is that they start getting slower than larger processes. This is due to 2 reasons.1. Narrower, more resistive interconnects.
2. Increase in channel doping levels due to not having enough dopant atoms to form a P-N junction as processes increase.
1. As process sizes shrink, so do interconnects. Resistance is dependent on cross sectional area and length of the wire. As you shrink a process, the cross sectional area drops at a squared rate, while length drops at a linear rate. The end result is that wires become linearly more resistive as the process shrinks. Keeping wire length down due to resistance is also a big reason why individual core transistor counts have not been going up significantly. The cores need to stay small to keep the wire length down. Repeaters to boost current drive ability on long wires has been around starting at around 90nm.
2. If you want a 10nm process, you probably have a gate length of 10nm. The volume of a 10nm cube is 10^-18 cm^-3. High doping levels are those above around 10^17 atoms per cm. If we take a high doping level of say 10^18 atoms per cm, then we have only one single dopant atom in the entire channel region of the transistor. This means that if you are one atom off, you lose a transistor, which is difficult not to do with over 1B transistors in a microprocessor. You can dope up to around 10^21 cm^-3, but then your electron and hole mobility are terrible. Mobility is directly proportional to how much current a transistor can push, so as mobility drops performance drops. See this link for what happens to mobility as dopant levels increase.
http://ecee.colorado.edu/~bart/book/mobility.gif
abufrejoval - Saturday, October 11, 2014 - link
From what I read the problem isn't as much phyiscal or technical feasability as economical viability: Moore's law was mostly about the ability to deliver more power at a lower price for the end consumer pushing the technology. Now the economical yields of process shrinks are diminishing to the point where further shrinks won't pay for themselves.DanNeely - Thursday, October 9, 2014 - link
If you're also interested in how simpler transistors are made; hack-a-day's hosted a video lecture from someone who was producing chips with a handful of transistors on them in her home lab a few years ago.http://hackaday.com/2010/03/10/jeri-makes-integrat...
anexanhume - Thursday, October 9, 2014 - link
Graphene isn't dead in the water. There are ways to create a bandgap, for example using bilayer graphene and introducing a gap via electric fields or doping.http://www-als.lbl.gov/index.php/contact/56-bilaye...
Then you can take advantage of its remarkable carrier mobility. Mass production remains a huge issue, and I also have concerns about its effect on living creatures and the environment. http://www.gizmag.com/graphene-bad-for-environment...