Intel Readying 15-core Xeon E7 v2
by Ian Cutress on February 11, 2014 1:32 PM EST
Reports from ISSCC are coming out that Intel is preparing to launch a 15-core Xeon CPU. The 15-core model was postulated before Ivy Bridge-E launch, along with 12-core and 10-core models – the latter two are currently on the market but Intel was rather silent on the 15-core SKU, presumably because it harder to manufacturer one with the right voltage characteristics. Releasing a 15-core SKU is a little odd, and one would assume is most likely a 16-core model with one of the cores disabled – based on Intel’s history I doubt this core will be able to be re-enabled should the silicon still work. I just received the official documents and the 15 core SKU is natively 15-core.
Information from the original source on the top end CPU is as follows:
- 4.31 billion transistors
- Will be in the Xeon E7 line-up, suited for 4P/8P systems (8 * 15 * 2 = 240 threads potential)
- 2.8 GHz Turbo Frequency (though the design will scale to 3.8 GHz)
- 150W TDP
- 40 PCIe lanes
Judging by the available information, it would seem that Intel are preparing a stack of ‘Ivytown’ processors along this design, and thus a range of Xeon E7 processors, from 1.4 GHz to 3.8 GHz, drawing between 40W and 150W, similar to the Xeon E5 v2 range.
Predictions have Ivytown to be announced next week, with these details being part of the ISSCC conference talks. In comparison to some of the other Xeon CPUs available, as well as the last generation:
| Intel Xeon Comparison | |||||
| Xeon E3-1280 v3 | Xeon E5-2687W | Xeon E5-2697 v2 | Xeon E7-8870 | Xeon E7-8890 v2 | |
| Socket | LGA1150 | LGA2011 | LGA2011 | LGA1567 | LGA2011 |
| Architecture | Haswell | Sandy Bridge-EP | Ivy Bridge-EP | Westmere-EX | Ivy Bridge-EX |
| Codename | Denlow | Romley | Romley | Boxboro | Brickland |
| Cores / Threads | 4 / 8 | 8 / 16 | 12 / 24 | 10 / 20 | 15 / 30 |
| CPU Speed | 3.6 GHz | 3.1 GHz | 2.7 GHz | 2.4 GHz | 2.8 GHz |
| CPU Turbo | 4.0 GHz | 3.8 GHz | 3.5 GHz | 2.8 GHz | 2.8 GHz |
| L3 Cache | 8 MB | 20 MB | 30 MB | 30 MB | 37.5 MB |
| TDP | 82 W | 150 W | 130 W | 130 W | 155 W |
| Memory | DDR3-1600 | DDR3-1600 | DDR3-1866 | DDR3-1600 | DDR3-1600 |
| DIMMs per Channel | 2 | 2 | 2 | 2 | 3 ? |
| Price at Intro | $612 | $1885 | $2614 | $4616 | >$5000 ? |
According to CPU-World, there are 8 members of the Xeon E7-8xxx v2 range planned, from 6 to 15 cores and 105W to 155W, along with some E7-4xxx v2 also featuring 15 core models, with 2.8 GHz being the top 15-core model speed at 155W.
All this is tentative until Intel makes a formal announcement, but there is clearly room at the high end. The tradeoff is always between core density and frequency, with the higher frequency models having lower core counts in order to offset power usage. If we get more information from ISSCC we will let you know.
Original Source: PCWorld
Update: Now I have time to study the document supplied by Intel for ISSCC, we can confirm the 15-core model with 37.5 MB L3 cache, using 22nm Hi-K metal-gate tri-gate 22nm CMOS with 9 metal layers. All the Ivytown processors will be harvested from a single die:
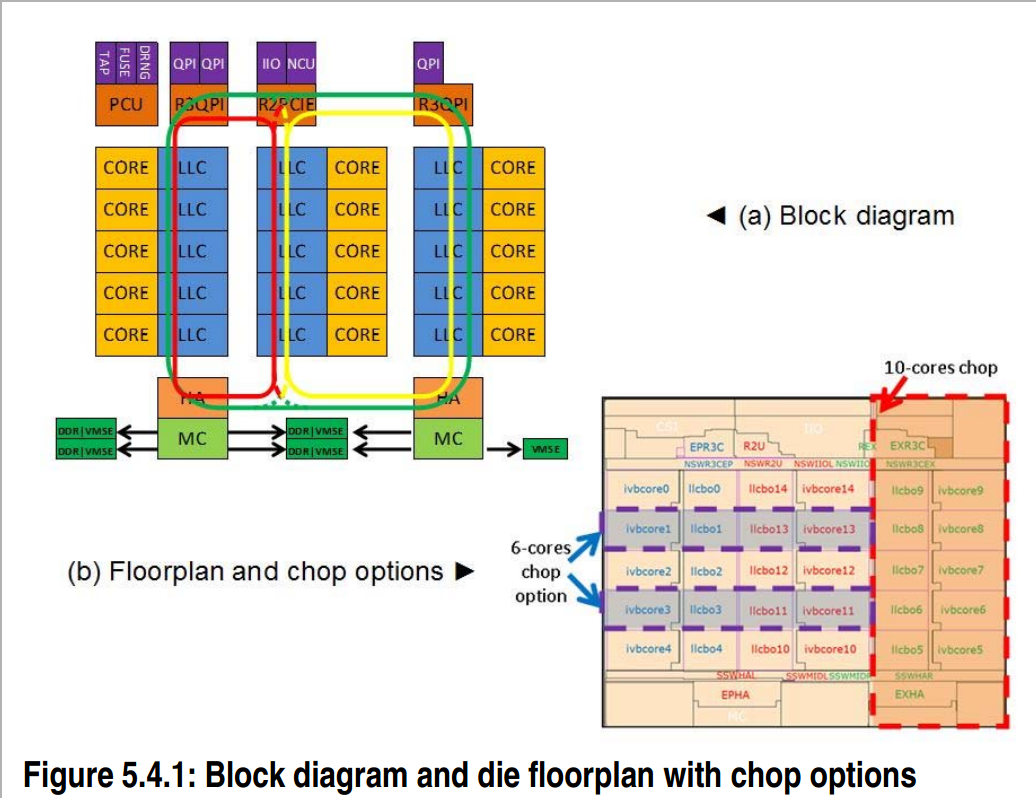

Ivytown Die Shot
The design itself is capable of 40W to 150W, with 1.4 GHz to 3.8 GHz speeds capable. The L3 cache has 15x 2.5MB slices, and data arrays use 0.108µm2 cells with in-line double-error-correction and triple-error-detection (DECTED) with variable latency. The CPU uses three clock domains as well as five voltage domains:
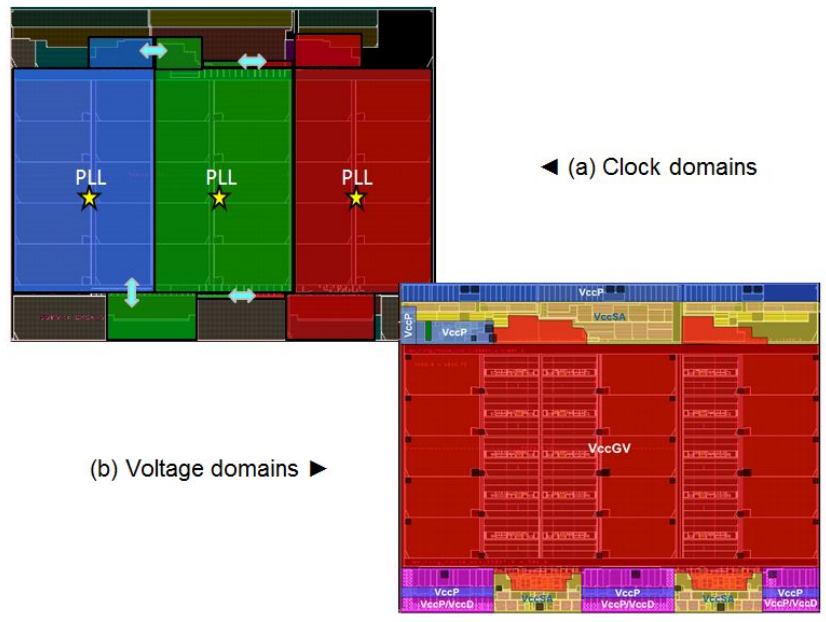
Level shifters are placed between the voltage domains, and the design uses lower-leakage transistors in non-timing-critical paths, acheving 63% use in the cors and 90% in non-core area. Overall, leakage is ~22% of the total power.
The CPUs are indeed LGA2011 (the shift from Westmere-EX, skipping over Sandy Bridge, should make it seem more plausible), and come in a 52.5x51.0mm package with four DDR3 channels. That would make the package 2677 mm2, similar to known Ivy Bridge-E Xeon CPUs.
CPU-World's list of Xeon E7 v2 processors come from, inter alia, this non-Intel document, listing the 105W+ models.








55 Comments
View All Comments
Kevin G - Wednesday, February 12, 2014 - link
I've been under the impression that Ivy Bridge-EX would still be using memory buffers, similar in concept to FB-DIMMs and the memory buffers used by Nehalem/Westmere-EX. Since much of the device signal portion is abstracted from the main die, using multiple memory technologies would be possible. I thought Ivy Bridge-EX's buffers would start off supporting DDR3 with DDR4 buffers appearing next year, possibly as a mid-cycle refresh before Haswell-EX appears.pixelstuff - Tuesday, February 11, 2014 - link
"suited for 4P/8P systems"What is an example of an 8P system? Who makes such a thing?
Ian Cutress - Tuesday, February 11, 2014 - link
SuperMicro and HP have made 8P behemoths based on Westmere-EX systems. I had some time testing SuperMicro's 4P, although I wouldn't mind looking at the new 8P if they make one.Kevin G - Tuesday, February 11, 2014 - link
IBM had the X3850 X5 that would scale up to 8 sockets. It was different as it was spread out between two chassis with an external QPI links joining them.IBM also exploited the external QPI links to offer raw memory expanders without the need for more CPU sockets.
darking - Tuesday, February 11, 2014 - link
Fujitsu Produces the RX900 too http://www.fujitsu.com/fts/products/computing/serv...mapesdhs - Tuesday, February 11, 2014 - link
At the extreme end, see: http://www.sgi.com/products/servers/uv/
Max configuration is a UV 2000 with 256 CPUs from the XEON E5 series
(max 2048 cores, 4096 threads), 64TB RAM in 4 racks. Note this is NOT
a cluster, it's a single combined system using shared memory NUMA. No
doubt SGI will adopt the E7 line with an arch update if necessary. The aim
is to eventually scale to the mid tens of thousands of CPUs single-image
(1/4 million cores or so).
8 processors is nothing. :D I have a "low end" 36-processor Onyx 3800 that's 14 years old...
Ian.
Kevin G - Wednesday, February 12, 2014 - link
SGI developed their own QPI glue logic to enable scaling beyond 4 socket with those chips.It does have a massive global address space which is nice from a programming standpoint, though to get there SGI had to go through several weird hoops. Reading up on the interconnect documentation, it is a novel tiered structure. The 64 TB of RAM limit is imposed by the Xeon E5's physical address space. Adding another tier allows for non-coherent addressing memory space upto 8 PB. A 64 TB region does appear to be fully cache coherent in that node and the socket limit for a node is 256..
MPI clustering techniques are used to scale at some point and SGI's interconnect chips provide some MPI acceleration to reduce CPU overhead and increase throughput. Neat stuff.
Brutalizer - Thursday, February 13, 2014 - link
@mapesdhs,Please stop spreading this misconception. The SGI UV2000 server with 256 sockets IS a cluster. Yes, it runs single image Linux over all nodes, but it is still a cluster.
First of all, there are (at least) two kinds of scalability. Scale out, which is a cluster - you just add another node and you have a more powerful cluster. They are very large, with 100s of cpus or even 1000s of cpus. All supercomputers are of this type, and they run embarassingly parallell workloads, number crunching HPC stuff. Typically, they run a small loop on each cpu, very cache intensive, doing some calculation over and over again. These servers are all HPC clusters. SGI UV2000 is of this type. Latency to far off cpus are very bad.
Scale up - which is a single fat huge server. They weigh 1000kg or so, and have up to 32 sockets, or even 64 sockets. They dont run parallell workloads, no. Typically they run Enterprise workloads, such as large databases. These workloads are branch intensive, and jumps wildly in the code, the code will not fit into the cache. These are of the SMP server type, running SMP workloads. SMP servers are not a cluster, they are a single fat server. Sure, they can use NUMA techniques, etc - but the latency to another cpu is very low (because they only have 32/64 cpus which is not far away), so in effect they are like true SMP server. There are not many hops to reach another cpu. SGI is not of this SMP server type. Examples of this type are IBM P795 (32 sockets), Oracle M6-32, Fujitu M4-10s (64 sockets), HP Integrity (64 sockets). They all run Unix OS: Solaris, IBM AIX, HP-UX. They all costs many millions of USD. Very very expensive, if you want 32 socket servers. For isntance, the IBM P595 32 socket server used for the old TPC-C record, costed 35million USD. One single frigging server costed 35 million. With 32 sockets. They are VERY expneisve. A cluster is cheap, just add some pcs and a fast switch.
Sure there are clustered databases running on clusters, but it is not the same thing as a SMP server. A HPC cluster can not replace a SMP server, as HPC servers can not handle branch intensive code - the worst case latency is so bad that performance would grind to a halt if HPC clusters tried Enterprise workloads.
In the x86 area, the largest SMP servers are 8 sockets servers, for instance Oracle M4800. Which is just a x86 pc sporting eight of these Ivy Bridge-EX cpus. There are no 32 socket x86 servers, no 64 sockets. But there are 256 sockets and above (i.e. clusters). So there is a huge gap between 8 sockets, the next is 256 sockets (SGI UV2000). Anything larger than 64 sockets, is a cluster.
For instance, the ScaleMP Linux server sporting 8192/16384 cores and gobs of TB or RAM, very similar to this SGI UV2000 cluster, is also a cluster. It uses a software hypervisor, that tricks the Linux kernel into believing it runs on a SMP server, instead of a HPC cluster:
http://www.theregister.co.uk/2011/09/20/scalemp_su...
"...Since its founding in 2003, ScaleMP has tried a different approach. Instead of using special ASICs and interconnection protocols to lash together multiple server modes together into a SMP shared memory system, ScaleMP cooked up a special software hypervisor layer, called vSMP, that rides atop the x64 processors, memory controllers, and I/O controllers in multiple server nodes....vSMP takes multiple physical servers and – using InfiniBand as a backplane interconnect – makes them look like a giant virtual SMP server with a shared memory space. vSMP has its limits....The vSMP hypervisor that glues systems together is not for every workload, but on workloads where there is a lot of message passing between server nodes – financial modeling, supercomputing, data analytics, and similar parallel workloads. Shai Fultheim, the company's founder and chief executive officer, says ScaleMP has over 300 customers now. "We focused on HPC as the low-hanging fruit."
Even SGI confesses their large Linux Altix and UV2000 servers, are clusters:
http://www.realworldtech.com/sgi-interview/6/
"The success of Altix systems in the high performance computing market are a very positive sign for both Linux and Itanium. Clearly, the popularity of large processor count Altix systems dispels any notions of whether Linux is a scalable OS for scientific applications. Linux is quite popular for HPC and will continue to remain so in the future,...However, scientific applications (HPC) have very different operating characteristics from commercial applications (SMP). Typically, much of the work in scientific code is done inside loops, whereas commercial applications, such as database or ERP software are far more branch intensive. This makes the memory hierarchy more important, particularly the latency to main memory. Whether Linux can scale well with a SMP workload is an open question. However, there is no doubt that with each passing month, the scalability in such environments will improve. Unfortunately, SGI has no plans to move into this SMP market, at this point in time"
All large Linux servers with 1000s of cores, are all clusters - and they are all used for HPC number crunching workloads. None are used for SMP workloads. The largest Linux SMP server are 8 socket servers. Anything larger than that, are Linux clusters. So, Linux scales up to 8 sockets in SMP servers. And on HPC clusters, Linux scales well up to 1000 of sockets. On SMP servers, Linux does not scale well. People have tried to compile Linux to the big Unix servers, for instance "Big Tux" server, which is the HP Integrity 64 socket Unix server - with terrible results. The cpu utilization was 40% or so, which means every other cpu were idle - under full load. Linux limit is somewhere around 8 sockets, it does not scale further.
That is the reason Linux does not venture into Enterprise arena. Enterprise which is very lucrative, needs huge 32 socket SMP servers, to run huge databases. And they shell out millions of USD on a single 32 socket server. If Linux could venture into that arena, Linux would. But there are no such big Linux SMP servers on the market. If you know of any, please link. I have never seen a Linux SMP server beyond 8-sockets. The Big Tux server, is a HP-UX server, so it is not a Linux server. It is a Linux experiment with bad performance and results.
So, these large Linux servers - are all clusters which is evidenced by they all are running HPC workloads. None are running SMP workloads. Please post a link, if you know of a counter example (you will not find any counter examples, trust me).
Kevin G - Friday, February 14, 2014 - link
Here is a counter example:http://www.sgi.com/pdfs/4192.pdf
It describes ASIC used in the SGI UV2000 and how it links everything together. In particular, differentiates how it is different from a cluster. The main points are as follows:
*Global memory space - every byte of memory is addressable directly from any CPU core.
*Cache coherent for systems up to 64 TB
*One instance of an operating system across the entire system without the need of a hypervisor (this is different from ScaleMP which has to have hypervisor running on each node)
I also would not cite a SGI interview from 2004 regarding technology introduced in 2012. A lot has changed in 8 years.
Similarly the "Big Tux" experiment used older Itanium chips that still used a FSB. The have since gone to the same QPI bus as modern Xeons. Scaling to higher socket counts is better on the Itanium side as it has more QPI links. Of course this is a kinda moot point as all enterprise Linux distributions have dropped Itanium support years ago.
Also the IBM p795 can run Linux across all 32 sockets/256 cores/1024 threads if you wanted. IBM's Red Book on the p795: http://www.redbooks.ibm.com/redpapers/pdfs/redp464...
Oracle is working on adding SPARC support to it s Oracle Linux distribution. This would be another source for a large coherent system capable of running a single Linux image. No other enterprise Linux distribution will be officially supported on Oracle's hardware.
Brutalizer - Saturday, February 15, 2014 - link
Where is the counter example? I am asking for an example of a Linux server with more than 8 sockets that runs SMP workloads, namely Enterprise stuff, such as big databases. The SGI server you link to, is a cluster. It says so in your link: they talk alot about "MPI", which is a library for doing HPC calculations on clusters. MPI is never used on SMP servers, it would be catastrophic to develop Oracle or DB2 database, using clustered techniques such as MPI.http://en.wikipedia.org/wiki/Message_Passing_Inter...
"MPI remains the dominant model used in High-Performance Computing today...MPI is not sanctioned by any major standards body; nevertheless, it has become a de facto standard for communication among processes that model a parallel program running on a distributed memory system. Actual distributed memory supercomputers such as computer clusters often run such programs."
So, there are no large SMP Linux servers. Sure, you can compile Linux to the IBM AIX P795 Unix server, but that would be nasty. The P795 is very very expensive 10s of millions of USD, and because Linux does not scale beyond 8 sockets on SMP servers, the performance would be bad too. It would be a bad idea to buy a very expensive Unix server, and install Linux instead.
Regarding the Oracle SPARC servers. Larry Ellison said officially when he bought Sun, that Linux is for low-end and Solaris for high end. Oracle is not offering any big Linux servers. All 32 socket servers are running Solaris.
Have you never thought of why the well researched and mature Unix vendors, have for decades stuck on 32/64 socket servers? They have have had 32 sockets Unix servers for decades, but not larger than that. Why not? Whereas the buggy Linux, has 8 socket servers or 10.000s of core servers, but nothing in between. There are no vendor manufacturing 32 socket Linux servers. You need to recompile Linux to 32 socket Unix servers with bad performance results. The answer is that Linux scales bad on SMP servers, 8 sockets being the maximum. And all larger Linux servers are all clusters, such as SGI UV2000 or the ScaleMP servers. Everybody wants to go into the Enterprise segment, which is very lucrative, but until someone will build 16 socket Linux servers, optimized for Linux, the Enterprise segment belongs to Unix and IBM Mainframes.
BTW, Oracle is developing a 96 socket SPARC server, designed to run huge databases, i.e. SMP workloads. You cant use MPI for Enterprise workloads, MPI is used for clustered HPC number crunching. Also, in 2015, Oracle will release an 16.384 threaded SPARC server with 64 TB of RAM. Both of them running Solaris of course.
Look at the picture are the bottom, here you see that for 32 sockets, each SPARC cpu can reach any other in at most 2-3 hops, which is very good. In effect, it is a SMP server, although it uses NUMA techniques.
http://www.theregister.co.uk/2013/08/28/oracle_spa...