The AMD Radeon R9 290X Review
by Ryan Smith on October 24, 2013 12:01 AM EST- Posted in
- GPUs
- AMD
- Radeon
- Hawaii
- Radeon 200
Compute
Jumping into pure compute performance, we’re going to have several new factors influencing the 290X as compared to the 280X. On the front end 290X/Hawaii has those 8 ACEs versus 280X/Tahiti’s 2 ACEs, potentially allowing 290X to queue up a lot more work and to keep itself better fed as a result; though in practice we don’t expect most workloads to be able to put the additional ACEs to good use at the moment. Meanwhile on the back end 290X has that 11% memory bandwidth boost and the 33% increase in L2 cache, which in compute workloads can be largely dedicated to said computational work. On the other hand 290X takes a hit to its double precision floating point (FP64) rate versus 280X, so in double precision scenarios it’s certainly going to enter with a larger handicap.
As always we'll start with our DirectCompute game example, Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. While DirectCompute is used in many games, this is one of the only games with a benchmark that can isolate the use of DirectCompute and its resulting performance.
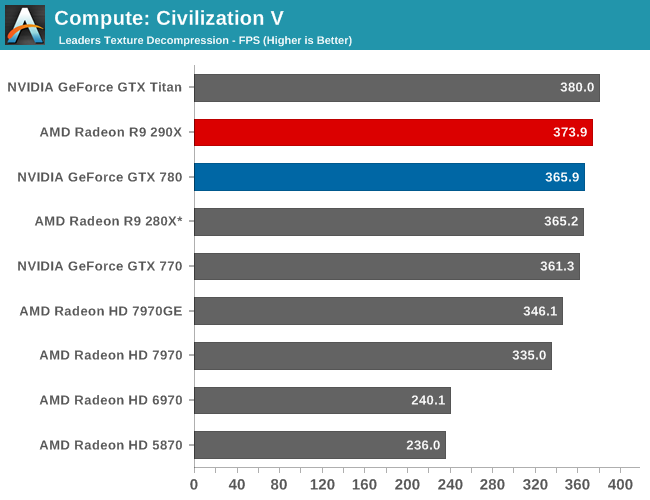
Unfortunately Civ V can’t tell us much of value, due to the fact that we’re running into CPU bottlenecks, not to mention increasingly absurd frame rates. In the 3 years since this game was released high-end CPUs are around 20% faster per core, whereas GPUs are easily 150% faster (if not more). As such the GPU portion of texture decoding has apparently started outpacing the CPU portion, though this is still an enlightening benchmark for anything less than a high-end video card.
For what it is worth, the 290X can edge out the GTX 780 here, only to fall to GTX Titan. But in these CPU limited scenarios the behavior at the very top can be increasingly inconsistent.
Our next benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
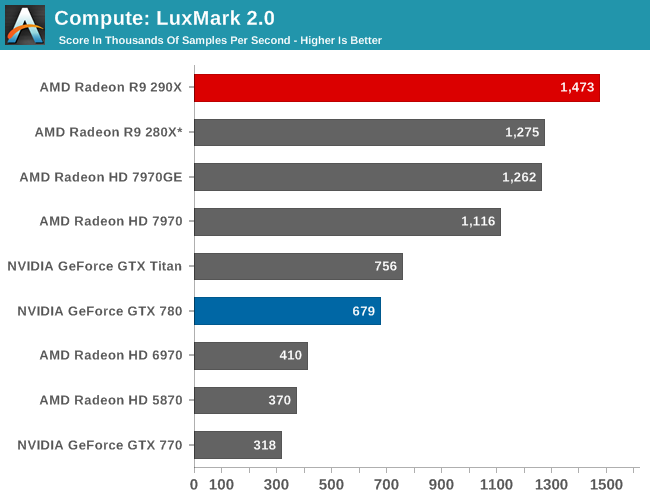
LuxMark by comparison is very simple and very scalable. 290X packs with it a significant increase in computational resources, so 290X picks up from where 280X left off and tops the chart for AMD once more. Titan is barely half as fast here, and GTX 780 falls back even further. Though the fact that scaling from the 280X to 290X is only 16% – a bit less than half of the increase in CUs – is surprising at first glance. Even with the relatively simplistic nature of the benchmark, it has shown signs in the past of craving memory bandwidth and certainly this seems to be one of those times. Feeding those CUs with new rays takes everything the 320GB/sec memory bus of the 290X can deliver, putting a cap on performance gains versus the 280X.
Our 3rd compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
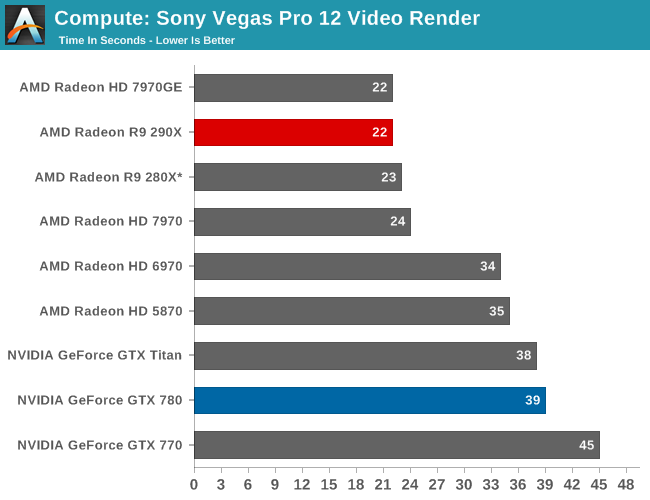
Vegas is another title where GPU performance gains are outpacing CPU performance gains, and as such earlier GPU offloading work has reached its limits and led to the program once again being CPU limited. It’s a shame GPUs have historically underdelivered on video encoding (as opposed to video rendering), as wringing significantly more out of Vegas will require getting rid of the next great CPU bottleneck.
Our 4th benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.
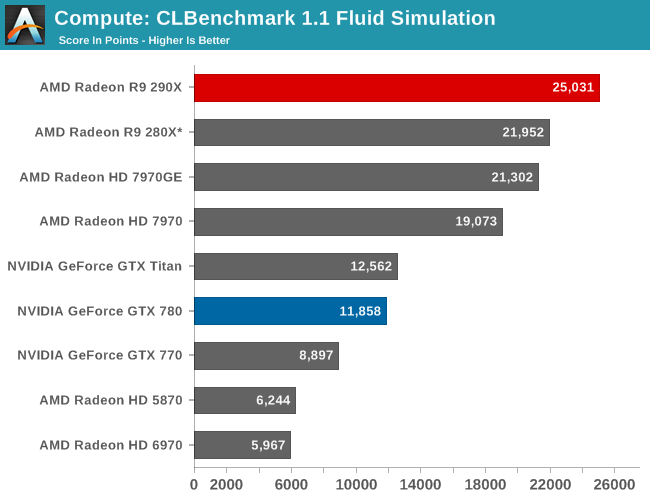

Curiously, the 290X’s performance advantage over 280X is unusual dependent on the specific sub-test. The fluid simulation scales decently enough with the additional CUs, but the computer vision benchmark is stuck in the mud as compared to the 280X. The fluid simulation is certainly closer than the vision benchmark towards being the type of stupidly parallel workload GPUs excel at, though that doesn’t fully explain the lack of scaling in computer vision. If nothing else it’s a good reminder of why professional compute workloads are typically profiled and optimized against specific target hardware, as it reduces these kinds of outcomes in complex, interconnected workloads.
Moving on, our 5th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, as Folding @ Home has moved exclusively to OpenCL this year with FAHCore 17.
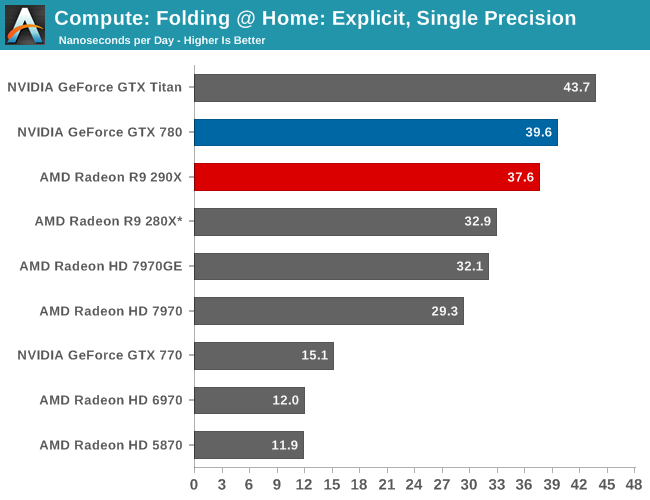

With FAHBench we’re not fully convinced that it knows how to best handle 290X/Hawaii as opposed to 280X/Tahiti. The scaling in single precision explicit is fairly good, but the performance regression in the water-free (and generally more GPU-limited) implicit simulation is unexpected. Consequently while the results are accurate for FAHCore 17, it’s hopefully something AMD and/or the FAH project can work out now that 290X has been released.
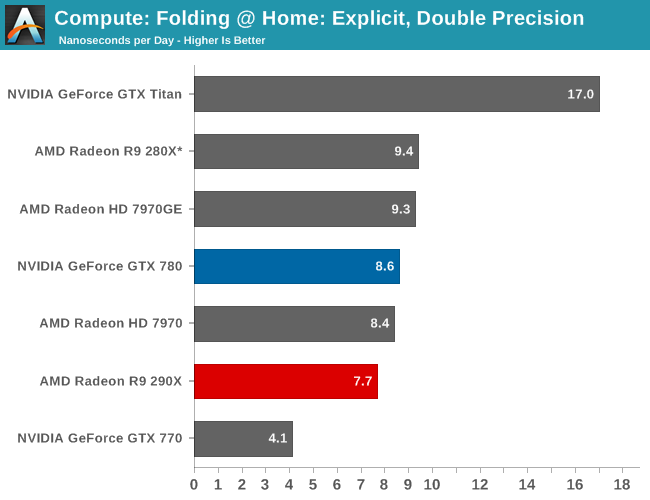
Meanwhile double precision performance also regresses, though here we have a good idea why. With DP performance on 290X being 1/8 FP32 as opposed to ¼ on 280X, this is a benchmark 290X can’t win. Though given the theoretical performance differences we should be expecting between the two video cards – 290X should have about 70% of the FP 64 performance of 280X – the fact that 290X is at 82% bodes well for AMD’s newest GPU. However there’s no getting around the fact that the 290X loses to GTX 780 here even though the GTX 780 is even more harshly capped, which given AMD’s traditional strength in OpenCL compute performance is going to be a let-down.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, as described in this previous article, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
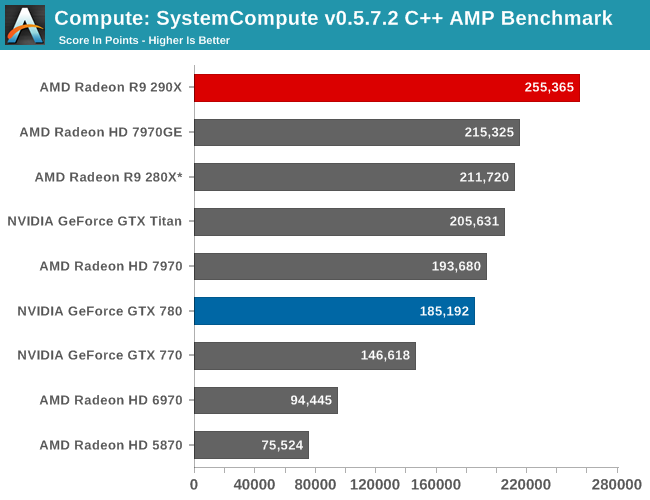
SystemCompute and the underlying C++ AMP environment scales relatively well with the additional CUs offered by 290X. Not only does the 290X easily surpass the GTX Titan and GTX 780 here, but it does so while also beating the 280X by 18%. Or to use AMD’s older GPUs as a point of comparison, we’re up to a 3.4x improvement over 5870, well above the improvement in CU density alone and another reminder of how AMD has really turned things around on the GPU compute side with GCN.








396 Comments
View All Comments
ninjaquick - Thursday, October 24, 2013 - link
so 4-5% faster than Titan?Drumsticks - Thursday, October 24, 2013 - link
If the 780Ti is $599, then that means the 780 should see at least a $150 (nearly 25%!) price drop, which is good with me.DMCalloway - Thursday, October 24, 2013 - link
So, what you are telling me is Nvidia is going to stop laughing- all- the- way- to-the-bank and price the 780ti for less than current 780 prices? Current 780 owners are going to get HOT and flood the market with used 780's.dragonsqrrl - Thursday, October 24, 2013 - link
Why is it that this is only ever the case when Nvidia performs a massive price drop? Nvidia price drop = early adopters getting screwed (even though 780 has been out for ~6 months now). AMD price drop = great value for enthusiasts, go AMD! ... lolz.Minion4Hire - Thursday, October 24, 2013 - link
Titan is a COMPUTE card. A poor man's (relatively speaking) proper compute solution. The fact that it is also a great gaming card is almost incidental. No one needs a 6GB frame buffer for gaming right now. The Titan comparisons are nearly meaningless.The "nearly" part is the unknown 780 TI. Nvidia could enable the remaining CUs on 780 to at least give the TI comparable performance to Titan. But who cares that Titan is $1000? It isn't really relevant.
ddriver - Thursday, October 24, 2013 - link
Even much cheaper radeons compeltely destroy the titan as well as every other nvidia gpu in compute, do not be fooled by a single, poorly implemented test, the nvidia architecture plainly sucks in double precision performance.ShieTar - Thursday, October 24, 2013 - link
Since "much cheaper" Radeons tend to deliver 1/16th DP performance, you seem to not really know what you are talking about. Go read up on a relevant benchmark suite on professional and compute cards, e.g. http://www.tomshardware.com/reviews/best-workstati... The only tasks where AMD cards shine are those implemented in OpenCL.ddriver - Thursday, October 24, 2013 - link
"Much cheaper" relative to the price of the titan, not entry level radeons... You clutched onto a straw and drowned...OpenCL is THE open and portable industry standard for parallel computing, did you expect radeons to shine at .. CUDA workloads LOL, I'd say OpenCL performance is all I really need, it has been a while since I played or cared about games.
Pontius - Tuesday, October 29, 2013 - link
I'm in the same boat as you ddriver, all I care about is OpenCL in these articles. I go straight to that section usually =)TheJian - Friday, October 25, 2013 - link
You're neglecting the fact that everything you can do professionally in openCL you can already do faster in cuda. Cuda is taught in 600+ universities for a reason. It is in over 200 pro apps and has been funded for 7+yrs unlike opencl which is funded by a broke company hoping people will catch on one day :) Anandtech refuses to show cuda (gee they do have an AMD portal after all...LOL) but it exists and is ultra fast. You really can't name a pro app that doesn't have direct support or support via plugin for Cuda. And if you're buying NV and running opencl instead of cuda (like anand shows calling it compute crap) you're an idiot. Why don't they run Premiere instead of Sony crap for video editing? Because Cuda works great for years in it. Same with Photoshop etc...You didn't look at folding@home DP benchmark here in this review either I guess. 2.5x faster than 290x. As you can see it depends on what you do and the app you use. I consider F@H stupid use of electricity but that's just me...LOL. Find anything where OpenCL (or any AMD stuff, directx, opengl) beats CUDA. Compute doesn't just mean OpenCL, it means CUDA too! Dumb sites just push openCL because its OPEN...LOL. People making money use CUDA and generally buy quadro or tesla (they own 90% of the market for a reason, or people would just buy radeons right?).
http://www.anandtech.com/show/7457/the-radeon-r9-2...
DP in F@H here. Titan sort of wins right? 2.5x or so over 290x :) It's comic both here and toms uses a bunch of junk synthetic crap (bitmining, Asics do that now, basemark junk, F@H, etc) to show how good AMD is, but forget you can do real work with Cuda (heck even bitmining can be done with cuda)
When you say compute, I think CUDA, not opencl on NV. As soon as you toss in Cuda the compute story changes completely. Unfortunately even Toms refuses to pit OpenCL vs. Cuda just like here at anandtech (but that's because both love OpenCL and hate proprietary stuff). But at least they show you in ShieTar's link (which craps out, remove the . at the end of the link) that Titan kills even the top quadro cards (it's a Tesla remember for $1500 off). It's 2x+ faster than quadro's in almost everything they tested. So yeah, Titan is very worth it for people who do PRO stuff AND game.
http://www.tomshardware.com/reviews/best-workstati...
For the lazy, fixed ShieTar's link.
All these sites need to do is fire up 3dsmax, cinema4d, Blender, adobe (pick your app, After Effect, Premiere, Photoshop) and pit Cuda vs. OpenCL. Just pick an opencl plugin for AMD (luxrender) and Octane/furryball etc for NV then run the tests. Does AMD pay all these sites to NOT do this? I comment and ask on every workstation/vid card article etc at toms, they never respond...LOL. They run pure cuda, then pure opencl, but act like they never meet. They run crap like basemark for photo/video editing opencl junk (you can't make money on that), instead of running adobe and choosing opencl(or directx/opengl) for AMD and Cuda for NV. Anandtech runs Sony Vegas which a quick google shows has tons of problems with NV. Heck pit Sony/AMD vs. Adobe/NV. You can run the same tests in both on video, though it would be better to just use adobe for both but they won't do that until AMD gets done optimizing for the next rev...ROFL. Can't show AMD in a bad light here...LOL. OpenCL sucks compared to Cuda (proprietary or not...just the truth).