The Radeon R9 280X Review: Feat. Asus & XFX - Meet The Radeon 200 Series
by Ryan Smith on October 8, 2013 12:01 AM ESTCompute
Jumping into compute, as with our synthetic benchmarks we aren’t expecting too much new here. Outside of DirectCompute GK104 is generally a poor compute GPU, which makes everything very easy for the Tahiti based 280X. At the same time compute is still a secondary function for these products, so while important the price cuts that go with the 280X are not quite as meaningful here.
As always we'll start with our DirectCompute game example, Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. While DirectCompute is used in many games, this is one of the only games with a benchmark that can isolate the use of DirectCompute and its resulting performance.
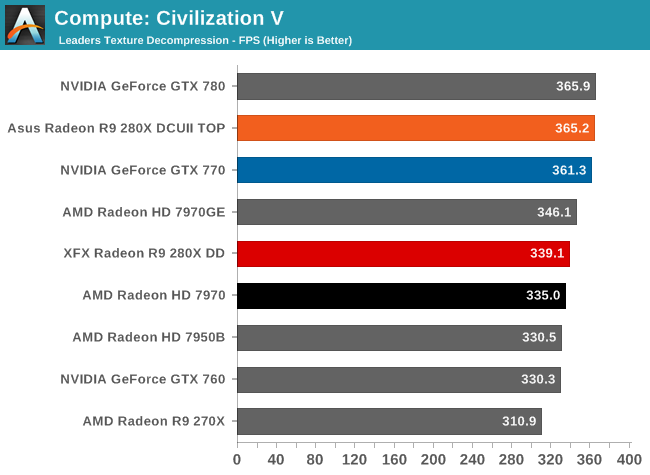
With Civilization V we’re finding that virtually every high-end GPU is running into the same bottleneck. We’ve reached the point where even GPU texture compression is CPU-bound.
Our next benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
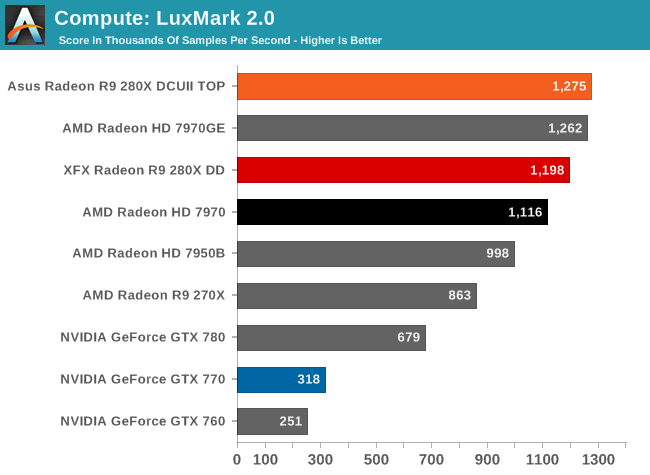
AMD simply rules the roost when it comes to LuxMark, so the only thing close to 280X here are other Tahiti parts.
Our 3rd compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
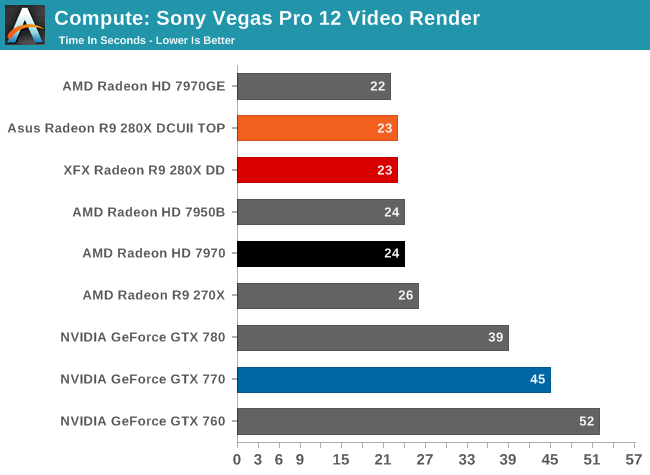
Again AMD’s strong compute performance shines through, with 280X easily topping the chart.
Our 4th benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.


Despite the significant differences in these two workloads, in both cases 280X comes out easily on top.
Moving on, our 5th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, as Folding @ Home has moved exclusively to OpenCL this year with FAHCore 17.



Depending on the mode and the precision, we can have wildly different results. The 280X does well in FP32 explicit, for example, but in implicit mode the 280X is now caught between the GTX 770 and GTX 760. But if we move to double precision then AMD’s native ¼ FP64 execution speed gives them a significant advantage here.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, as described in this previous article, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.

Although not by any means a blowout, yet again the 280X vies for the top here. When it comes to compute, the Tahiti based 280X is generally unopposed by anything in its price range.








151 Comments
View All Comments
neymar32 - Tuesday, February 4, 2014 - link
You can check out a cool video review for this card if you'd like to:http://youtu.be/4MIK5NNN0yo